






点击蓝色字关注 "数据库技术大会" 一起玩耍哦~
本文根据蔡松露老师在2018年5月10日【第九届中国数据库技术大会(DTCC)】现场演讲内容整理而成。

蔡松露 阿里云云数据库资深技术专家、架构师
阿里云云数据库架构师,主要负责阿里云POLARDB、NoSQL技术以及阿里云数据库整体架构等工作。在搜索引擎、NoSQL数据库、分布式系统、操作系统内核等领域有深厚积累与丰富的经验。
摘要:从架构、产品设计、未来工作等方面全方位阐述下一代云原生数据库POLARDB。
POLARDB架构图

今天主要给大家介绍一下POLARDB。POLARDB是什么?是一个云原生数据库,前一段时间,我们在巴黎的ICDE 2018大会上,对云原生这个标准做了一些阐述,今天将从架构和产品设计方面,给大家讲一下POLARDB的具体实现。
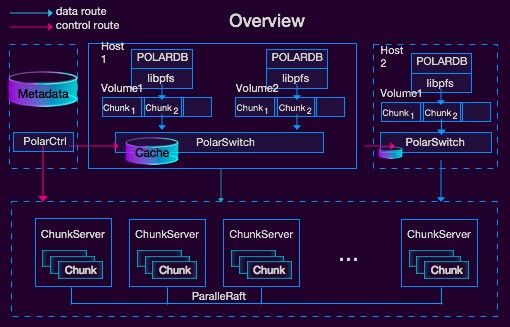
上面这个是POLARDB的架构图,蓝色的线是数据流,红色的线是控制流,控制流是主要负责POLARDB里各个进程生命周期的管理,数据流顾名思义就是一个请求进来,数据在整个系统里的一个流转过程。
我们在设计POLARDB时,遵循四个原则:
1、 存储计算分离
2、 全用户态,0拷贝
3、 ParellelRaft,支持乱序提交
4、 大量使用新硬件
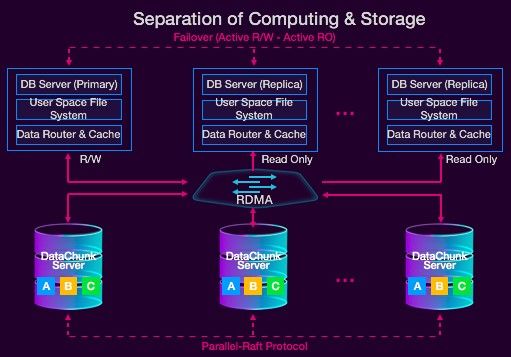
大家可以看到,我们上层是计算层,下层是存储层,存储和计算分离,中间通过RDMA高速网络相连接,
在计算层,有一个主节点,这个主节点负责读写请求,其余是备节点,备节点也是只读节点,只负责接收读请求。存储计算分离的好处,第一;存储计算分离了之后,相当于将原来一体化的架构做了水平的切分,切成了两层。这两层,以前,你必须要用相同的硬件,现在,你可以根据这两层不同的特点定制不同的硬件和策略。
例如,在计算层更关注的是什么? CPU+内存。在存储层更关注什么?可能并不是很CPU和内存,而是IO的响应时间和成本。所以,这两层差别很大。而这种差别会带来新的技术红利,我们可以把这个红利释放给用户。
另外,存储计算分离之后,计算层不持有数据,所以能很方便的做各种迁移。在存储层,POLARDB的存储是一个分布式的文件系统,这个分布式文件系统可以有自己的复制策略。但在以前,大一统的架构下,这件事是没有办法做的。因为,你在存储做策略,可能会干扰计算,你为计算制定策略,就可能干扰到存储。而现在,存储分离之后,存储可以做池化,池化的一个好处就是它没有碎片,也不会有不均衡的情况存在。如果有一些不均衡或热点,存储层也能自主地做一些迁移工作。你想象一下,在传统的方案中,以现在的RDS为例,有的机器上面可能有个大实例,有的机器上可能是小实例,很可能会出现一种情况,就是大实例把磁盘都快用光了,小实例所在的机器磁盘用的还不到1%,过去,你没办法去解决这种问题。但存储池化之后,这些问题完全都烟消云散了。
而且,存储计算分离之后,可以很方便地去做Serverless。这在存储计算没有分离之前,Serverless是没法做的。计算层怎么做一个临时的容器,那不可能的,因为数据都在一起。
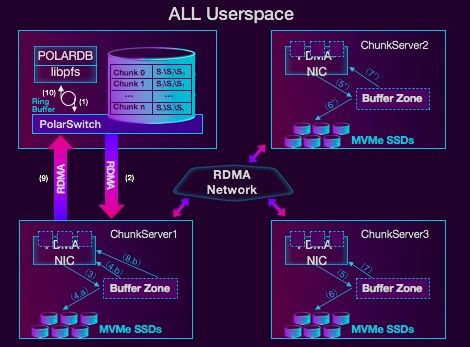
全用户态架构,我们有用户态的分布式文件系统(libpfs),我们有自己的polarswitch,这是一个类似本地的网关。我们有用户态的IO栈,用的是开源的SPDK,还有一个用户态的网络RDMA。
全用户态带来收益非常大,POLARDB性能的提升,高于某些友商,一个很重要的原因,就是来自于这种全用户态架构和对新硬件的利用。
我们之前做过一个测试,在Linux上一次进程切换,成本大概是在20-30微秒左右,但是在一个RDMA网络里面,一次RDMA请求可能7-10微秒,所以一次进程切换,其实都够访问三次RDMA了。所以,这个差别是非常大的。POLARDB在存储层写三副本通过RDMA,三副本写完之后,可能就20-30微秒,这20-30微秒和一次进程切换的成本其实是相当的。所以通过消除这种进程切换,还有内存拷贝带来的收益是非常巨大的。

上图是POALRDB文件系统-PFS的一个详细介绍。这里,我就不详细地说了,大家如果关注,我们有两篇论文,有一篇是讲这个分布式文件系统,会在今年的VLDB 2018上会对外公开,这个文件系统的特点是什么,它是POSIX的一个API,对DB层的侵入很小。
回到存储层,POLARDB用的是三副本,采用ParellelRaft来同步三份数据,ParellelRaft是Raft的变种,比Raft更高效。Raft不允许乱序提交和日志空洞,这些限制让Raft性能比较低、吞吐比较小,ParellelRaft允许乱序提交,而乱序的好处就是它带来吞吐量几乎会翻番。
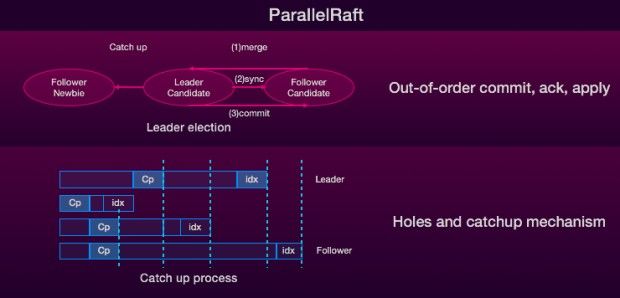
大家可能会问,底层存储这么做,上层事务的语义怎么去保证?我们事务的语义主要是靠DB层自己来保证的。比如说,DB层有一个事务有很多IO,这些IO可能在底层完全是乱序执行的,但是当你事务提交时,DB层要保证这些IO都是已经成功了。
对于空洞,我们有一整套完整的catch-up机制,这是一个非常复杂的过程,在VLDB 2018的论文中,我们有详细论述,这篇论文刚被接收。
我们也用到了大量的新硬件,刚才提到了RDMA还有3D X Point,我们现在也正在研究那个Open-Channel SSD,虽然是工业化很多年了,现在应该主流的存储机上都是SSD,但是对SSD应用,目前还是有蛮多问题的。因为SSD软件和硬件并不是是非常匹配,导致我们对SSD的使用是浪费的,这种浪费一个是来自性能,还有一个是来自寿命。
通常Open-Channel SSD的方式,就是IO性能还有寿命最终反映到我们的成本上,都会比以前有一个较大的提升。

这是我们自家POLARDB和RDS的对比压测结果,通过这张图可以看出,POLARDB的平均读性能是RDS的6倍左右,平均写性能是RDS的3倍左右,当然我们这个性能还在持续提升。我们最新的一个版本应该比这个还要再涨个30—40%。
POLARDB产品设计的五个维度


接下来,讲一下产品设计的特点。我们主要从五个维度去设计我们的产品。
第一个是性能,性能上可以很方便的扩展到上百万的QPS,而且RT很低,我们是小于等于2毫秒。存储很方便的扩展到100TB,也可以很方便的去缩回来。
第二个是弹性,在版本升级、规格升降配的时候,尽量做到零宕机。在存储层还有计算层很方便的做这种Scale up Scale out。
第三个是兼容性,目前我们是100%兼容MySQL 5.6的
第四个是可用性,目前我们承诺可用性是99.95%,
第五个是可靠性,目前承诺的是5个9。
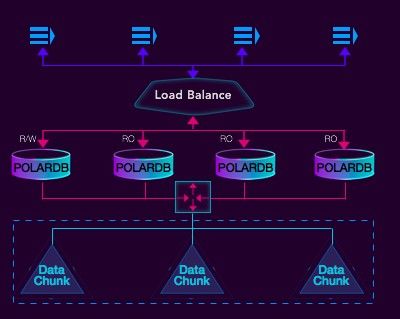
在POLARDB中,可用性方面,读和写被分离到不同的节点上,只有一个写节点,写节点可以处理读写请求,其他的节点都是只读节点,只读节点可以很方便的去做Scale out,写节点也可以很方便的做Scale up,写QPS最多可达13W,读QPS可以很方便地扩展到几百万。
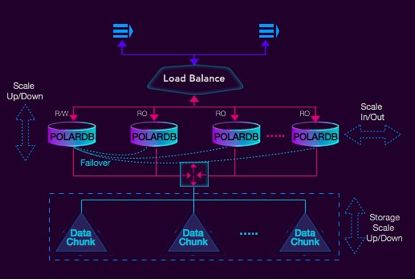
对于扩展性,所有节点都可以做纵向扩展,只读节点可以做横向扩展,实例的存储可以做纵向扩展,存储集群可以做横向扩展,当读写节点和只读节点之间做failover时可以做到0宕机。
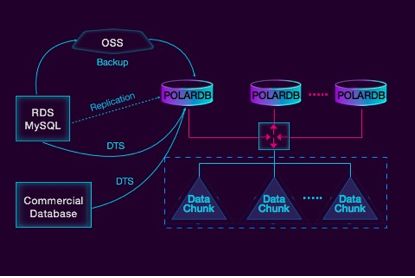
数据迁移,POLARDB数据是怎么迁移,假设你是一个RDS的用户,你可以先备份到OSS,然后在POLARDB实例里面加载OSS上的备份数据,新生成一个POLARDB的实例。
你也可以通过DTS(data transfer service数据传输服务)做数据的实时迁移。未来我们还能提供一个方式,将POLARDB做成一个slave,直接挂到RDS的节点,实时复制数据。
如果你是用的第三方的商用的数据库,这种情况我建议你走DTS。因为DTS支持的数据库类型还是非常全的。
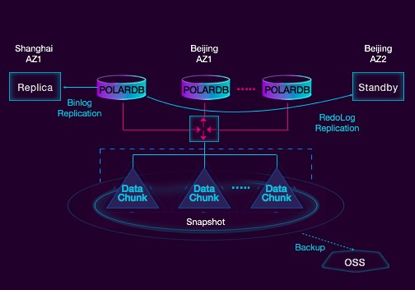
对于数据可靠性,我们可以做到1个region内可用区内多个可用区之间的failover,你可以在其他可用区启动一个standby实例并且使用redolog来进行复制,也可以在多个region之间failover,我们通常使用binlog进行复制,对于备份,我们可以秒级打出一个snapshot然后上传到OSS上。

下面是POLARDB的一些未来工作,在引擎层,目前大家看到的可能只有一个单点写入节点,未来我们将会支持多写,其次,我们还会引入一些新的组件。比如:Cache Fusion,通过Cache Fusion最大提升计算层的性能。未来,我们会支持更多的数据库类型,比如,MySQL 5.7,PostgreSQL、DocumentDB等。这些工作现在已经开始在做了。
在存储层,我们会使用3D XPoint技术来提升IO性能,我们也会通过open-channel技术在提升SSD性能,将来我们也会将更多引擎层的逻辑进行下推,尽量减少更多的IO,让计算层更加简单。

















 2734
2734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









