



效果展示:
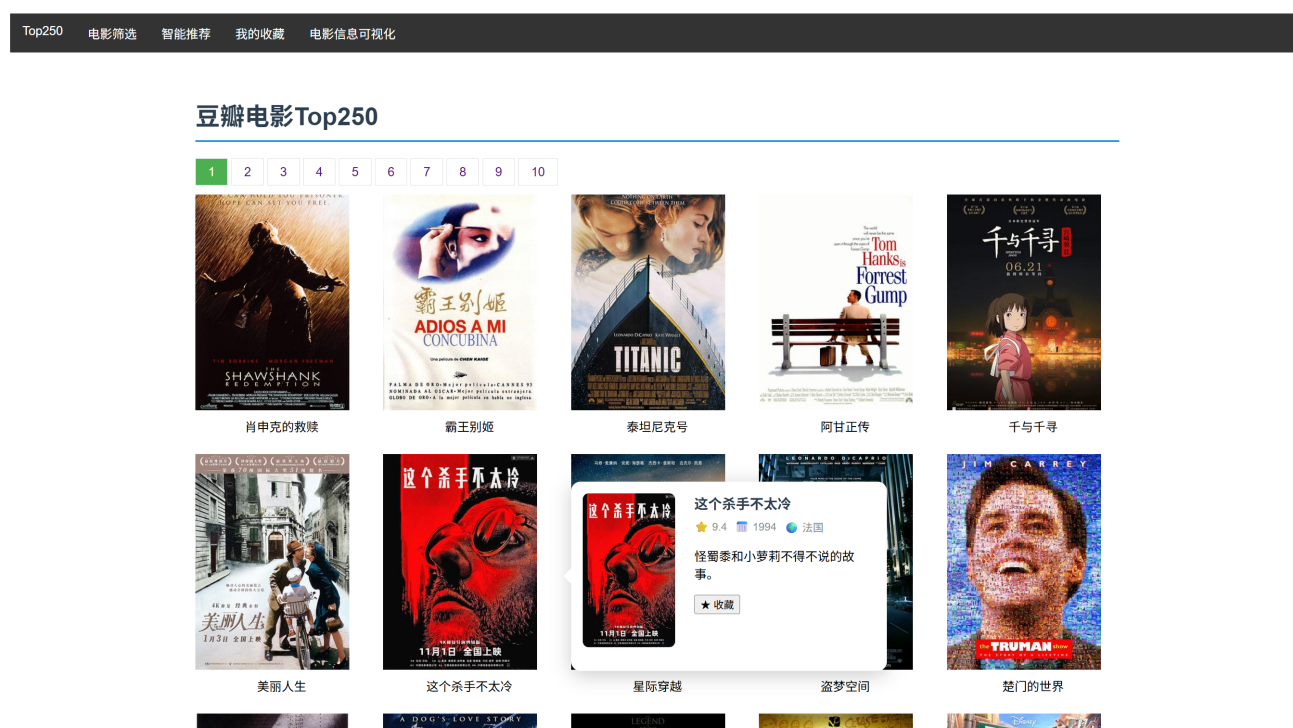
此篇文章只展示TF-IDF算法实现的电影推荐部分,因为是和同学一起做的课设,我主要负责的是这部分和前端的展示设置,数据是同学爬下来的。
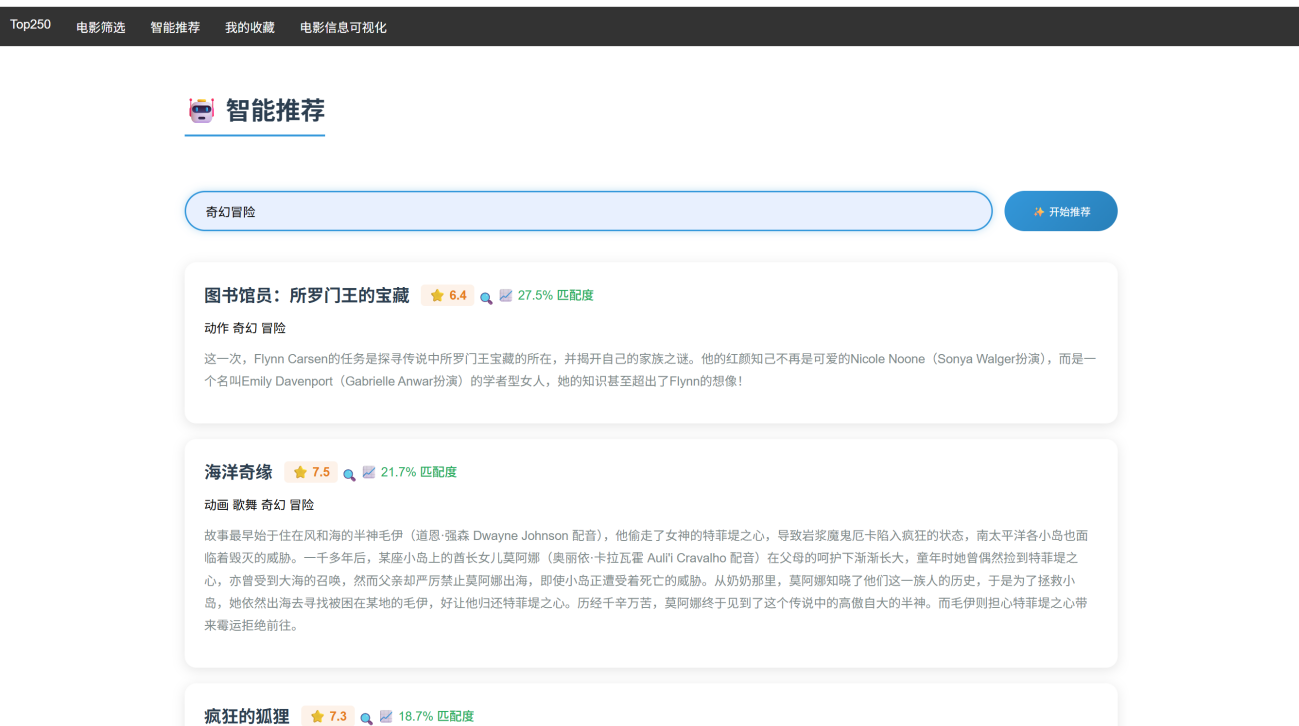
智能推荐页面展示:
1.TF-IDF算法
TF-IDF(Term Frequency - Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用加权技术。它通常用于评估一个词语对于一个文档集或一个语料库中的其中一份文档的重要性。其基本原理是:如果某个词语在某一份文档中出现的频率高,并且在其他文档中很少出现,则认为此词语具有很好的类别区分能力,适合用来分类。
(1)TF(词频)
定义:词频是一个词在文档中出现的次数。这个数字通常会被标准化(通常是词频除以文档中词语总数),以防止它偏向长的文档。(例如,某个词在长文档中可能会比短文档中出现次数更多,即使该词对于两个文档的重要性相同)。
计算公式:假设一个文档 d 中有 N 个词,词 t 在文档 d 中出现的次数是 f(t,d),那么词频 TF(t,d) 可以表示为:
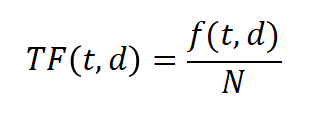
(2)IDF(逆文档频率)
定义:逆文档频率是一个词语普遍重要性的度量。它是通过将语料库中的文档总数除以包含该词语之文档的数目,然后将得到的商取对数得到的。
计算公式:假设语料库中有 M 篇文档,包含词 t 的文档数为 df(t),那么逆文档频率 IDF(t) 可以表示为:
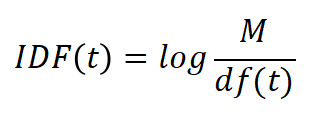
定义:TF - IDF值是词频和逆文档频率的乘积。它综合考虑了词语在文档中的重要性和词语在整个语料库中的区分能力,计算公式为:
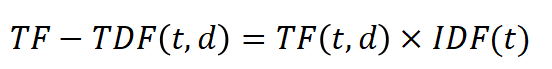
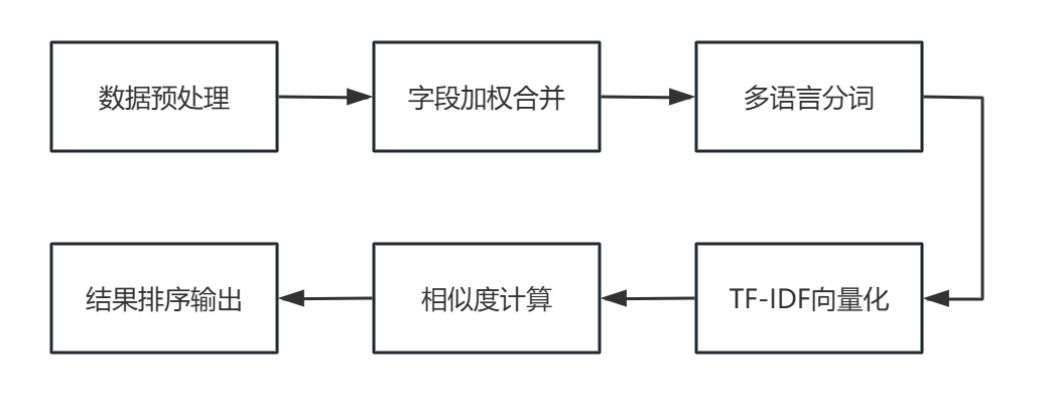
整体架构如图所示:
后面的实现只展示关键代码(其实是把课设论文直接复制过来了,原谅是在准备期末考试的间隙摸鱼写的)最后面放的有完整的代码。
2.加载停用词
首先从开源网站获得中文停用词库,使用UTF-8加载中文停用词表,额外添加补充英文停用词,构建多语言停用词库,并对集合操作去重,优化查询效率。
通过过滤掉无实际意义的词汇,提升特征质量。停用词加载的代码如下:
# 加载中文停用词
with open('stopwords-zh.txt', 'r', encoding='utf-8') as f:
STOPWORDS = set([line.strip() for line in f])
# 添加基础英文停用词
extra_stopwords = {
'the', 'and', 'of', 'to', 'in', 'a', 'is', 'that', 'it', 'with', 'as', 'for',
'on', 'are', 'this', 'be', 'by', 'or', 'at', 'was', 'an', 'not'
}
STOPWORDS.update(extra_stopwords)3.权重设置
对于电影名称和标签等重要的关键字,通过重复拼接,实现特征加权,强调电影名称的关键性,突出标签的分类,增加关键字段在TF-IDF计算中的影响力。
def build_weighted_content(row):
return ' '.join([
str(row["NAME"]) * 3,
str(row["TAGS"]) * 2,
str(row["ACTORS"]),
str(row["DIRECTORS"]),
str(row["GENRES"]),
str(row["STORYLINE"])
])
df["CONTENT"] = df.apply(build_weighted_content, axis=1)4.多语言分词
通过观察数据可知,有中文、日文和英文三种语言的数据,因此不能采用单一的形式进行处理。在算法中设计了用于处理中文、日文和英文混合文本的分词器。首先,对文本进行清洗,保留中文、日文平假名和片假名,保留英文字母且消除大小写差异,保留数字。非上述字符统一替换为空格。
然后对文本进行分割,使用正则表达式,匹配多个连续的指定字符并分割成组,分离中文、英文、日文和数字为一个个词块。分离方式为根据中日文块和非中日文块,因为对于非中日文块可以采用空格分割,但对于中日文块则采用特定的方式分割。
对于中文采用jieba.lcut进行精准分词,jieba是一个中文分词库,用于将连续的中文切分成词语,jieba.lcut则会返回一个包含所有分词的列表。
对于日文按照字符粒度拆分,即按照字符逐个分割,对于英文则选择按照空格进行分词。
def multilingual_tokenizer(text):
# 清洗:保留中日文字符、英文字母、数字
text = re.sub(
r'[^\u4e00-\u9fa5\u3040-\u309F\u30A0-\u30FFa-zA-Z0-9]',
' ',
text
).lower()
# 分割中日文和非中日文部分
chunks = re.split(r'([\u4e00-\u9fa5\u3040-\u309F\u30A0-\u30FF]+)', text)
tokens = []
for chunk in chunks:
chunk = chunk.strip()
if not chunk:
continue
# 中日文字符处理
if re.match(r'^[\u4e00-\u9fa5\u3040-\u309F\u30A0-\u30FF]+$', chunk):
if re.match(r'^[\u4e00-\u9fa5]+$', chunk):#中文
tokens.extend(jieba.lcut(chunk))
else:
tokens.extend(list(chunk))#日文
# 非中日文按空格分割
else:
tokens.extend(chunk.split())
return [token for token in tokens
if token not in STOPWORDS and len(token) > 1]# 过滤停用词和短词5.TF-IDF向量化
通过from sklearn.feature_extraction.text import TfidfVectorizer调用TfidfVectorizer类计算 TF-IDF 值,类内调用文本预处理的分词器,通过ngram_range=(1, 2)提取一元语法和二元语法特征数,二元语法的加入使算法推荐时能够区分上下文,同时统计所有 n-gram和他们出现的次数,通过min_df=2仅保留至少在 2 个文档中出现的词,通过max_df=0.85忽略在 85% 以上文档中出现的常见词,设置上限10000,即选择前10000个最高频的特征。
vectorizer如下:
vectorizer = TfidfVectorizer(
tokenizer=multilingual_tokenizer,
ngram_range=(1, 2),
max_features=10000,
min_df=2,
max_df=0.85,
analyzer='word'
)余弦相似度计算
对用户输入的查询词采用同样的方式分割,然后进行向量化,将查询词的TF-IDF 向量转化为一个与词库tfidf_matrix维度一致的稀疏矩阵,然后利用cosine_similarity函数计算余弦相似度。
采用余弦相似度的优势是只关注方向,即词汇分布占比,排除了文本长度差异带来的问题,公平衡量两者的语义相关性。对结果归一化,即相似度为1表示完全相似,相似度越接近零,则表示文本之间的相关性越差。通过余弦相似度,量化了查询词与每部电影的相关性。
对于得到的结果,设置阈值,对于相似度低于0.05的电影会被过滤掉,返回满足条件的数组。
对筛选出的数组进行排序,按照相速度由高到低。当相似度相同时根据豆瓣的评分降序排序
从原始的数据中获取相关列,并加入相似度后进行展示。
关键代码如下:
# 预处理查询词
processed_query = ' '.join(multilingual_tokenizer(query))
# 向量化
query_vec = vectorizer.transform([processed_query])
# 计算相似度
cosine_sim = cosine_similarity(query_vec, tfidf_matrix).flatten()
# 阈值过滤
valid_indices = np.where(cosine_sim > 0.05)[0]完整代码(可在终端中运行,不带前端页面)
import pandas as pd
import jieba
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 1. 数据预处理 ==============================================================
# 加载中文停用词
with open('stopwords-zh.txt', 'r', encoding='utf-8') as f:
STOPWORDS = set([line.strip() for line in f])
# 添加基础英文停用词
extra_stopwords = {
'the', 'and', 'of', 'to', 'in', 'a', 'is', 'that', 'it', 'with', 'as', 'for',
'on', 'are', 'this', 'be', 'by', 'or', 'at', 'was', 'an', 'not'
}
STOPWORDS.update(extra_stopwords)
# 2. 数据加载与字段加权 =======================================================
df = pd.read_csv("movies.csv")
# 定义字段权重
def build_weighted_content(row):
return ' '.join([
str(row["NAME"]) * 3,
str(row["TAGS"]) * 2,
str(row["ACTORS"]),
str(row["DIRECTORS"]),
str(row["GENRES"]),
str(row["STORYLINE"])
])
df["CONTENT"] = df.apply(build_weighted_content, axis=1)
# 3. 多语言分词器 ============================================================
def multilingual_tokenizer(text):
# 清洗:保留中日文字符、英文字母、数字
text = re.sub(
r'[^\u4e00-\u9fa5\u3040-\u309F\u30A0-\u30FFa-zA-Z0-9]',
' ',
text
).lower()
# 分割中日文和非中日文部分
chunks = re.split(r'([\u4e00-\u9fa5\u3040-\u309F\u30A0-\u30FF]+)', text)
tokens = []
for chunk in chunks:
chunk = chunk.strip()
if not chunk:
continue
# 中日文字符处理
if re.match(r'^[\u4e00-\u9fa5\u3040-\u309F\u30A0-\u30FF]+$', chunk):
if re.match(r'^[\u4e00-\u9fa5]+$', chunk):#中文
tokens.extend(jieba.lcut(chunk))
else:
tokens.extend(list(chunk))#日文
# 非中日文按空格分割
else:
tokens.extend(chunk.split())
return [token for token in tokens
if token not in STOPWORDS and len(token) > 1]# 过滤停用词和短词
# 4. TF-IDF向量化 ===========================================================
vectorizer = TfidfVectorizer(
tokenizer=multilingual_tokenizer,
ngram_range=(1, 2),
max_features=10000,
min_df=2,
max_df=0.85,
analyzer='word'
)
tfidf_matrix = vectorizer.fit_transform(df["CONTENT"])
# 5. 搜索函数 ================================================================
def search_movies(query, top_n=5):
# 预处理查询词
processed_query = ' '.join(multilingual_tokenizer(query))
# 向量化
query_vec = vectorizer.transform([processed_query])
# 计算相似度
cosine_sim = cosine_similarity(query_vec, tfidf_matrix).flatten()
# 阈值过滤
valid_indices = np.where(cosine_sim > 0.05)[0]
if len(valid_indices) == 0:
return pd.DataFrame(columns=["NAME", "DOUBAN_SCORE", "GENRES", "STORYLINE", "similarity"])
# 二次排序(相似度+评分)
sorted_indices = sorted(
valid_indices,
key=lambda x: (cosine_sim[x], df.iloc[x]["DOUBAN_SCORE"]),
reverse=True
)[:top_n]
# 构造结果
results = df.iloc[sorted_indices][["NAME", "DOUBAN_SCORE", "GENRES", "STORYLINE"]].copy()
results["similarity"] = cosine_sim[sorted_indices]
return results
# 6. 主程序 =================================================================
if __name__ == '__main__':
# 示例搜索
query = input("请输入搜索关键词:")
results = search_movies(query)
print(f"\n找到 {len(results)} 个相关结果:")
for i, row in results.iterrows():
print(f"""
[{i+1}] {row['NAME']}(评分:{row['DOUBAN_SCORE']})
类型:{row['GENRES']}
相似度:{row['similarity']:.3f}
剧情:{row['STORYLINE'][:80]}...""")感谢阅读,欢迎收藏!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









