










在网站的数据分析中,PV(Page View,页面浏览量)和 UV(Unique Visitor,独立访客数)是两个重要的指标,几乎每个网站都需要对其进行统计。市面上有很多成熟的统计产品,例如百度的站点统计功能,而本文将介绍如何借助 Redis 的计数器功能,实现一套属于自己的站点统计服务。
1 方案设计
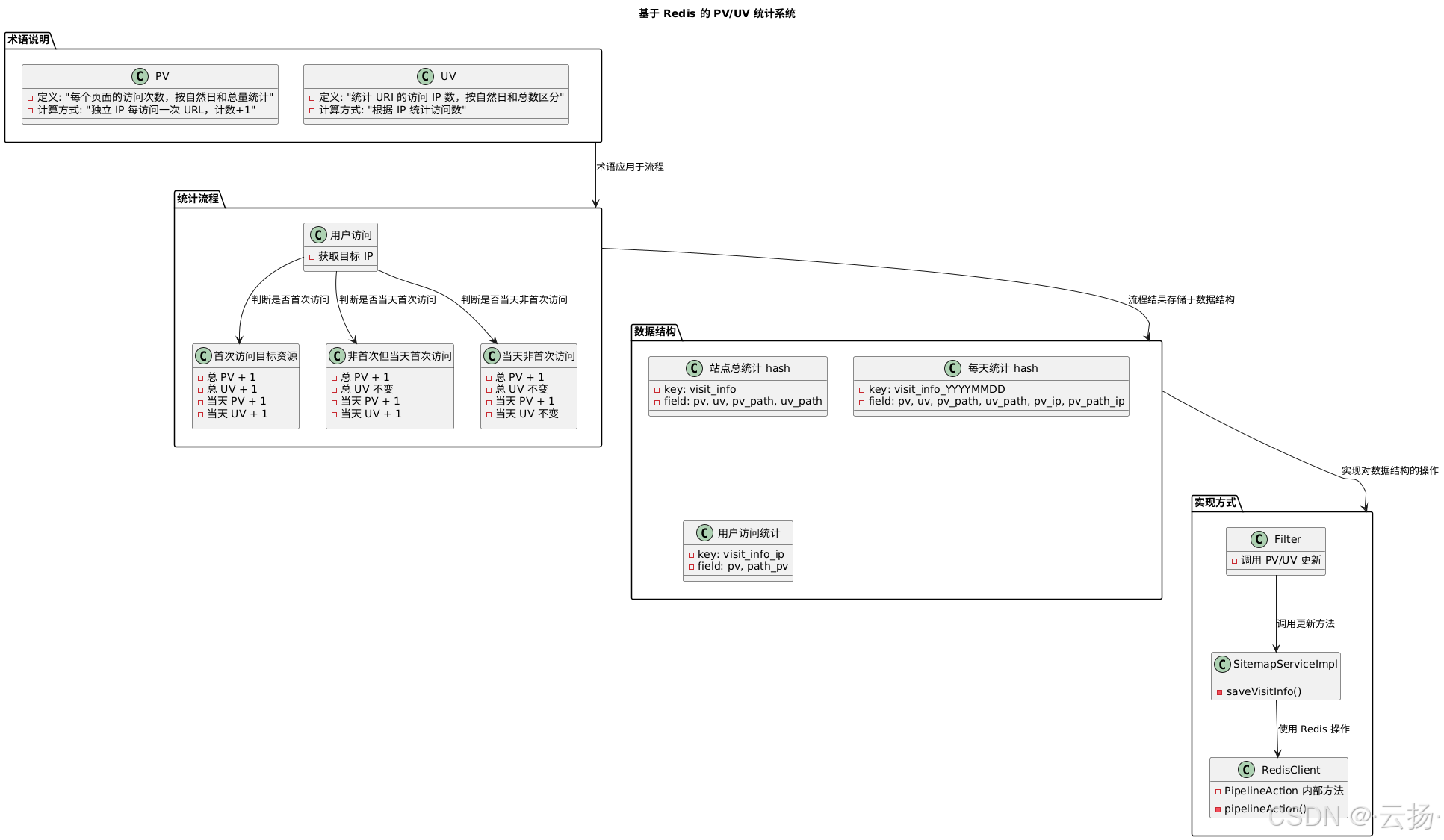
1.1 术语说明
在我们的实际实现中,对 PV 和 UV 的定义与标准定义存在一定差异:
- PV(Page View):指的是每个页面的访问次数。在本服务中,PV 是总量概念,一个独立的 IP 每访问一次 URL,对应的访问计数就加 1。我们希望按自然日统计每个 URL 的访问计数,同时也能统计总的访问计数,以此判断哪些页面更受读者喜爱。
- UV(Unique Visitor):用于统计 URI 的访问 IP 数,同样按照自然日和总数进行区分。
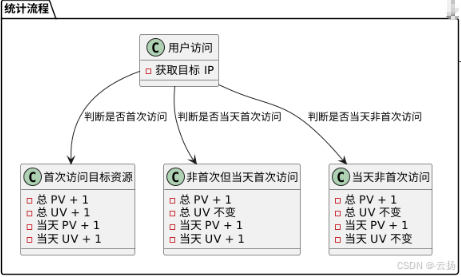
1.2 统计流程
用户访问时,首先获取目标 IP,然后根据其访问情况更新对应的计数:
- 首次访问目标资源:总 PV 加 1,总 UV 加 1;当天 PV 加 1,当天 UV 加 1。
- 非首次访问,但为当天第一次访问:总 PV 加 1,总 UV 不变;当天 PV 加 1,当天 UV 加 1。
- 当天非首次访问:总 PV 加 1,总 UV 不变;当天 PV 加 1,当天 UV 不变。
1.3 数据结构
我们使用 Redis 的 hash 来存储访问信息,具体需要存储以下三类信息:
- 站点的总访问信息:包括站点的 PV/UV,以及每个 URI 的 PV/UV。
- 某一天的访问信息:涵盖某一天站点的总访问 PV/UV,以及某一天每个 URI 的 PV/UV。由于计算 UV 时需要存储用户是否访问过某个资源的信息,所以额外添加了存储单元保存用户访问历史。
- 用户的访问信息:包含用户访问站点的总次数,以及访问每个 URI 的总次数。用户每天的访问信息存储在每天的访问信息结构中,因为每天的访问信息通常不需要持久化保存,比如只存储最近一个月的情况,可设置 Redis 的有效期为 30 天,到期自动清除。
完整的 hash 定义如下:
- 站点总统计 hash:
- key:visit_info
- field:
- pv:站点的总 PV
- uv:站点的总 UV
- pv_path:站点某个资源的总访问 PV
- uv_path:站点某个资源的总访问 UV
- 每天统计 hash:
- key:visit_info_20230822(每日记录,一天一条记录)
- field:
- pv:12(field = 月日_pv,PV 的计数)
- uv:5(field = 月日_uv,UV 的计数)
- pv_path:2(资源的当前访问计数)
- uv_path:资源的当天访问 UV
- pv_ip:用户当天的访问次数
- pv_path_ip:用户对资源的当天访问次数
- 用户访问统计:
- key:visit_info_ip
- field:
- pv:用户访问的站点总次数
- path_pv:用户访问的路径总次数

2 实现方式
2.1 统计计数
核心计数的实现路径为 com.github.paicoding.forum.service.sitemap.service.SitemapServiceImpl#saveVisitInfo。其原理是:用户站点总 PV 加 1,若返回的最新计数是 1,表示是站点的新用户,所有 UV 加 1;今日 PV 加 1,若返回的最新计数是 1,表示当前用户今日首次访问,进入的 UV 加 1 。
/**
* 保存站点数据模型
* <p>
* 站点统计hash:
* - visit_info:
* ---- pv: 站点的总pv
* ---- uv: 站点的总uv
* ---- pv_path: 站点某个资源的总访问pv
* ---- uv_path: 站点某个资源的总访问uv
* - visit_info_ip:
* ---- pv: 用户访问的站点总次数
* ---- path_pv: 用户访问的路径总次数
* - visit_info_20230822每日记录, 一天一条记录
* ---- pv: 12 # field = 月日_pv, pv的计数
* ---- uv: 5 # field = 月日_uv, uv的计数
* ---- pv_path: 2 # 资源的当前访问计数
* ---- uv_path: # 资源的当天访问uv
* ---- pv_ip: # 用户当天的访问次数
* ---- pv_path_ip: # 用户对资源的当天访问次数
*
* @param visitIp 访问者ip
* @param path 访问的资源路径
*/
@Override
public void saveVisitInfo(String visitIp, String path) {
String globalKey = SitemapConstants.SITE_VISIT_KEY;
String day = SitemapConstants.day(LocalDate.now());
String todayKey = globalKey + "_" + day;
// 用户的全局访问计数+1
Long globalUserVisitCnt = RedisClient.hIncr(globalKey + "_" + visitIp, "pv", 1);
// 用户的当日访问计数+1
Long todayUserVisitCnt = RedisClient.hIncr(todayKey, "pv_" + visitIp, 1);
RedisClient.PipelineAction pipelineAction = RedisClient.pipelineAction();
if (globalUserVisitCnt == 1) {
// 站点新用户
// 今日的uv + 1
pipelineAction.add(todayKey, "uv"
, (connection, key, field) -> {
connection.hIncrBy(key, field, 1);
});
pipelineAction.add(todayKey, "uv_" + path
, (connection, key, field) -> connection.hIncrBy(key, field, 1));
// 全局站点的uv
pipelineAction.add(globalKey, "uv", (connection, key, field) -> connection.hIncrBy(key, field, 1));
pipelineAction.add(globalKey, "uv_" + path, (connection, key, field) -> connection.hIncrBy(key, field, 1));
} else if (todayUserVisitCnt == 1) {
// 判断是今天的首次访问,更新今天的uv+1
pipelineAction.add(todayKey, "uv", (connection, key, field) -> connection.hIncrBy(key, field, 1));
if (RedisClient.hIncr(todayKey, "pv_" + path + "_" + visitIp, 1) == 1) {
// 判断是否为今天首次访问这个资源,若是,则uv+1
pipelineAction.add(todayKey, "uv_" + path, (connection, key, field) -> connection.hIncrBy(key, field, 1));
}
// 判断是否是用户的首次访问这个path,若是,则全局的path uv计数需要+1
if (RedisClient.hIncr(globalKey + "_" + visitIp, "pv_" + path, 1) == 1) {
pipelineAction.add(globalKey, "uv_" + path, (connection, key, field) -> connection.hIncrBy(key, field, 1));
}
}
// 更新pv 以及 用户的path访问信息
// 今天的相关信息 pv
pipelineAction.add(todayKey, "pv", (connection, key, field) -> connection.hIncrBy(key, field, 1));
pipelineAction.add(todayKey, "pv_" + path, (connection, key, field) -> connection.hIncrBy(key, field, 1));
if (todayUserVisitCnt > 1) {
// 非当天首次访问,则pv+1; 因为首次访问时,在前面更新uv时,已经计数+1了
pipelineAction.add(todayKey, "pv_" + path + "_" + visitIp, (connection, key, field) -> connection.hIncrBy(key, field, 1));
}
// 全局的 PV
pipelineAction.add(globalKey, "pv", (connection, key, field) -> connection.hIncrBy(key, field, 1));
pipelineAction.add(globalKey, "pv" + "_" + path, (connection, key, field) -> connection.hIncrBy(key, field, 1));
// 保存访问信息
pipelineAction.execute();
if (log.isDebugEnabled()) {
log.info("用户访问信息更新完成! 当前用户总访问: {},今日访问: {}", globalUserVisitCnt, todayUserVisitCnt);
}
}
2.2 Redis 管道封装
Redis 管道技术允许在服务端未响应时,客户端继续向服务端发送请求,并最终一次性读取所有服务端的响应,从而实现批量操作。通过对 Redis pipeline 使用姿势的封装,简化了调用过程,例如 com.github.paicoding.forum.core.cache.RedisClient.PipelineAction 中的相关代码:
/**
* redis 管道执行的封装链路
*/
public static class PipelineAction {
private List<Runnable> run = new ArrayList<>();
private RedisConnection connection;
public PipelineAction add(String key, BiConsumer<RedisConnection, byte[]> conn) {
run.add(() -> conn.accept(connection, RedisClient.keyBytes(key)));
return this;
}
public PipelineAction add(String key, String field, ThreeConsumer<RedisConnection, byte[], byte[]> conn) {
run.add(() -> conn.accept(connection, RedisClient.keyBytes(key), valBytes(field)));
return this;
}
public void execute() {
template.executePipelined((RedisCallback<Object>) connection -> {
PipelineAction.this.connection = connection;
run.forEach(Runnable::run);
return null;
});
}
}
@FunctionalInterface
public interface ThreeConsumer<T, U, P> {
void accept(T t, U u, P p);
}
2.3 计数更新与使用
PV/UV 的更新可以在 Filter 中统一调用,为避免计数影响实际业务操作,采用异步更新策略:com.github.paicoding.forum.web.hook.filter.ReqRecordFilter#initReqInfo。
private HttpServletRequest initReqInfo(HttpServletRequest request, HttpServletResponse response) {
if (isStaticURI(request)) {
// 静态资源直接放行
return request;
}
StopWatch stopWatch = new StopWatch("请求参数构建");
try {
stopWatch.start("traceId");
// 添加全链路的traceId
MdcUtil.addTraceId();
stopWatch.stop();
stopWatch.start("请求基本信息");
// 手动写入一个session,借助 OnlineUserCountListener 实现在线人数实时统计
request.getSession().setAttribute("latestVisit", System.currentTimeMillis());
ReqInfoContext.ReqInfo reqInfo = new ReqInfoContext.ReqInfo();
reqInfo.setHost(request.getHeader("host"));
reqInfo.setPath(request.getPathInfo());
if (reqInfo.getPath() == null) {
String url = request.getRequestURI();
int index = url.indexOf("?");
if (index > 0) {
url = url.substring(0, index);
}
reqInfo.setPath(url);
}
reqInfo.setReferer(request.getHeader("referer"));
reqInfo.setClientIp(IpUtil.getClientIp(request));
reqInfo.setUserAgent(request.getHeader("User-Agent"));
reqInfo.setDeviceId(getOrInitDeviceId(request, response));
request = this.wrapperRequest(request, reqInfo);
stopWatch.stop();
stopWatch.start("登录用户信息");
// 初始化登录信息
globalInitService.initLoginUser(reqInfo);
stopWatch.stop();
ReqInfoContext.addReqInfo(reqInfo);
stopWatch.start("pv/uv站点统计");
// 更新uv/pv计数
AsyncUtil.execute(() -> SpringUtil.getBean(SitemapServiceImpl.class).saveVisitInfo(reqInfo.getClientIp(), reqInfo.getPath()));
stopWatch.stop();
stopWatch.start("回写traceId");
// 返回头中记录traceId
response.setHeader(GLOBAL_TRACE_ID_HEADER, Optional.ofNullable(MdcUtil.getTraceId()).orElse(""));
stopWatch.stop();
} catch (Exception e) {
log.error("init reqInfo error!", e);
} finally {
if (!EnvUtil.isPro()) {
log.info("{} -> 请求构建耗时: \n{}", request.getRequestURI(), stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
}
return request;
}
目前站点的统计信息在前台只显示全局站点的统计情况,使用时直接从 hash 中获取对应的计数即可:com.github.paicoding.forum.service.sitemap.service.impl.SitemapServiceImpl#querySiteVisitInfo。
/**
* 查询站点某一天or总的访问信息
*
* @param date 日期,为空时,表示查询所有的站点信息
* @param path 访问路径,为空时表示查站点信息
* @return
*/
@Override
public SiteCntVo querySiteVisitInfo(LocalDate date, String path) {
String globalKey = SitemapConstants.SITE_VISIT_KEY;
String day = null, todayKey = globalKey;
if (date != null) {
day = SitemapConstants.day(date);
todayKey = globalKey + "_" + day;
}
String pvField = "pv", uvField = "uv";
if (path != null) {
// 表示查询对应路径的访问信息
pvField += "_" + path;
uvField += "_" + path;
}
Map<String, Integer> map = RedisClient.hMGet(todayKey, Arrays.asList(pvField, uvField), Integer.class);
SiteCntVo siteInfo = new SiteCntVo();
siteInfo.setDay(day);
siteInfo.setPv(map.getOrDefault(pvField, 0));
siteInfo.setUv(map.getOrDefault(uvField, 0));
return siteInfo;
}
前台使用路径:

3 小结
基于 Redis 实现 PV/UV 统计主要依靠两个关键知识点:
- hash: incr:利用 Redis 的 hash 结构结合 incr 命令实现原子计数。
- pipeline:通过管道方式实现批量操作,提高操作效率。
最后提出一个思考问题:当站点访问量剧增,一天达到几百万的访问量时,通过记录 IP 来实现 UV 计数会导致用户访问记录存储开销巨大,此时可以考虑使用 Redis 中的 HyperLoglog 来解决这一问题,它利用数学上的概率统计分布原理,能在空间复杂度较低的情况下实现近似的计数统计。
希望本文对大家理解和实现网站的 PV/UV 数据统计有所帮助,欢迎大家一起交流探讨相关技术问题。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









