







论文阅读12:Spatio-Temporal Tuples Transformer forSkeleton-Based Action Recognition-2021STTFormer
Abstract
-
problems currently : the existing Transformer-based meth-ods cannot capture the correlation of different joints between frames
-
The skeleton sequence is divided into several parts, and several consecu-tive frames contained in each part are encoded. And then a spatio-temporal tuplesself-attention module is proposed to capture the relationship of different joints inconsecutive frames. In addition, a feature aggregation module is introduced be-tween non-adjacent frames to enhance the ability to distinguish similar actions.
the three points of this paper.
Introduction
-
the above methods(RNN,CNN,GCN) cannot effectively model the long-term dependence of sequences and the global correlation of spatio-temporal joints.
是否可以使用例如non-local, slow-fast 之类的策略来进行skeleton based action recognition. -
本文重点:extract the related features of different joints between adjacent frames
这算是一种解释,而非出发点,感觉。
-
两个模块:
-
STTA - spatio-temporal tuple self-attention. 进行局部连续帧的注意力。
-
IFFA - 非连续帧间的注意力,信息整合。
-
Related Work
-
Self-Attention Mechanism
-
Skeleton-Based Action Recognition
-
Context Aware-based Methods
Method
-
Overall Architecture
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZOxzAzQq-1670233788376)(https://github.com/smiledinisa/Images/blob/master/QQ%E5%9B%BE%E7%89%8720221205101038.png?raw=true)]](https://img-blog.csdnimg.cn/519c70c593594d1a98182733295dee62.png)
-
Spatio-Temporal Tuples Encoding
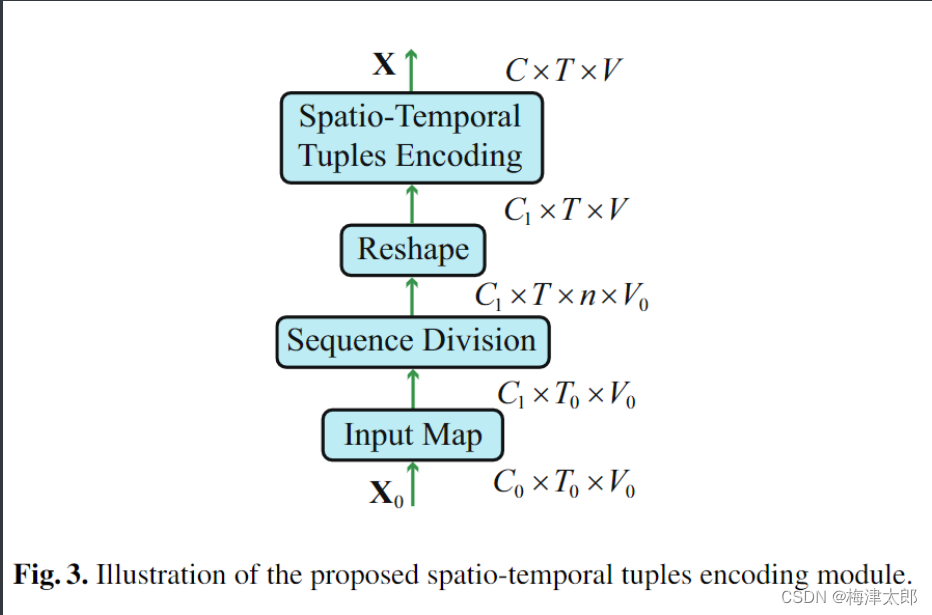
-
I n p u t X ∈ R C 0 × T 0 × V 0 Input X \in \mathbb{R}^{C_0 \times T_0 \times V_0} InputX∈RC0×T0×V0
-
c o n v 1 = c o n v 1 + b a t h N o r m + L e a k y R e L U conv1 = conv1 + bathNorm + Leaky ReLU conv1=conv1+bathNorm+LeakyReLU.
$ X$ shape : C 0 , T 0 , V 0 → C 1 , T 0 , V 0 C_0,T_0,V_0 \rightarrow C_1,T_0,V_0 C0,T0,V0→C1,T0,V0
-
skeleton sequence divide : X = X . r e s h a p e ( C 1 , T , n , V 0 ) , T 0 = n × T 0 ) X = X.reshape(C_1,T,n,V_0), T_0 = n\times T_0) X=X.reshape(C1,T,n,V0),T0=n×T0) 这里, T × n T\times n T×n 表示,将原来序列分成 T T T段,每一段是原始序列中连续的 n n n个序列。
-
flatten : X ← X . r e s h a p e ( C 1 , T , n ∗ V 0 ) X \gets X.reshape(C1,T,n*V_0) X←X.reshape(C1,T,n∗V0)
-
c o n v 2 = c o n v o l u t i o n a l l a y e r + L e a k y R e l u ( ) conv2 = convolutional layer + LeakyRelu() conv2=convolutionallayer+LeakyRelu()
-
-
Positional Encoding
P E ( p , 2 i ) = sin ( p / 1000 0 2 i / C i n ) P E ( p , 2 i + 1 ) = cos ( p / 1000 0 2 i / C i n ) \begin{array}{l} P E(p, 2 i)=\sin \left(p / 10000^{2 i / C_{i n}}\right) \\ P E(p, 2 i+1)=\cos \left(p / 10000^{2 i / C_{i n}}\right) \end{array} PE(p,2i)=sin(p/100002i/Cin)PE(p,2i+1)=cos(p/100002i/Cin)
其中 p p p表示位置, i i i 表示维度
-
Spatio-Temporal Tuples Transformer
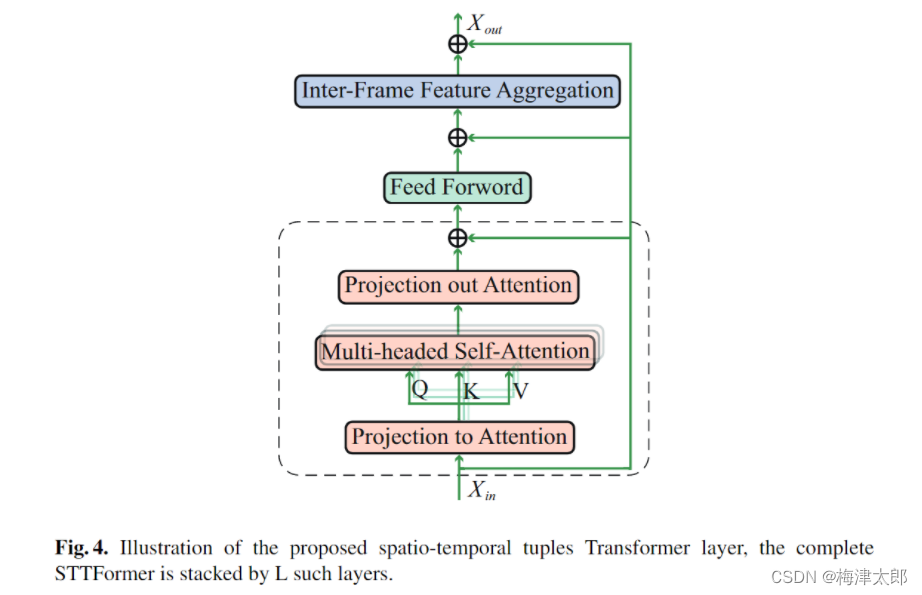
- Spatio-Temporal Tuples Attention
-
求Q,K,V
Q , K , V = Conv ∗ 2 D ( 1 × 1 ) ( X ∗ i n ) \mathbf{Q}, \mathbf{K}, \mathbf{V}=\operatorname{Conv}*{2 D(1 \times 1)}\left(\mathbf{X}*{i n}\right) Q,K,V=Conv∗2D(1×1)(X∗in)
-
求X,多头注意力
-
X a t t n = Tanh ( Q K T C ) V \mathbf{X}_{a t t n}=\operatorname{Tanh}\left(\frac{\mathbf{Q K}^{\mathbf{T}}}{\sqrt{C}}\right) \mathbf{V} Xattn=Tanh(CQKT)V
-
X Attn = Concat ( X a t t n 1 , ⋯ , X attn h ) \mathbf{X}_{\text {Attn }}=\operatorname{Concat}\left(\mathbf{X}_{a t t n}^{1}, \cdots, \mathbf{X}_{\text {attn }}^{h}\right) XAttn =Concat(Xattn1,⋯,Xattn h)
-
X S T T A = Conv 2 D ( 1 × k 1 ) ( X A t t n ) \mathbf{X}_{S T T A}=\operatorname{Conv}_{2 D\left(1 \times k_{1}\right)}\left(\mathbf{X}_{A t t n}\right) XSTTA=Conv2D(1×k1)(XAttn)
-
-
在feed forword 前进行残差,残差为 c o n v 1 × 1 conv1\times1 conv1×1
-
- Inter-Frame Feature Aggregation
X I F F A = Conv 2 D ( k 2 × 1 ) ( X S T T A ) \mathbf{X}_{I F F A}=\operatorname{Conv}_{2 D\left(k_{2} \times 1\right)}\left(\mathbf{X}_{S T T A}\right) XIFFA=Conv2D(k2×1)(XSTTA)
X s a h p e : C , T , V X sahpe : C,T,V Xsahpe:C,T,V, conv on temporal dimmension.
Aggregation T T T sub actions.
当然残差链接依然是需要的。
Experiment
。。。。
Aggregation $T$ sub actions.
当然残差链接依然是需要的。
Experiment
。。。。















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









