







Java核心内容介绍
java核心内容:
1.数据结构
2.集合
3.泛型
4.反射
5.注解
一.数据结构
1.数组
char[] chars = {'H','E','L','L','O'};
char[] cs1 = new char[5];
cs1[0] = 'G';
图地址: https://www.jianguoyun.com/p/DWcu5KAQw7TEChi8pMAEIAA
总结:
1.内存地址连续,使用之前必须要指定数组长度
2.可以通过访问下标的方式访问成员,查询效率高
3.增删比较慢 会给系统带来增删消耗[保证数组下标越界的问题,需要动态扩容]
2.链表
单向链表和双向链表
我们主要研究的是双向链表
图地址: https://www.jianguoyun.com/p/DSQZORYQw7TEChi9pMAEIAA
总结:
1.灵活的空间要求 不需要连续的内存空间
2.不支持下标的方式进行数据的访问 支持顺序数据检索
3.针对增删效率会高一些 只和操作节点的前后节点有关系 无需移动元素
LinkedList 是一个双向链表的结构
private static class Node<E> {
E item; // 节点的元素
Node<E> next; // 下一个节点
Node<E> prev; // 上一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
3.树
二叉树:
图片地址: https://www.jianguoyun.com/p/DRNMmXMQw7TEChj1pMAEIAA

二叉树的特点:
1.某节点的左子树节点仅包含小于该节点的值
2.某节点的右子树节点仅包含大于该节点的值
3.左右子树也必须是二叉查找树
4.顺序排列
通俗点讲就是两边都是二叉树且顺序排列,右边大于左边,如果新插进来一个,跟节点对比一下,比他大就往右边去,比它小就往左边去。
红黑树:
红黑树,Red-Black Tree [RBT]是一个自平衡(不是绝对)的二叉查找树,树的节点满足如下的规则:
1.每个节点要么是红色,要么是黑色
2.根节点必须是黑色
3.每个叶子节点是黑色
4.每个红色节点的两个子节点必须是黑色
5.任意节点到每个叶子节点的路径包含相同数量的黑节点

其实更贴切的叫法应该是黑平衡二叉树:
1.recolor 重新标志节点为红色或者黑色
2.ratation 通过旋转的方式 使树达到平衡 是树能达到平衡的关键
红黑树能实现自平衡,靠的是什么呢???? 三种操作左旋 右旋 和 变色
左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,
右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,
左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变。变色:结点的颜色由红变黑或由黑变红。
红黑树练习小网站: https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
结合下面的这张图就能很好的理解左旋和右旋了
(tips: 1.就是说 如果是在一条线上的话 那么就是对其进行左旋或者右旋就行了,但是如果不是在一条线上的话,那么就需要的先将对应的两个去进行一个旋转,旋转到一条线上就可以按照上面一条线的方式去对其进行旋转了。2.简单的总结一下,就是说如果是在一条线上的话,那么就是直接的对其进行旋转就可以了,如果是一个三角,没在一条线上的话,那么就要先将其对齐到一条线上,然后在对其进行旋转,达到平衡二叉树的状态。)

二.集合简介
Collection接口:
类似于数组,其实本质上就是数组,不过其对数组做了一个动态的扩容。数组的长度是不变的,集合的长度是没有限制的,相对于数组来说更加的灵活。

List集合:
1.ArrayList源码剖析:
/**
* Default initial capacity.
默认的数组长度
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
空数组的默认值
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
无参狗仔的初始值
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
集合中存储数组的 数组对象
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
集合中元素的个数
*/
private int size;
初始操作:
无参构造:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
// this.elementData = {}
}
有参构造:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//初始长度大于0 创建一个长度为 initialCapacity 的数组 就是创建一个指定大小的数组
this.elementData = new Object[ initialCapacity];
} else if (initialCapacity == 0) {
//如果为0的话 那么就将初始值赋值给这个数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
add操作:
第一次添加:
public boolean add(E e) {
//确定容量 就是去做动态扩容的 size初始值是0
ensureCapacityInternal(size + 1); // Increments modCount!!
//将要添加的元素 添加到数组中
elementData[size++] = e;
return true;
}
上面扩容的方法: ensureCapacityInternal 方法
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
上面的 calculateCapacity 方法:
/**
初始值:
elementData {}
minCapacity 1
*/
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//elementData 如果这个值是空的话
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//那么返回DEFAULT_CAPACITY 和 minCapacity这两个值中的最大值 DEFAULT_CAPACITY的默认值 是10
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//如果传递过来的 elementData 有值的话 那么直接对其进行返回就可以了
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
//操作次数的自增
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
上面的grow()方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; //这个值是0
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 0 - 10 < 0 true
if (newCapacity - minCapacity < 0)
//将minCapacity值赋值newCapacity
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//创建一个长度为newCapacity(默认没有初始化之前是10) 将我们的elementData复制到这个数组中
elementData = Arrays.copyOf(elementData, newCapacity);
}
第二次添加:
elementData = {"樱木花道",,,,,,,,,};
size = 1;
public boolean add(E e) {
// 2
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e; // elementData[1] = 2 size = 2
return true;
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 因为现在的值是2 所以是直接返回的
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code 2 - 10 现在这个条件是不成立的 所以就是直接返回了
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
第十一次添加:
elementData = {1,2,3,4,5,6,7,8,9,10};
size = 10;
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
// ensureExplicitCapacity(11)
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 11 - 10 > 0
if (minCapacity - elementData.length > 0)
//这个就是扩容方法
grow(minCapacity);
}
关键的方法来了: 扩容的方法 grow()
private void grow(int minCapacity) { // 11
// 10(记录原来的容量)
int oldCapacity = elementData.length;
// 15 newCapacity 是oldCapacity的1.5倍
// 计算新的容量 新容量为 老容量的1.5倍 第一次为0
//这段代码的意思是 将oldCapacity向右移动一位 10的二进制是1010 向右移动一位就是0101 也就是15
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 15 - 11 > 0 不满足
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// {1,2,3,4,5,6,7,8,9,10} -- > {1,2,3,4,5,6,7,8,9,10,,,,,}
// 把原来数组中的内容拷贝到一个新建的指定容量为newCapacity的数组中,扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
get操作:
public E get(int index) {
//检查数组的下标记 下面的代码块
rangeCheck(index);
//通过下标返回这个数组中对应的元素
return elementData(index);
}
private void rangeCheck(int index) {
if (index >= size)
//如果超过了当前的size 那么就抛出去一个异常
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
set操作:
public E set(int index, E element) {
//同样的 检查下标
rangeCheck(index);
//获取下标原来的值
E oldValue = elementData(index);
//将传递过来的值赋值给数组中对应的索引的值
elementData[index] = element;
return oldValue;
}
remove操作:
参考博客: http://www.proyy.com/6967540513981333511.html
其实简单来说 remove方法就是把要删除元素后面的元素整体往前挪一个下标的位置,覆盖掉要被移除的元素。
public E remove(int index) {
//检查数组下标
rangeCheck(index);
modCount++;
//获取移动的元素
E oldValue = elementData(index);
//获取要移动的元素的个数
int numMoved = size - index - 1;
if (numMoved > 0)
// 源数组 开始下标 目标数组 开始下标 长度
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将最后一个元素置为null 让GC垃圾回收
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
举栗子:
假设当前index = 1
elementData: {1,2,3,4,5}; 源数组
Index + 1 = 2 源数组的下标 现在源数组是 {3,4,5}
elementData: {1,2,3,4,5}; 目标数组
index:1 目标数组的下标
numMoved:3 移动的位数
移动之后的结果:{1,3,4,5,5};
通过将末尾的元素设置为null,来解决这多出来的元素问题,同时让GC收集器来回收这个元素就可以了.
Fail-Fast机制:
翻译过来就是快速失败机制,是java集合中的一种错误检测机制。当在迭代集合的过程中,该集合在结构上发生改变的时候,就有可能发生 fail-fast,即抛出 ConcurrentModificationException 异常。
发生时机:
那什么时候会发生fail-fast呢???
单线程环境下:
遍历一个集合过程中,集合结构被修改。注意,listIterator.remove()方法修改集合结构不会抛出这个异常。
多线程环境下:
当一个线程遍历集合的过程中,而另一个线程对集合结构进行了修改。
举个栗子:
单线程:
import java.util.ListIterator;
import java.util.Vector;
public class Test {
/**
* 单线程测试
*/
@org.junit.Test
public void test() {
try {
// 测试迭代器的remove方法修改集合结构会不会触发checkForComodification异常
ItrRemoveTest();
System.out.println("----分割线----");
// 测试集合的remove方法修改集合结构会不会触发checkForComodification异常
ListRemoveTest();
} catch (Exception e) {
e.printStackTrace();
}
}
// 测试迭代器的remove方法修改集合结构会不会触发checkForComodification异常
private void ItrRemoveTest() {
Vector list = new Vector<>();
list.add("1");
list.add("2");
list.add("3");
ListIterator itr = list.listIterator();
while (itr.hasNext()) {
System.out.println(itr.next());
//迭代器的remove方法修改集合结构
itr.remove();
}
}
// 测试集合的remove方法修改集合结构会不会触发checkForComodification异常
private void ListRemoveTest() {
Vector list = new Vector<>();
list.add("1");
list.add("2");
list.add("3");
ListIterator itr = list.listIterator();
while (itr.hasNext()) {
System.out.println(itr.next());
//集合的remove方法修改集合结构
list.remove("3");
}
}
}
多线程:
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
import java.util.Vector;
public class Test {
private static List<String> list = new Vector<String>();
/**
* 多线程情况测试
*/
@org.junit.Test
public void test2() {
list.add("1");
list.add("2");
list.add("3");
// 同时启动两个线程对list进行操作!
new ErgodicThread().start();
new ModifyThread().start();
}
/**
* 遍历集合的线程
*/
private static class ErgodicThread extends Thread {
public void run() {
int i = 0;
while (i < 10) {
printAll();
i++;
}
}
}
/**
* 修改集合的线程
*/
private static class ModifyThread extends Thread {
public void run() {
list.add(String.valueOf("5"));
}
}
/**
* 遍历集合
*/
private static void printAll() {
Iterator iter = list.iterator();
while (iter.hasNext()) {
System.out.print((String) iter.next() + ", ");
}
System.out.println();
}
}
参考博客:
https://blog.csdn.net/CSDN_SAVIOR/article/details/122321461
https://blog.csdn.net/OoooTF/article/details/118015894
解决方法:
使用java.util.concurrent包下的类去取代java.util包下的类。所以,本例中只需要将Vector替换成java.util.concurrent包下对应的类即可。比如使用 CopyOnWriteArrayList 代替 ArrayList,CopyOnWriteArrayList 在使用上和 ArrayList 是一样的。但是它在进行 add 或 remove 操作时,并不是在原数组上修改,而是将原数组拷贝一份,在新数组上进行修改,待完成后,才将旧数组的引用指向新数组。所以对于 CopyOnWriteArrayList 来说,在迭代过程中并不会发生 fail-fast 现象。
2.LinkedList源码剖析:

LinkedList是通过双向链表去实现的,所以具有双向链表的优缺点。既然是双向链表,那么他的顺序访问效率会非常高,但是同时随机访问的效率也会很低。它包含一个非常重要的内部类: Node。
private static class Node<E> {
E item; //节点的元素
Node<E> next; //下一个节点
Node<E> prev; //上一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
get方法:
本质上还是遍历链表中的数据
Node<E> node(int index) {
// assert isElementIndex(index);
// index 和 长度的一半比较
if (index < (size >> 1)) {
Node<E> x = first;
// 从头开始循环
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
// 从尾部开始循环
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
set方法:
public E set(int index, E element) {
checkElementIndex(index);// 检查下标是否合法
Node<E> x = node(index); // 根据下标获取对应的node对象
E oldVal = x.item; // 记录原来的值
x.item = element; // 赋予新的值
return oldVal; // 返回修改之前的值
}
3.Vector:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CNxHXJu5-1655040132661)(java核心.assets/image-20220526075258695.png)]
其实Vector和ArrayList相似 ,都是以动态数组的形式进行数据的存储的。
但是Vector是安全的 ,那为什么安全呢????
看完下面的代码你就知道了
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
因为每个方法上面都是加上 synchronized 关键字 ,当然是安全的了。但是随之而来的就是效率的问题,synchronized对于性能方面会有很大的影响,慢慢的就被放弃了。
Set集合:

1.HashSet
概述:HashSet实现了set接口,由哈希表支持,他不保证set迭代顺序,也就是不保证元素的顺序,允许使使用null值。
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
从上面的代码可以看到hashSet的本质上就是一个HashMap,其实是将数据保存在了HashMap中,key就是我们添加的内容,value就是我们定义的一个Object对象.
特点:
底层数据结构是 hash 表,HashSet本质是一个没有重复元素的集合,是通过HashMap去实现的。
2.TreeSet
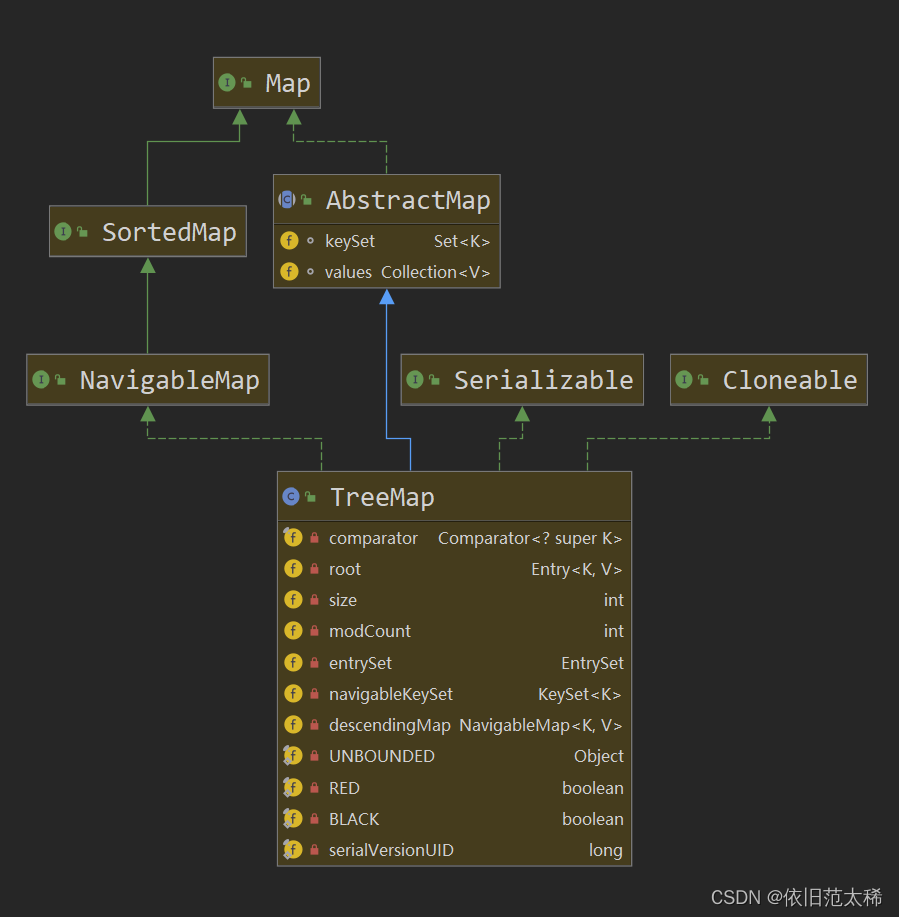
基于TreeMap的 NavigableSet实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator进行排序,具体取决于使用的构造方法。
public TreeSet() {
this(new TreeMap<E,Object>());
}
本质是将数据保存在TreeMap中,key是我们添加的内容,value是定义的一个Object对象。
特点
1、TreeSet 是一个有序的并且可排序的集合,它继承于AbstractSet抽象类,实现了NavigableSet, Cloneable, java.io.Serializable接口。
2、TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。同样的了解了TreeMap就了解了TreeSet。
Map接口:
Map集合的特点:
1.Key 能够存储唯一的列的数据(唯一,不可重复) Set
2.Value 能够存储可以重复的数据(可重复) List
3.有序 值的顺序取决于键的顺序
4.键和值都是可以存储null元素的
TreeMap:
本质上是红黑树的实现:
1.每个节点要么是红色,要么是黑色。
2.根节点必须是黑色
3.每个叶子节点【NIL】是黑色
4.每个红色节点的两个子节点必须是黑色
5.任意节点到每个叶子节点的路径包含相同数量的黑节点
private final Comparator<? super K> comparator; // 比较器
private transient Entry<K,V> root; // 根节点
/**
* The number of entries in the tree
*/
private transient int size = 0; // map中元素的个数
/**
* The number of structural modifications to the tree.
*/
private transient int modCount = 0; // 记录修改的次数
K key; // key
V value; // 值
Entry<K,V> left; // 左子节点
Entry<K,V> right; // 右子节点
Entry<K,V> parent; // 父节点
boolean color = BLACK; // 节点的颜色 默认是黑色
Put方法:
public V put(K key, V value) {
// 将root赋值给局部变量 null
Entry<K,V> t = root;
if (t == null) {
// 初始操作
// 检查key是否为空
compare(key, key); // type (and possibly null) check
// 将要添加的key、 value封装为一个Entry对象 并赋值给root
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent; // 父节点
// split comparator and comparable paths
Comparator<? super K> cpr = comparator; // 获取比较器
if (cpr != null) {
// 一直找到插入节点的父节点
do {
// 将root赋值给了parent
parent = t;
// 和root节点比较值的大小
cmp = cpr.compare(key, t.key);
if (cmp < 0)
// 将父节点的左子节点付给了t
t = t.left;
else if (cmp > 0)
t = t.right; // 将父节点的右节点赋给了t
else
// 直接和父节点的key相等,直接修改值
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// t 就是我们要插入节点的父节点 parent
// 将我们要插入的key value 封装成了一个Entry对象
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e; // 插入的节点在parent节点的左侧
else
parent.right = e; // 插入的节点在parent节点的右侧
fixAfterInsertion(e); // 实现红黑树的平衡
size++;
modCount++;
return null;
}
上面的 fixAfterInsertion 方法 ,具体实现平衡树的方法
private void fixAfterInsertion(Entry<K,V> x) {
//设置添加的节点的颜色为 红色
x.color = RED;
//循环的条件是 1.添加的节点不为空 2.不是root节点 3.父节点的颜色为红色
while (x != null && x != root && x.parent.color == RED) {
//判断 父节点是否是祖父节点的左侧的节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
//获取父节点的兄弟节点 也就是叔叔节点
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
//如果是红色的话
if (colorOf(y) == RED) {
//recolor 变色的操作
setColor(parentOf(x), BLACK); //设置父节点的颜色为 黑色
setColor(y, BLACK); //设置叔叔节点的颜色为 黑色
setColor(parentOf(parentOf(x)), RED); //设置祖父节点的颜色为 红色
//将祖父节点设置为 插入节点
x = parentOf(parentOf(x));
//如果是黑色的话
} else {
if (x == rightOf(parentOf(x))) {
// 判断插入节点是否是 父节点的右侧节点
x = parentOf(x); // 将父节点作为插入节点
rotateLeft(x); // 左旋
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x))); //右旋
}
//父节点是祖父节点的右侧子节点
} else {
//获取叔叔节点
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
//如果叔叔节点为 红色
if (colorOf(y) == RED) {
// recolor 变色
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
//插入节点在父节点的左侧
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x); //右旋
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x))); //左旋
}
}
}
//根节点颜色为 黑色
root.color = BLACK;
}
小贴士: 节点关系图:

HashMap (深入浅出):

HashMap底层结构
Jdk1.7及以前是采用数组+链表
Jdk1.8之后 采用数组+链表 或者 数组+红黑树方式进行元素的存储
存储在hashMap集合中的元素都将是一个Map.Entry的内部接口的实现
// The default initial capacity - MUST be a power of two.
//默认的HashMap中数组的容量 初始是16 必须是2的幂次方
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// HashMap中的数组的最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的扩容的平衡因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表转红黑树的 临界值
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转链表的 临界值
static final int UNTREEIFY_THRESHOLD = 6
// 链表转红黑树的数组长度的临界值
static final int MIN_TREEIFY_CAPACITY = 64;
// HashMap中的数组结构
transient Node<K,V>[] table;
// HashMap中的元素个数
transient int size;
// 对HashMap操作的次数
transient int modCount;
// 扩容的临界值
int threshold;
// 实际的扩容值
final float loadFactor;
Put方法分析:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
参数分析:
(hash(key): 获取Key相应的Hash值
hash(key):获取key对应的hash值
static final int hash(Object key) {
int h;
// key.hashCode() 返回的是一个32长度的二进制值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
为什么要右移16位?
A:1000010001110001000001111000000
B:0111011100111000101000010100000
A 和 B 对 15 11111&运算 得到的都是 0 相同,会造成散列分布不均匀
插入putval
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// 初始的判断
// resize() 初始数组 扩容 初始的时候 获取了一个容量为16的数组
n = (tab = resize()).length; // n 数组长度
// 确定插入的key在数组中的下标 15 11111
// 100001000111000
// 1111
// 1000 = 8
if ((p = tab[i = (n - 1) & hash]) == null)
// 通过hash值找到的数组的下标 里面没有内容就直接赋值
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash // hash值相同&&
// key也相同
((k = p.key) == key || (key != null && key.equals(k))))
// 插入的值的key 和 数组当前位置的 key是同一个 那么直接修改里面内容
e = p;
else if (p instanceof TreeNode)
// 表示 数组中存放的节点是一个 红黑树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 表示节点就是普通的链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 到了链表的尾部
p.next = newNode(hash, key, value, null);
// 将新的节点添加到了链表的尾部
// 判断是否满足 链表转红黑树的条件
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 转红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
第一次resize()第一次执行时 创建了一个 Node[16] 扩容的临界值(12)
final Node<K,V>[] resize() {
// table = null
Node<K,V>[] oldTab = table;
// oldCap = 0
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 原来的扩容因子 0
int oldThr = threshold;
// 新的容量和新的扩容因子
int newCap, newThr = 0;
if (oldCap > 0) { // 初始不执行 0
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}// 初始为0
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// 新的数组容量 16
newCap = DEFAULT_INITIAL_CAPACITY;
// 新的扩容因子 0.75 * 16 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}// 更新了 扩容的临界值 12
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建了一个容量为16的Node数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 更新了table
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
treeifyBin方法 如果数组的长度没有达到64 那么就尝试扩容 并不会转换为红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// tab为空 或者 数组的长度小于64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize(); // 扩容
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 链表转红黑树的逻辑
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
动态扩容
final Node<K,V>[] resize() {
// [1,2,3,4,5,6,7,8,9,10,11,,,,]
Node<K,V>[] oldTab = table;
// 16
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 12
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 新的容量是 原来容量的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 扩容的临界值 原来的两倍 24
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建的数组的长度是32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) { // 初始的时候是不需要复制的
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 数组中的元素就一个 找到元素在新的数组中的位置 赋值
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 移动红黑树节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 普通的链表的移动
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
流程图:

参考博客: https://blog.csdn.net/Relaxaaa/article/details/124866175
Iterator迭代:
工具类:
Collections
通过下面的这种方式可以将数组转换为安全的集合: 比如将 ArayList数组转换为线程安全的集合
本质上就是在原有代码的基础上做了一层synchronized同步代码块的包装
List<Object> synList = Collections.synchronizedList(list);
Arrays
比较器:
Comparable:
Comparator:
三. 泛型
本质: 参数化类型
指定存放的数据类型,统一类型防止出现 类型转换异常
泛型的擦除:
泛型只是在编译阶段有效,编译之后JVM会采取 去泛型化 的措施。
泛型在运行阶段是没有效果的
List<String> list = new ArrayList<>();
list.add("樱木花道");
//通过反射的机制去进行添加数据
Class<? extends List> clazz = list.getClass();
Method method = clazz.getDeclaredMethod("add", Object.class);
//注意 这里添加的是一个int类型的值
method.invoke(list,1);
System.out.println(list);
泛型通配符的介绍:
好处:
在保证运行时类型安全的基础上,提高参数类型的灵活性。
协变和逆变:
假设F(X)代表java中的一种代码模式,其中X为此模式中可变的部分。如果B是A的派生类,而F(B)也享受F(A)派生类的待遇,那么F模式是协变的。
如果F(A)反过来享受F(B)派生类的待遇,那么F模式是逆变的。
如果F(A)和F(B)之间不享受任何继承待遇,那么F模式是不变的。(这里的继承待遇指的是“如果B类是A类的派生类,那么B类的引用可以赋值给A类的引用。)
1、无边界通配符
无边界的通配符的主要作用就是让泛型能够接收未知类型的数据。
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("樱木花道");
list.add("流川枫");
list.add("赤木刚宪");
loop(list);
}
//传过来是什么就是什么
public static void loop(List<?> list) {
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
2、上边界通配符—协变
public static void main(String[] args) {
List<Number> listNumber = new ArrayList<>();
listNumber.add(1);
listNumber.add(2);
listNumber.add(3);
loop(listNumber);
}
/**
* 循环
*通用的类型必须是Number及其子类
* @param list 列表
*/
public static void loop(List<? extends Number> list) {
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
不能写数据:如果是Integer数据,那么便不能放入String数据的集合(类型安全问题)
可以读数据:String类型也是Object类型的派生类,此时通过Object去取数据,不会发生任何类型安全问题。
简单概括就是: 只能读不能写
3、下边界通配符—逆变
public static void main(String[] args) {
List<Number> listNumber = new ArrayList<>();
listNumber.add(1);
listNumber.add(2);
listNumber.add(3);
//因为这里是Number类型的 如果是Integer类型的就会编译报错
loop(listNumber);
}
/**
* 循环
*通用类型必须是Integer到Object类型的
* @param list 列表
*/
public static void loop(List<? super Number> list) {
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
不能读数据:因为类型擦除,编译器并不知道数据的确切类型是什么,可能是Integer,可能是Number,也可能是Object,所以取出来的具体是什么数据不清楚,因此当使用具体类型去接收时,编译器会报错。
但是如果是一个确定的类型,当做Object取出来,而且你又无法判断它是什么,其实是没有多大意义的。
可以写数据:只能往集合中添加Integer类型的数据,因为集合一定是Integer或其父类类型的,所以不会存在类型安全问题。
简单概括就是: 只能写不能读
泛型的具体的使用:
规则: 必须先声明在进行使用
泛型的声明是通过<>符号实现的 约定泛型是可以使用单个大写的字母来表示的 K E T V 等
泛型类
这个是定义的泛型类
public class PersonNew<T> {
private T t;
public PersonNew() {
}
public PersonNew(T t) {
this.t = t;
}
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
/**这个是编写的实体类*/
public class PersonBean {
private String idCard;
private String address;
private String username;
private int age;
public PersonBean() {
}
public PersonBean(String idCard, String address, String username, int age) {
this.idCard = idCard;
this.address = address;
this.username = username;
this.age = age;
}
public String getIdCard() {
return idCard;
}
public void setIdCard(String idCard) {
this.idCard = idCard;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public static void main(String[] args) {
PersonBean personBean = new PersonBean();
personBean.setUsername("樱木花道");
personBean.setAddress("神奈川");
personBean.setAge(18);
personBean.setIdCard("xxxxxxxxxxxxxxxxxxx");
//在这里进行了一个泛型的指定 通过有参构造的方式进行赋值
PersonNew<PersonBean> personNew = new PersonNew<>(personBean);
}
可以增加我们代码的一个灵活度
泛型方法
/**
* 方法
*普通方法可以使用类中定义的泛型
* @param k k
* @param v v
* @return {@link K}
*/
public K method1(K k,V v) {
return (K)null;
}
/**
* method2
*普通方法可以使用类中定义的方法
* @param t t
* @param v v
* @return {@link T}
*/
public <T> T method2(T t,V v) {
return (T)null;
}
/**
* method3
*静态方法中是无法使用类中定义的泛型的
*但是是可以使用方法中定义的泛型的
* @param t t
* @param v v
* @return {@link T}
*/
public static <T> T method3(T t,V vz) { //注意 这个泛型V这个时候是编译报错的 因为是类中的泛型
return (T)null;
}
泛型接口
public interface CalcGeneric <T>{
T add(T a,T b);
T sub(T a,T b);
T multiply(T a,T b);
T division(T a,T b);
}
public class Demo09 implements CalcGeneric<Integer>{
@Override
public Integer add(Integer a, Integer b) {
return null;
}
@Override
public Integer sub(Integer a, Integer b) {
return null;
}
@Override
public Integer multiply(Integer a, Integer b) {
return null;
}
@Override
public Integer division(Integer a, Integer b) {
return null;
}
}
可以看到,我们在定义接口的时候使用了泛型,但是实际上指定具体的泛型是的时候却是在实现接口的时候,也就是说我们可以在定义接口的时候不指定具体的泛型,通过子类实现的方式去直接或者间接的方式去指定这个泛型。
四.反射
反射的定义:
反向的探知,在程序运行的时候去动态的获取类的相关属性。
反射的优缺点:
优点:
1.增加程序的灵活性,避免固有程序写死到程序中
2.代码相对简洁,可以提高程序的复用性
缺点:
1.相对于直接调用 发射有较大的性能消耗
2.内部暴露和安全隐患问题
反射为什么会慢:
- 调用了一个native方法
- 每次创建(newInstace)要做一个安全检查
反射的操作:
1.获取类对象的四种方式
//1.类名.class
Class<User> clazz1 = User.class;
//2.对象.getclass
User user = new User();
Class<? extends User> aClass = user.getClass();
//3.classForname
String path = "全限定类名";
Class<?> clazz2 = Class.forName(path);
//4.通过类加载器的方式
Class<?> clazz3 = Demo01.class.getClassLoader().loadClass("全限定类名");
2.基本信息操作
参考api
//获取类的修饰符 返回的是一个数字 不同的修饰符不同的的数字 可以参考api
System.out.println(clazz2.getModifiers());
//获取一个简单的名字
System.out.println(clazz1.getSimpleName());
//获取名字
System.out.println(clazz1.getName());
//获取包名
System.out.println(clazz1.getPackage());
//获取类加载器
System.out.println(clazz1.getClassLoader());
//获取父类
System.out.println(clazz1.getSuperclass());
//获取类实现的接口的数量
System.out.println(clazz2.getInterfaces().length);
//获取类注解的数量
System.out.println(clazz2.getAnnotations().length);
3.对于字段的一些操作
/**
* Field操作
* @param args
*/
public static void main(String[] args) throws Exception {
Class<User> userClass = User.class;
// 获取User对象
User user = userClass.newInstance();
// 获取类型中定义的字段 共有的字段以及父类中共有的字段
Field[] fields1 = userClass.getFields();
for(Field f:fields1){
System.out.println(f.getModifiers() + " " + f.getName());
}
System.out.println("--------------------");
// 可以获取私有的字段 只能够获取当前类中
Field[] fields2 = userClass.getDeclaredFields();
for(Field f:fields2){
System.out.println(f.getModifiers() + " " + f.getName());
}
// 获取name字段对应的Field
Field nameField = userClass.getDeclaredField("name");
// 如果要修改私有属性信息那么我们需要放开权限
nameField.setAccessible(true);
nameField.set(user,"樱木花道");
System.out.println(user.getName());
// 如果对静态属性赋值
Field addressField = userClass.getDeclaredField("address");
addressField.set(null,"神奈川");
System.out.println(User.address);
}
4.对于方法的一些操作
public static void main(String[] args) throws Exception {
User user = new User();
Class<User> userClass = User.class;
// 可以获取当前类及其父类中的所有的共有的方法
Method[] methods = userClass.getMethods();
for (Method m : methods) {
System.out.println(m.getModifiers() + " " + m.getName());
}
System.out.println("**********");
// 获取本类中的所有的方法 包括私有的
Method[] declaredMethods = userClass.getDeclaredMethods();
for (Method m:declaredMethods){
System.out.println(m.getModifiers() + " " + m.getName());
}
Method jumpMethod = userClass.getDeclaredMethod("jump");
// 放开私有方法的调用
jumpMethod.setAccessible(true);
jumpMethod.invoke(user);
Method sayMethod = userClass.getDeclaredMethod("say", String.class);
// 静态方法调用
sayMethod.invoke(null,"樱木花道");
}
5.对于构造器的一些操作
/**
* 构造器的操作
* @param args
*/
public static void main(String[] args) throws Exception {
Class<User> userClass = User.class;
// 获取所有的公有的构造器
Constructor<?>[] constructors = userClass.getConstructors();
for (Constructor c:constructors){
System.out.println(c.getModifiers() + " " + c.getName() );
}
System.out.println("************************");
// 获取所有的构造器
Constructor<?>[] declaredConstructors = userClass.getDeclaredConstructors();
for (Constructor c:declaredConstructors){
System.out.println(c.getModifiers() + " " + c.getName() );
}
// 1.直接通过newInstance创建对象
User user = userClass.newInstance();
// 2.获取对应的Construcator对象获取实例
Constructor<User> declaredConstructor = userClass.getDeclaredConstructor(String.class, String.class);
// 私有的构造器调用需要放开权限
declaredConstructor.setAccessible(true);
System.out.println(declaredConstructor.newInstance("阿牧","男"));
}
单例的漏洞:
漏洞:创建对象的是的时候默认是单例的,但是通过反射的情况,我们可以创建一个新的对象出来。
造成的原因是什么: 反射可以调用私有的构造器造成的
public class PersonSingle {
private static PersonSingle instance;
private PersonSingle(){
if(instance != null){
throw new RuntimeException("实例已经存在了,不允许再创建...");
}
}
public static PersonSingle getInstance(){
if(instance == null){
instance = new PersonSingle();
}
return instance;
}
}
解决方案: 在私有构造器中加入逻辑判断,结合RuntimeException异常。
public static void main(String[] args) throws Exception {
PersonSingle p1 = PersonSingle.getInstance();
PersonSingle p2 = PersonSingle.getInstance();
PersonSingle p3 = PersonSingle.getInstance();
System.out.println(p1); //
System.out.println(p2); //------>这三个创建出来的对象是相同的
System.out.println(p3); //
// 通过反射获取实例
Constructor<? extends PersonSingle> declaredConstructor = p1.getClass().getDeclaredConstructor();
declaredConstructor.setAccessible(true);
System.out.println( declaredConstructor.newInstance()); //这个创建出来的对象是一个新的
}
反射的使用场景:
1.jdbc封装
2.SpringIOC
3.JdbcTemplate
4.Mybatis
…
反射的应用: SpringIoc
IOC 控制反转 就是一种设计思想,容器 管理对象
try {
// 创建对应IOC容器对象
DefaultListableBeanFactory beanFactory = this.createBeanFactory();
beanFactory.setSerializationId(this.getId());
this.customizeBeanFactory(beanFactory);
// 配置文件中的<bean> 会被解析封装为一个 BeanDefinition
this.loadBeanDefinitions(beanFactory);
Object var2 = this.beanFactoryMonitor;
synchronized(this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
} catch (IOException var5) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + this.getDisplayName(), var5);
}
// 加载配置文件 SAX
Document doc = this.doLoadDocument(inputSource, resource);
// 配置文件解析 BeanDefinition
return this.registerBeanDefinitions(doc, resource);
public void refresh() throws BeansException, IllegalStateException {
Object var1 = this.startupShutdownMonitor;
synchronized(this.startupShutdownMonitor) {
this.prepareRefresh();
// 创建IOC容器对象 BeanFactory 同时解析配置文件
ConfigurableListableBeanFactory beanFactory = this.obtainFreshBeanFactory();
this.prepareBeanFactory(beanFactory);
try {
this.postProcessBeanFactory(beanFactory);
this.invokeBeanFactoryPostProcessors(beanFactory);
this.registerBeanPostProcessors(beanFactory);
this.initMessageSource();
this.initApplicationEventMulticaster();
this.onRefresh();
this.registerListeners();
// 单例对象的实例化
this.finishBeanFactoryInitialization(beanFactory);
this.finishRefresh();
} catch (BeansException var9) {
if (this.logger.isWarnEnabled()) {
this.logger.warn("Exception encountered during context initialization - cancelling refresh attempt: " + var9);
}
this.destroyBeans();
this.cancelRefresh(var9);
throw var9;
} finally {
this.resetCommonCaches();
}
}
}
public static <T> T instantiateClass(Constructor<T> ctor, Object... args) throws BeanInstantiationException {
Assert.notNull(ctor, "Constructor must not be null");
try {
ReflectionUtils.makeAccessible(ctor);
//反射创建对象
return ctor.newInstance(args);
} catch (InstantiationException var3) {
throw new BeanInstantiationException(ctor, "Is it an abstract class?", var3);
} catch (IllegalAccessException var4) {
throw new BeanInstantiationException(ctor, "Is the constructor accessible?", var4);
} catch (IllegalArgumentException var5) {
throw new BeanInstantiationException(ctor, "Illegal arguments for constructor", var5);
} catch (InvocationTargetException var6) {
throw new BeanInstantiationException(ctor, "Constructor threw exception", var6.getTargetException());
}
}
五.注解
1.注解的概念
注解: 说明程序的,给计算机看的
注释: 用文字描述程序,给程序员看的
定义:
注解(Annotation),也叫元数据。一种代码级别的说明。它是JDK1.5及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明,注释。
作用分类:
1.编写文档:通过代码里标识的注解生成文档【生成文档doc文档】
2.代码分析:通过代码里标识的注解对代码进行分析【使用反射】
3.编译检查:通过代码里标识的注解让编译器能够实现基本的编译检查【Override】****
2.JDK预定义的注解
@Override: 检查该注解标注的方式是否是继承自父类【接口】
@Deprecated: 该注解表示注释的内容的过时
@SupressWarning: 压制警告
all to suppress all warnings (抑制所有警告)
boxing to suppress warnings relative to boxing/unboxing operations(抑制装箱、拆箱操作时候的警告)
cast to suppress warnings relative to cast operations (抑制映射相关的警告)
dep-ann to suppress warnings relative to deprecated annotation(抑制启用注释的警告)
deprecation to suppress warnings relative to deprecation(抑制过期方法警告)
fallthrough to suppress warnings relative to missing breaks in switch statements(抑制确在switch中缺失breaks的警告)
finally to suppress warnings relative to finally block that don’t return (抑制finally模块没有返回的警告)
hiding to suppress warnings relative to locals that hide variable()
incomplete-switch to suppress warnings relative to missing entries in a switch statement (enum case)(忽略没有完整的switch语句)
nls to suppress warnings relative to non-nls string literals(忽略非nls格式的字符)
null to suppress warnings relative to null analysis(忽略对null的操作)
rawtypes to suppress warnings relative to un-specific types when using generics on class params(使用generics时忽略没有指定相应的类型)
restriction to suppress warnings relative to usage of discouraged or forbidden references
serial to suppress warnings relative to missing serialVersionUID field for a serializable class(忽略在serializable类中没有声明serialVersionUID变量)
static-access to suppress warnings relative to incorrect static access(抑制不正确的静态访问方式警告)
synthetic-access to suppress warnings relative to unoptimized access from inner classes(抑制子类没有按最优方法访问内部类的警告)
unchecked to suppress warnings relative to unchecked operations(抑制没有进行类型检查操作的警告)
unqualified-field-access to suppress warnings relative to field access unqualified (抑制没有权限访问的域的警告)
unused to suppress warnings relative to unused code (抑制没被使用过的代码的警告)
@SuppressWarnings("all")
public class AnnoDemo01 {
@Override
public String toString() {
return "AnnoDemo01{}";
}
@Deprecated
public void show1(){
// 发现过时了,功能更不上需求了
}
public void show2(){
// 功能更加强大的方法
}
public void demo(){
show1(); // 这个正常显示中间会有一个横线 意思是不推荐使用,但是可以使用
show2();
Date date = new Date();
date.getYear();
}
}
3.自定义注解
对应的那四个元注解
public @interface 注解名称{
// 属性列表
}
自定义的注解反编译之后的内容:
public interface MyAnno extends java.lang.annotation.Annotation {
}
注解的本质其实就是一个接口,继承Annotation父接口
/**
* 注解的本质就是接口
*/
public @interface MyAnno {
public String show();
}
属性: 在接口中定义的抽象方法
返回结果必须是如下类型
1.基本数据类型
2.String类型
3.枚举类型
4.注解
5.以上类型的数组
属性赋值注意点:
1.如果定义的属性时,使用default关键字给属性默认初始值,可以在使用注解是不赋值
2.如果只有一个属性需要赋值,而且该属性的名称是
value,那么在赋值时,value可以省略。3.数组赋值的时候,值使用
{}包裹,如果数组中只有一个值,那么{}可以省略
/**
* 注解的本质就是接口
*/
public @interface MyAnno {
String value();
MyAnno2 show4();
PersonEnum show5();
String[] show3();
//String name();
//int age() default 18; // 指定默认值 在使用注解的时候没有给该属性赋值,那么就使用默认值
/*String show1();*/
/*int show2();
String[] show3();
MyAnno2 show4();
PersonEnum show5();*/
}
@MyAnno(value="show2",show4 = @MyAnno2,show5 = PersonEnum.P1,show3 = "a")
public void show2(){
// 功能更加强大的方法
}
4.元注解
Jdk中给我们提供的四个元注解
1.@Target:描述当前注解能够作用的位置
ElementType.TYPE:可以作用在类上
ElementType.METHOD:可以作用在方法上
ElementType.FIELD:可以作用在成员变量上
2.@Retention: 描述注解被保留到的阶段
SOURCE < CLASS < RUNTIME
SOURCE:表示当前注解只在代码阶段有效
CLASS:表示该注解会被保留到字节码阶段
RUNTIME:表示该注解会被保留到运行阶段 JVM
自定义的注解:RetentionPolicy.RUNTIME
3.@Documented:描述注解是否被抽取到JavaDoc api中 就是说会显示在我们生成api文档中
4.@inherited:描述注解是否可以被子类继承
@Target({ElementType.TYPE,ElementType.METHOD,ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface MyAnno3 {
}
5.自定义注解的实现
自定义的注解:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface InvokeAnno {
//定义的两个属性
String classname();
String method();
}
对应方法的类:
public class Student {
public void sleeping() {
System.out.println("我要睡觉了");
}
}
具体调用的类:
@InvokeAnno(classname = "com.xxx.xxx.xxx.Student",method = "sleeping")
public class MyMain {
public static void main(String[] args) throws Exception {
//获取类对象
Class<MyMain> clazz = MyMain.class;
//获取对象中的注解
InvokeAnno annotation = clazz.getAnnotation(InvokeAnno.class);
//获取直注解中对应的属性
String className = annotation.classname(); //com.xxx.xxx.xxx.Student
String methodName = annotation.method(); //sleeping
/**
* 注解本质是 接口 获取到的其实是接口的实现
* public class MyInvokAnno implements InvokAnno{
*
* String className(){
* return "com.xxx.xxx.anno.Student";
* }
* String methodName(){
* return "sleeping";
* }
* }
*/
//通过上面获取的classname的名称反射去执行方法
Class<?> clazz2 = Class.forName(className);
Method method = clazz2.getDeclaredMethod(methodName);
Object o = clazz2.newInstance();
method.invoke(o);
}
}















 554
554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









