







 PolarDB是阿里云的云原生数据库,采用计算与存储分离的架构,利用PolarFS分布式文件系统实现高可用和高性能。PolarFS通过Volume、Chunk和Block进行存储资源管理,使用全用户态的libpfs、PolarSwitch、ChunkServer等组件处理IO请求,并基于ParallelRaft协议实现乱序日志复制,提高系统吞吐量。此外,PolarFS使用PolarCtrl进行集群管理和元数据同步,确保数据一致性。
PolarDB是阿里云的云原生数据库,采用计算与存储分离的架构,利用PolarFS分布式文件系统实现高可用和高性能。PolarFS通过Volume、Chunk和Block进行存储资源管理,使用全用户态的libpfs、PolarSwitch、ChunkServer等组件处理IO请求,并基于ParallelRaft协议实现乱序日志复制,提高系统吞吐量。此外,PolarFS使用PolarCtrl进行集群管理和元数据同步,确保数据一致性。
PolarDB及其分布式文件系统PolarFS的架构实现
PolarDB是阿里云基于MySQL推出的新一代云原生(Cloud Native)数据库产品,所谓云原生数据库,指的是一种融合了众多创新技术而跨界的云数据库服务,它可以更好地服务于云环境下的应用场景,本质上是云的能力和SQL能力的融合。
因为PolarDB并不开源,所以我们不能从代码层面进行解读,只能从阿里云公开的技术资料以及他们在VLDB 2018上发表的分布式文件系统PolarFS(PolarDB的共享存储文件系统)的论文基础上进行解读和分析。
云原生数据库出现的背景
在云原生数据库出现之前,传统的MySQL RDS已经在云服务上有了尝试,但是在尝试过程中,出现了很多传统MySQL RDS无法解决的痛点问题,比如说:
- 扩展困难。传统MySQL不管是纵向扩展机器硬件,还是横向增加备库都需要迁徙数据,扩展周期比较长,无法从容应对突如其来的业务高峰,这使得数据库服务不能服务于那些负载不确定的应用。
- 成本浪费。传统MySQL的只读库需要拥有一份与主库完全相同的数据副本,用户想要增加只读库的数目,不仅要增加计算成本还要增加存储成本。
- 主从切换时间长。传统MySQL通常采用主从异步复制的HA架构,主从切换后从库可能需要重建,导致切换时间太长,数据库系统长时间不可用。
- 复制延迟高。传统MySQL的读写分离通常采用redolog来进行主从复制,但是这种逻辑复制延迟较高,备库常常会出现读延迟。
- 存储不均衡。在传统的MySQL云服务上,有些机器上可能是大实例,而有些机器上是小实例,往往大实例导致会存储资源不够用,而小实例又浪费了很多存储资源。
- binlog日志。传统的MySQL为了兼容多种存储引擎,记录了两种事务日志(binlog和redolog),binlog 逻辑复制性能较差,不同日志间的一致性管理又会影响系统的性能。
有了上面这些痛点,传统的MySQL RDS渐渐不能满足应用的需求,云原生数据库就应运而生了。
说到云原生数据库,就不得不提到AWS的Aurora数据库。其在2014年下半年发布后,轰动了整个数据库领域。Aurora对MySQL存储层进行了大刀阔斧的改造,将其拆为独立的存储节点(主要做数据块存储,数据库快照的服务器)。上层的MySQL计算节点(主要做SQL解析以及存储引擎计算的服务器)共享同一个存储节点,可在同一个共享存储上快速部署新的计算节点,高效解决服务能力扩展和服务高可用问题。基于日志即数据的思想,大大减少了计算节点和存储节点间的网络IO,进一步提升了数据库的性能。再利用存储领域成熟的快照技术,解决数据库数据备份问题。被公认为关系型数据库的未来发展方向之一。
毫无疑问,其后推出的云原生数据库产品多多少少受收到了Aurora的影响,这其中就包括本文介绍的PolarDB数据库,它也是借鉴了很多Aurora的技术实现,采用了计算和存储分离和全用户态的架构,并且大量使用新硬件。
PolarDB架构
PolarDB在进行架构设计时,遵循四个原则:
- 计算和存储分离;
- 全用户态,零拷贝;
- ParellelRaft,支持乱序确认、乱序提交。
- 大量使用新硬件:RDMA、NVMe、SPDK等等。
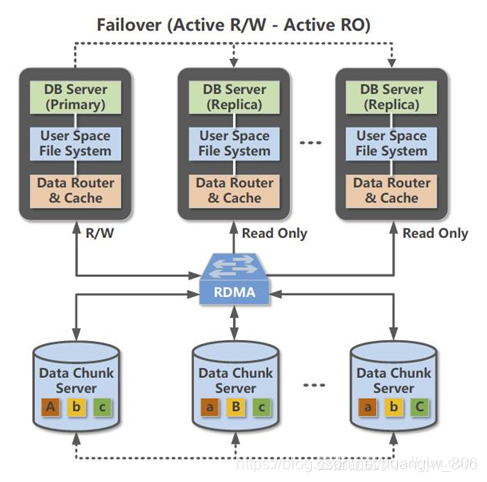
上图给出了PolarDB的架构概览,可以看到PolarDB的上层是计算层,下层是存储层,存储和计算是分离的,中间通过RDMA高速网络相连接。在计算层有一个主节点,这个主节点负责处理读写请求,其余是备节点,备节点是只读节点。主节点个所有备节点之间采用的是Shared Everything架构,即共享存储层数据和日志文件。
存储和计算分离之后,相当于将数据库系统一体化的架构做了水平的切分。这样做主要以下几点优势:
- 可以根据计算层和存储层不同的特点去配置不同的硬件和资源。在计算节点,我们更关注的是CPU和内存,而存储层更关注的则是IO的响应时间和成本。
- 存储和计算分离之后,数据库应用的持久状态下沉到存储层,计算层不持有数据,所以数据库实例可以在计算节点上灵活地做各种迁移和扩展。在存储层,PolarDB的存储是一个共享的分布式文件系统,它可以有自己的复制策略来提供较高的数据可用性和可靠性。
- 存储分离之后,存储层上的多个节点的存储资源就可以形成单一的存储池,存储资源池化能够解决传统数据库中存储碎片、节点间负载不均衡以及存储空间浪费等问题。
显然,采用存储和计算分离的架构设计可以完美解决上述传统MySQL RDS的绝大多数痛点问题。虽然存储和计算分离的好处多多,但是目前可用的分布式共享文件系统却寥寥无几,不论是Hadoop生态圈占统治地位的HDFS,还是在通用存储领域风生水起的Ceph,都不能满足数据库系统的性能需求,并且还存在大量与现有数据库系统的适配问题。
因此,想要让数据库系统实现存储和计算的分离的同时还能够具备良好的性能和可靠性,还需要针对数据库来设计专门的分布式文件系统。因此,PolarDB还专门设计了PolarFS(共享的分布式文件系统)来实现上述的存储和计算分离的架构设计。
分布式共享文件系统PolarFS
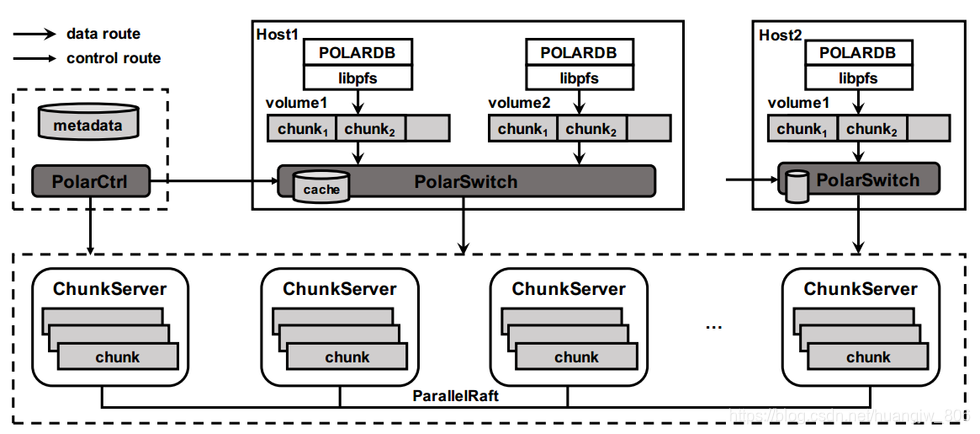
上面这张图给出了从PolarFS视角下看到的PolarDB的实现架构。简单点来看,PolarDB可以分两个部分:
- 第一部分为数据库服务(上图中的POLARDB),这部分主要是负责客户端SQL请求解析、事务处理、查询优化等数据库服务的计算操作。
- 第二部分为分布式文件系统PolarFS(上图中的libpfs、PolarCtrl、PolarSwitch、ChunkServers),主要负责数据存储、数据IO、数据一致性、元数据管理等数据库服务的存储操作。
第一部分的数据库服务是完全兼容MySQL的,这是传统数据库的知识,我们这里就不做介绍了。第二部分的分布式文件系统PolarFS则是PolarDB数据库实现存储和计算分离最重要的特性和基础,下面会针对其每一个组件进行单独介绍。
PolarFS存储资源的组织方式
在介绍PolarFS各组件的功能之前,我们先介绍一下PolarFS存储资源的组织方式。PolarFS将存储资源分为三层来进行封装和管理,分别为:Volume(卷)、Chunk(区)、Block(块)。
Volume
当用户申请创建PolarDB数据库实例时,系统就会为该实例分配一个Volume(卷),每一个数据库实例就对应一个Volume。每一个Volume由多个Chunks组成,一个Volume的容量大小范围是10GB至100TB,数据库系统可以通过向Volume添加Chunks来按需扩展数据库实例的容量。这也就是说PolarDB支持用户创建的实例大小范围为10GB至100TB,这满足了绝大多数云数据库实例的容量要求。
Volume上也存放了文件系统的元数据,这些元数据包括:
- directory entry:目录项,一个目录项保存了一个文件的路径,一个目录项中同时也包含一个inode的引用。所有目录项被组织成了一棵目录树(directory tree)。
- inode:一个inode描述的是一个常规文件或者是一个目录,这表示每一个文件名对应一个indode,不论其表示的是常规文件还是目录。对于常规文件来说,这个inode保存了一组块标记(block tag)的引用,用来指示这个文件存储在哪些块上。而对于一个目录来说,这个inode保存了该父目录中的子目录项
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3375
3375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









