







概念梳理
MOLAP 多维度分析(数据立方详细介绍),需要预设数据立方
ROLAP 传统的关系型数据分析引擎
kylin 基于hadoop集群hive存储数据立方,以空间换时间,将预计算结果存储加速查询,预计算就是 Kylin 在大规模并行处理和列式存储之外,提供给大数据分析的第三个关键技术
calcite 查询引擎(会将查询过滤条件下推等优化,提高内存等利用率)
他的作用是优化查询逻辑:Apache Calcite:Hadoop中新型大数据查询引擎
Apache Calcite 是面向 Hadoop 新的查询引擎,它提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力,除此之外,Calcite 还提供了 OLAP 和流处理的查询引擎。正是有了这些诸多特性,Calcite 项目在 Hadoop 中越来越引入注目,并被众多项目集成。
多维分析: 多维分析存在于 可视化 和存储分析引擎(数据立方)两处地方,第一种是像kylin 这个偏重于存储上多维分析 group ,上卷,下钻等操作,第二种在于可视化上如下
可视化
| superset(数据可视化) | metabase(数据可视化) | dataease | saiku(基于mondrian封装数据立方) | 基于mondrian自研开发 | 基于sqlbuilder自研开发 |
|---|---|---|---|---|---|
| Apache License 2.0 | AGPL 需要开放源码 | GNU 需要开放源码 | Apache License 2.0 | 无 | 无 |
| python | clojure | Java | Java | Java | Java |
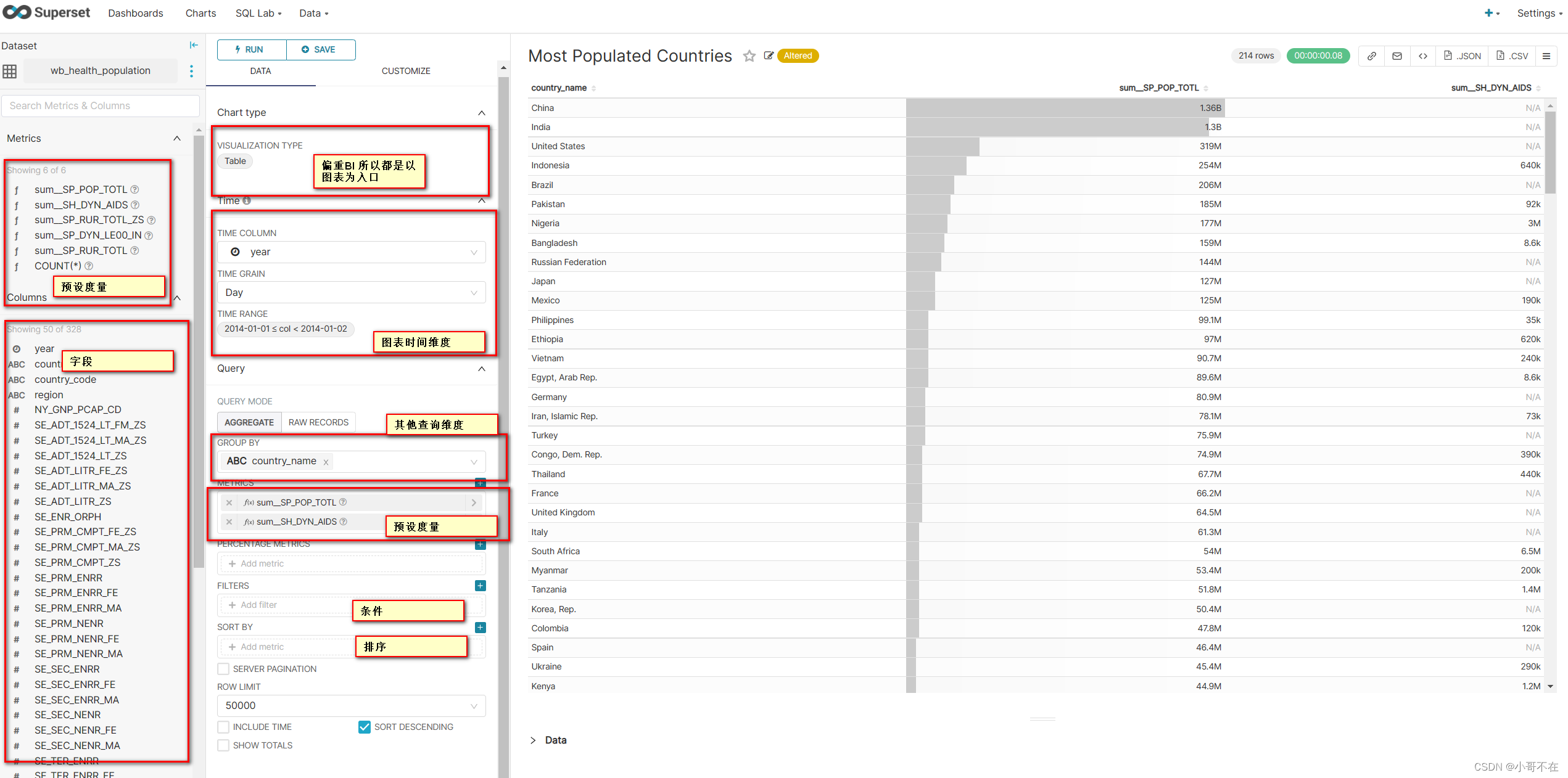
| 社区活跃,用起来更偏重于开发,更适合软件开发人员操作,设计时以图表为入口,不同图表需要设置不同参数,非星型数据结构,单表group sql 查询(查询构造器) | 社区活跃,产品定位是更加易用,通过创建问题创建的查询,查询分解为数据,关联,伪列,过滤器,聚合,排序,行限制等概念的定义实现(支持星型结构存储更加灵活) | 国产,有源码 | 多维分析工具,3.x版本使用比较麻烦,使用需要license ,但是license申请已经关闭,社区不再维护,可以使用2.x版本,也比较麻烦,基于mondrian 开发,支持星型结构和雪花结构数据,MDX语法相较于SQL复杂,若想深度使用需要学习MDX | 结合mondrian mdx定义实现一部分多维度分析查询逻辑,需要模型定义时触发mdx schema 生成更新逻辑(模仿saiku) | 仿metabase实现 |
| (偏重数据可视化)python开发,不同于metabase设计,提供另外一种设计,场景简单且无法做到动态多维度分析 | (偏重数据可视化)语言比较奇怪,无法做到动态多维度分析,可以借鉴其前端设计概念 | (偏重数据可视化)简单场景,只能通过数据集设定查询数据(或者使用关联数据集),无法做到多维度分析 | 2.X有源码可以借鉴,mdx schema定义和mdx 学习 | 模仿saiku实现,生成schema和mdx 交给Mondrian执行 | 模仿metabase实现,生成执行sql 给jdbc执行 |
使用sql实现
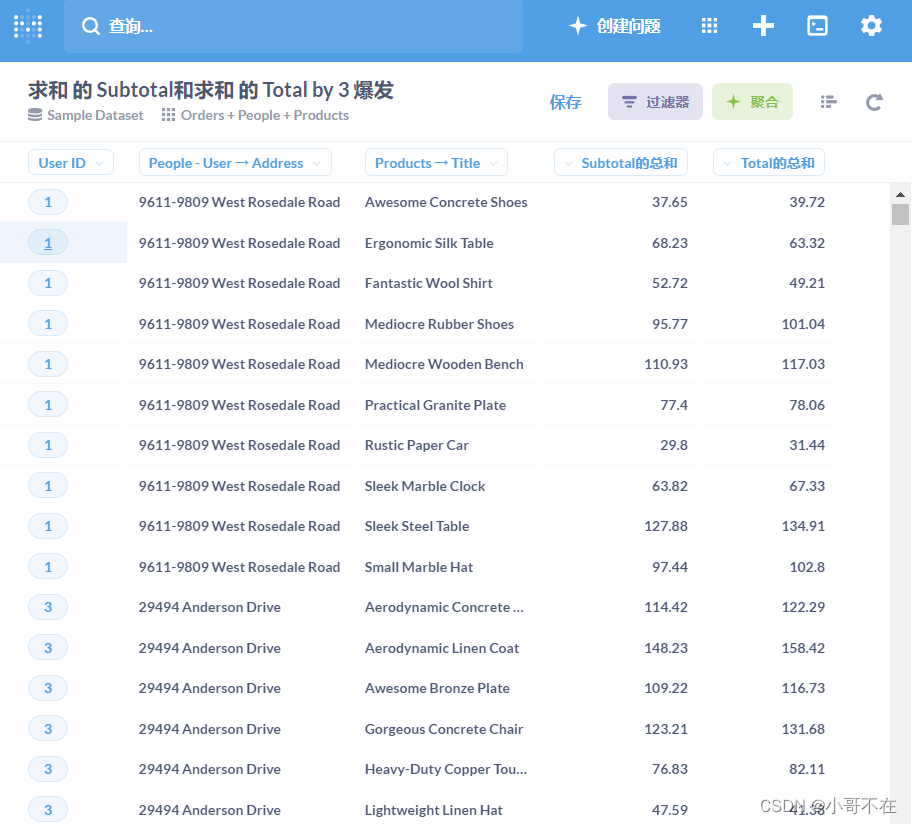
如下做可视化metabase 生成的sql
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K8RCGHjj-1672709433051)(D:\Bak7\2022-12-20_091819.png)]](https://img-blog.csdnimg.cn/417308934bf7479f8b2837e4b3c44f74.png)
SELECT
"People - User"."NAME" AS "People - User__NAME",
"Products"."TITLE" AS "Products__TITLE",
"People - User"."ADDRESS" AS "People - User__ADDRESS",
sum("PUBLIC"."ORDERS"."TOTAL") AS "sum",
sum(
"PUBLIC"."ORDERS"."QUANTITY"
) AS "sum_2"
FROM
"PUBLIC"."ORDERS"
LEFT JOIN "PUBLIC"."PEOPLE" "People - User" ON "PUBLIC"."ORDERS"."USER_ID" = "People - User"."ID"
LEFT JOIN "PUBLIC"."PRODUCTS" "Products" ON "PUBLIC"."ORDERS"."PRODUCT_ID" = "Products"."ID"
WHERE
(
"People - User"."NAME" IS NOT NULL
AND (
"People - User"."NAME" <> ''
OR "People - User"."NAME" IS NULL
)
)
GROUP BY
"People - User"."NAME",
"Products"."TITLE",
"People - User"."ADDRESS"
ORDER BY
"People - User"."NAME" ASC,
"Products"."TITLE" ASC,
"People - User"."ADDRESS" ASC
使用mdx实现
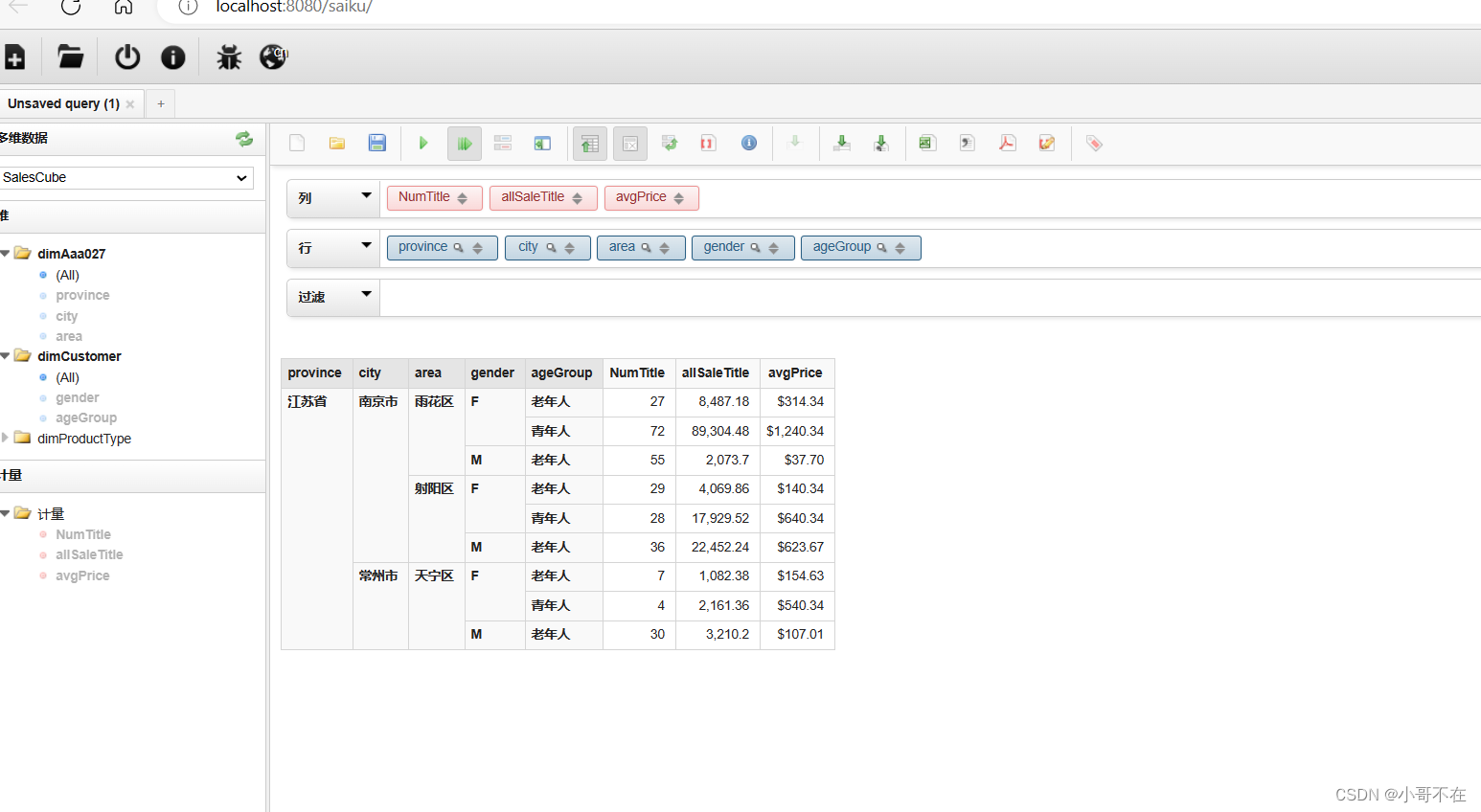
SELECT
NON EMPTY {[Measures].[saleNumber], [Measures].[saleAmount], [Measures].[avgPrice]} ON COLUMNS,
NON EMPTY Hierarchize(Union(CrossJoin([dimAaa027].[province].Members, [dimCustomer].[gender].Members), Union(CrossJoin([dimAaa027].[province].Members, [dimCustomer].[ageGroup].Members), Union(CrossJoin([dimAaa027].[city].Members, [dimCustomer].[gender].Members), Union(CrossJoin([dimAaa027].[city].Members, [dimCustomer].[ageGroup].Members), Union(CrossJoin([dimAaa027].[area].Members, [dimCustomer].[gender].Members), CrossJoin([dimAaa027].[area].Members, [dimCustomer].[ageGroup].Members))))))) ON ROWS
FROM [SalesCube]
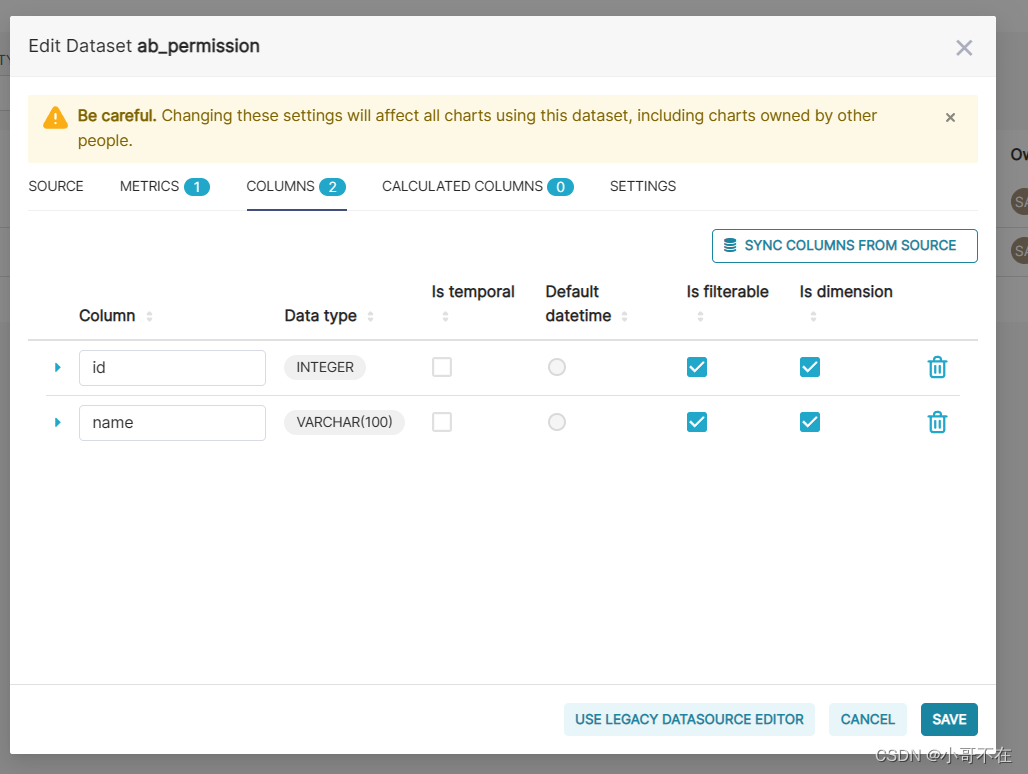
dataset 设计















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









