










 本文详细介绍了如何通过自定义Apollo配置实现灰度发布,包括环境准备、数据库配置、源码修改及打包流程,适用于需要精细化配置发布策略的场景。
本文详细介绍了如何通过自定义Apollo配置实现灰度发布,包括环境准备、数据库配置、源码修改及打包流程,适用于需要精细化配置发布策略的场景。
问题
由于最近公司要弄灰度发布,所以需要添加一套Apollo配置,默认是可以管理 dev, fat, uat, pro四套环境,但是我们想自定义一下环境,所以就尝试一下自定义环境,需要自己修改源码然后自己编译打包
如果默认的四套环境能够满足自己需求,就可以直接使用官网提供的包,我们只需修改数据库配置和环境信息即可使用
下载地址:https://github.com/ctripcorp/apollo/releases(自己定制的不需要下载)
使用目前最新版本 apollo-1.1.2
环境准备
- Java环境,JDK1.8或者以上(刚需)
- Mysql数据库,版本5.6.5以上(刚需)
- 下载Apollo源码:https://github.com/ctripcorp/apollo(自己定制的需要下载)
数据库准备
执行SQL语句,创建数据库
(portal库只需要创建一个,因为一个portal可以管理多个config,config数据库需要建立多个,因为一套环境需要一个独立的数据库,所以创建config库的时候,要去脚本修改数据库名称,图2是建好之后的数据库)

修改数据库配置
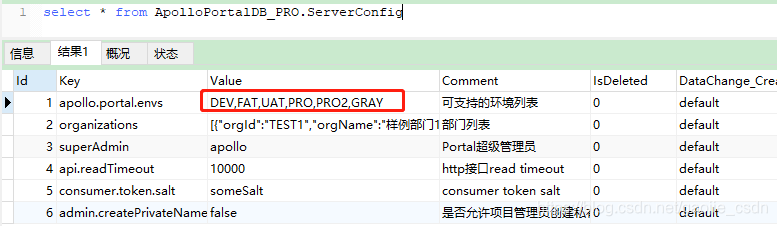
- 修改 portal 库的 ServerConfig 表,默认只管理 dev,可配置多套环境,逗号隔开
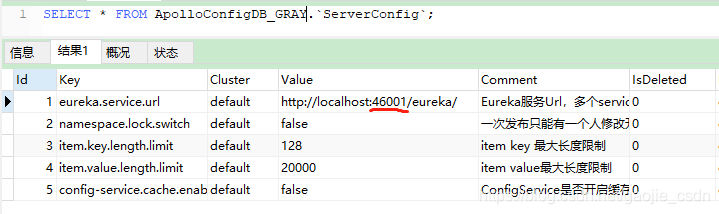
- 修改 config 库的 ServerConfig 表,修改端口号,由于默认是8080,但是我需要在一台机器上部署多个config,所以修改端口号避免冲突,也便于管理(此处演示的是 dev,是系统默认自带的环境dev,uat,fat,pro之一,所以只演示一个)

- 修改自定义环境的 config 库的 ServerConfig 表,修改和上面操作一样
修改源码(自己定制的需要,不定制的可忽略)
修改的时候最好导入到 idea 里面操作,这样会很方便,而且还便于后续测试,也便于看源码
- 假设需要添加的环境名称叫 beta
- 修改com.ctrip.framework.apollo.core.enums.Env类,在其中加入
BETA枚举:
- 修改com.ctrip.framework.apollo.core.enums.EnvUtils类,在其中加入
BETA枚举的转换逻辑: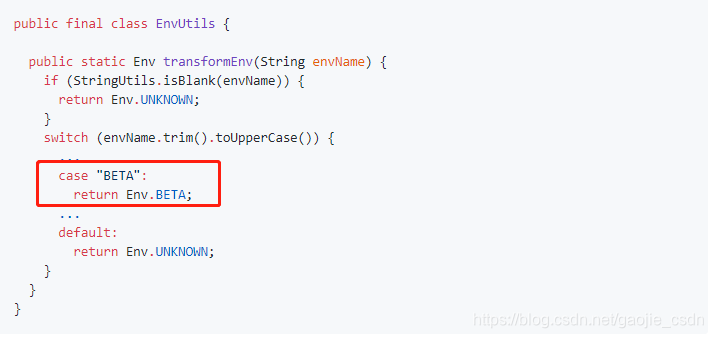
- 修改apollo-env.properties,增加
beta.meta占位符: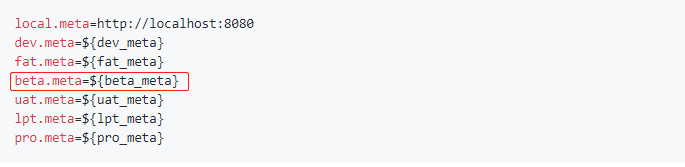
- 修改com.ctrip.framework.apollo.core.internals.LegacyMetaServerProvider类,增加读取
BETA环境的meta server地址逻辑: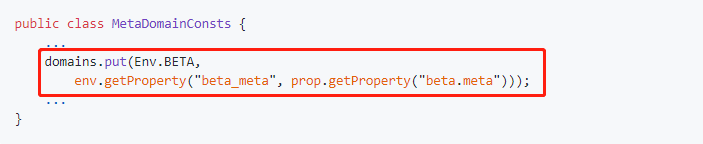
修改打包脚本(自己定制的需要,不定制的可忽略)
此处去除了 config 的数据库连接配置,因为不同环境对应的数据库不同,所以打包后修改配置文件即可
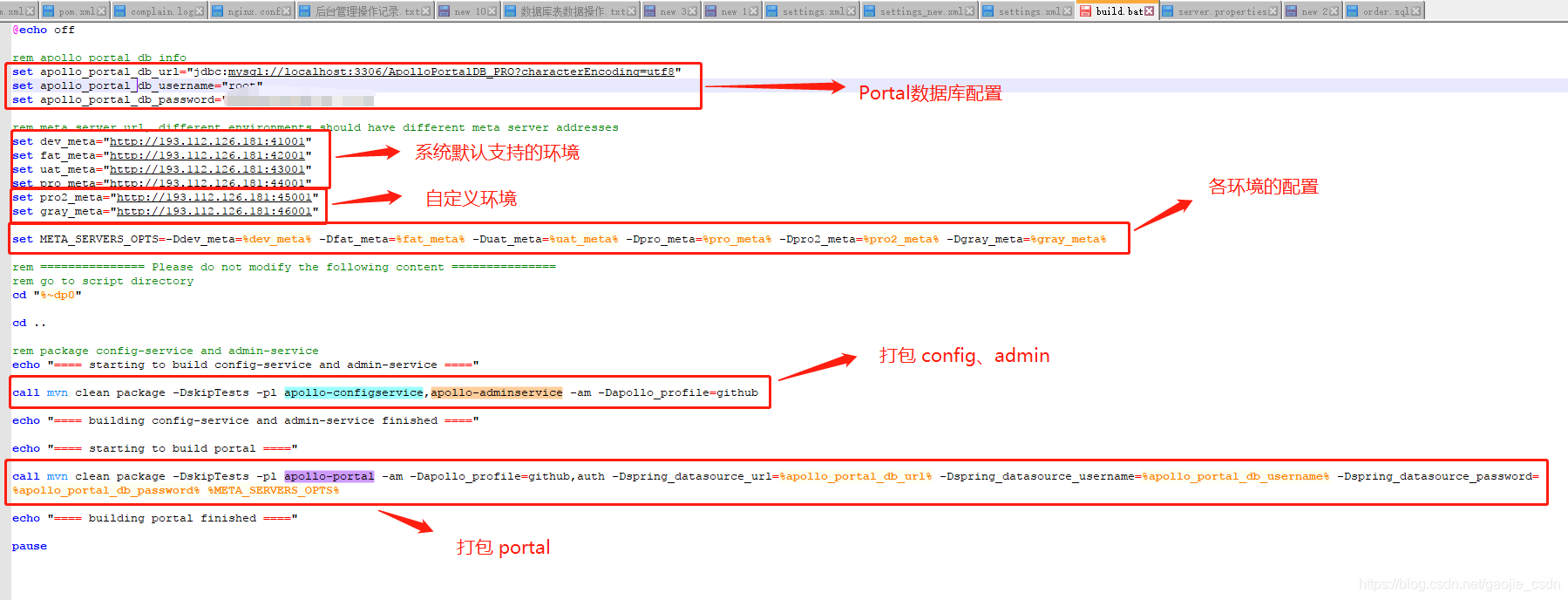
开始打包(自己定制的需要,不定制的可忽略)
由于第一次编译打包会下载很多文件,所以会比较慢,建议连接 阿里的中央仓库,速度会快很多,在mirrors节点下添加
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror> 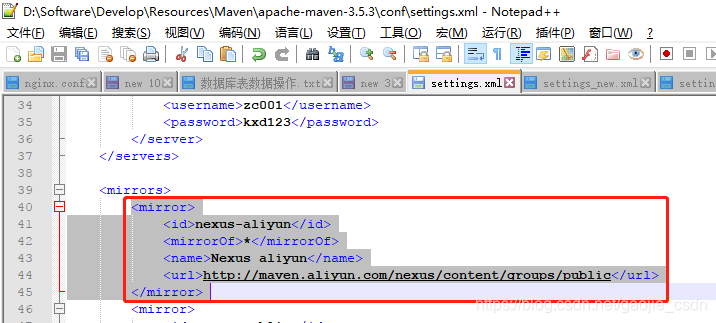
修改好配置之后,双击 build.bat 开始打包,等待几分钟,控制台最后会提示打包完成
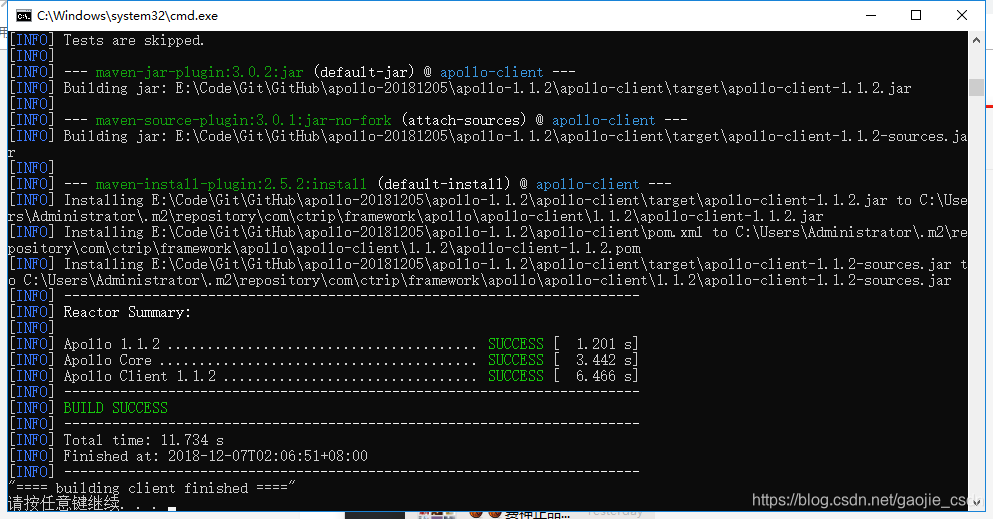
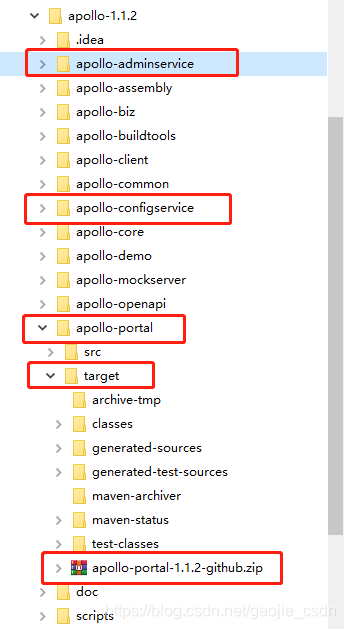
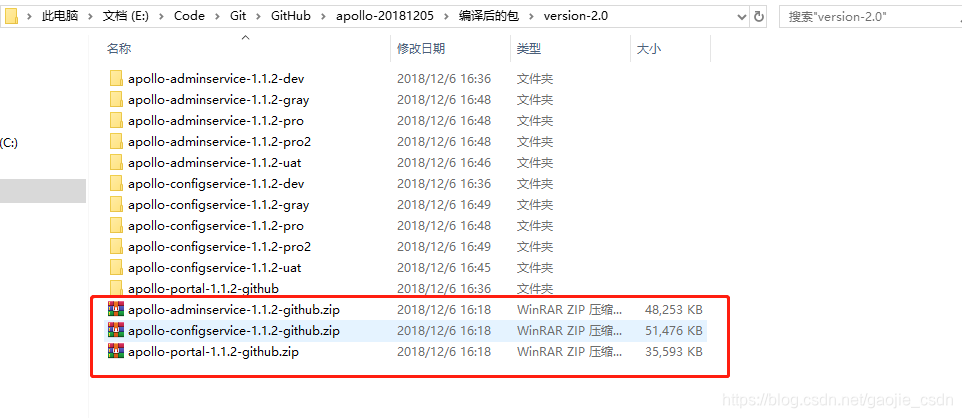
然后找到 admin、config、portal 对应的.zip包,然后再解压,修改配置,再上传到服务器,就可以部署我们的 apollo 服务了
修改配置 Portal
- apollo-portal-1.1.2-github\scripts\startup.sh 修改端口号,自定义,只要不冲突就行
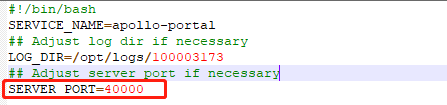
- apollo-portal-1.1.2-github\config\application-github.properties portal 数据库配置(打包时已输入,则此处无需修改)

- apollo-portal-1.1.2-github\config\apollo-env.properties portal管理的环境配置(打包时已输入,则此处无需修改)

修改配置 Config(以dev为例,每个环境都是一样的)
- apollo-configservice-1.1.2-dev\scripts\startup.sh 修改端口号,自定义,只要不冲突就行
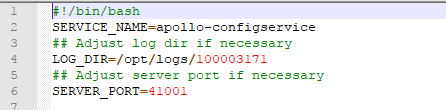
- apollo-configservice-1.1.2-dev\config\application-github.properties config的数据库配置(根据不同环境配置不同)

- apollo-configservice-1.1.2-dev\config\bootstrap.yml 由于是分布式部署,在云服务器上就有可能出现内网和外网IP的问题,所以此处需要指定IP,以免出现访问不到的问题(文件是由源码复制出来修改的)
eureka: instance: ip-address: 193.112.126.181 preferIpAddress: true client: serviceUrl: defaultZone: http://${eureka.instance.hostname}:41001/eureka/ healthcheck: enabled: true eurekaServiceUrlPollIntervalSeconds: 60 endpoints: health: sensitive: false management: security: enabled: false health: status: order: DOWN, OUT_OF_SERVICE, UNKNOWN, UP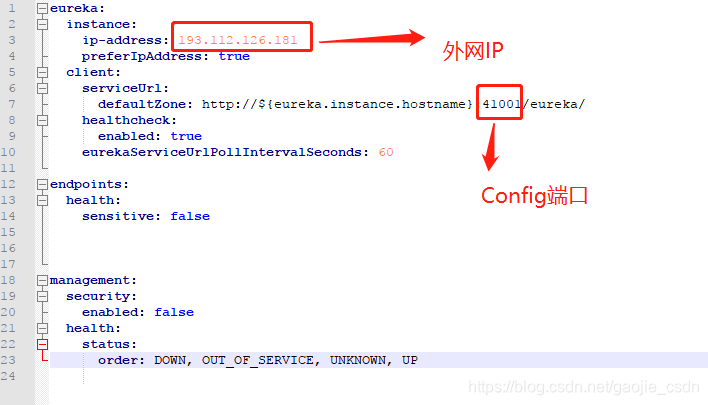
修改配置 Admin(以dev为例,每个环境都是一样的)
- apollo-adminservice-1.1.2-dev\scripts\startup.sh 修改端口号,自定义,只要不冲突就行
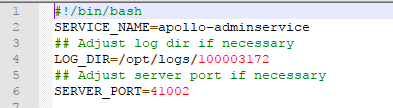
- apollo-adminservice-1.1.2-dev\config\application-github.properties 与config一致
- apollo-adminservice-1.1.2-dev\config\bootstrap.yml 与 config 类似,不同的是端口号不同
部署
- 本地修改后的包,portal只有一份,config和admin一对一,可以有多份
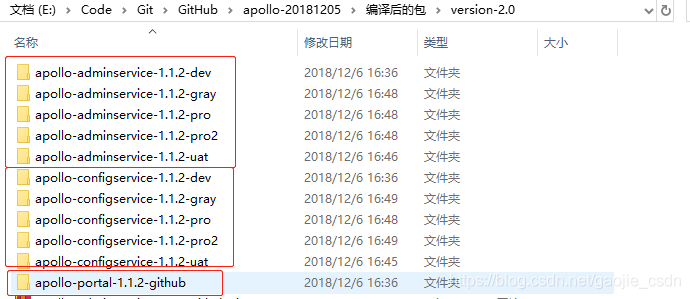
- 将修改好配置的包全部上传到服务器 放到指定文件夹,位置随意,目的是方便管理
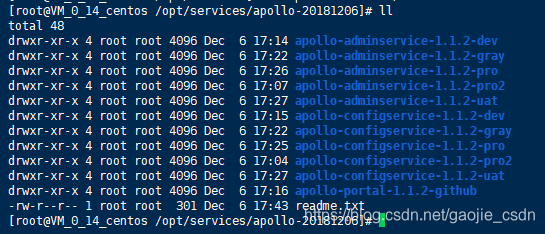
- 然后修改每个startup.sh,shutdown.sh的权限,默认只有读写权限,没有执行权限

chmod -R 755 startup.sh chmod -R 755 shutdown.sh - 启动服务 到各个目录下,运行 ./startup.sh,若全部启动成功则表示服务已经启动成功。若出现报错,则可以根据提示去指定路径查看错误日志
- 启动成功后就可以去portal访问了,如果是云服务器可能需要自己开放端口号,默认密码 apollo / admin

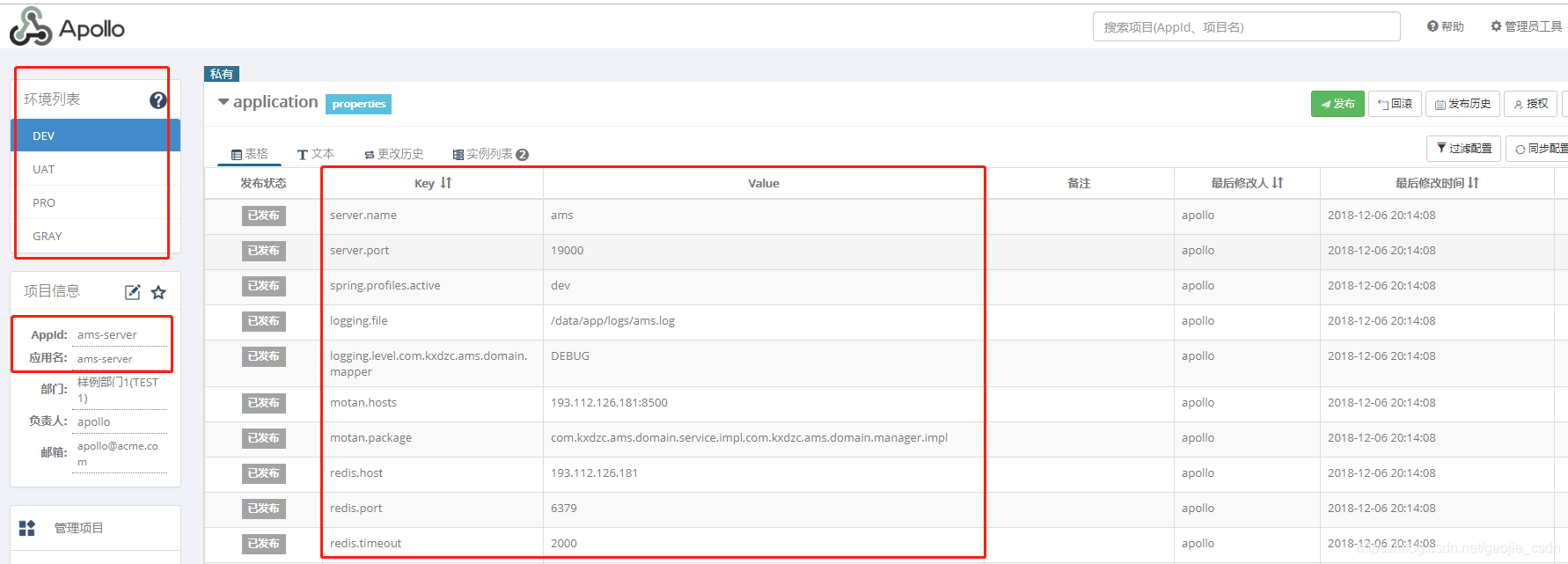
- 登陆成功后,能看到管理的环境列表,自己可以创建工程,配置参数,发布等功能
客户端访问服务
- opt/settings/server.properties 若为window系统,则是c:/opt/settings/server.properties; 若为Linux系统,则配置 /opt/settings/server.properties;之前老版本使用的 env=PRO(环境的名称,在打包文件 build.bat 里面定义的)的方式,现在直接配置最后一行即可,地址为想要连接环境的 IP + Port,我的41001对应的为 dev 环境

- 在项目中,app.properties 文件中,设置app.id,与 portal 创建的 AppId 一致
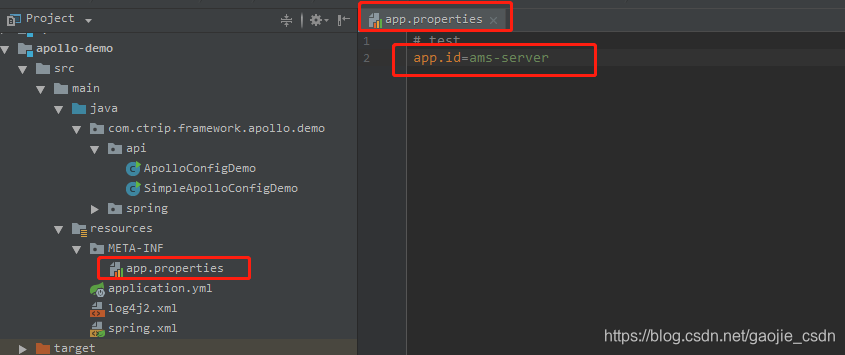
- 启动 SimpleApolloConfigDemo,然后输入 key,获取 value,获取值为portal所配置,到此为止客户端访问成功。具体原理需要自己去看源码了,可以参考 Java客户端使用指南https://github.com/ctripcorp/apollo/wiki/Java%E5%AE%A2%E6%88%B7%E7%AB%AF%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97


















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









