







文章目录
1 实验说明
CNN模型是自己搭的,可以用效果更好的VGG、ResNet等替换。
KDD99数据集下载地址:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
2 实验过程
2.1 数据预处理
2.1.1 导入数据
因为KDDTrian+.txt没有表头,所以给他手动添加上标签
df = pd.read_csv('../../data/NSL-KDD/KDDTrain+.txt')
columns = (['duration'
,'protocol_type'
,'service'
,'flag'
,'src_bytes'
,'dst_bytes'
,'land'
,'wrong_fragment'
,'urgent'
,'hot'
,'num_failed_logins'
,'logged_in'
,'num_compromised'
,'root_shell'
,'su_attempted'
,'num_root'
,'num_file_creations'
,'num_shells'
,'num_access_files'
,'num_outbound_cmds'
,'is_host_login'
,'is_guest_login'
,'count'
,'srv_count'
,'serror_rate'
,'srv_serror_rate'
,'rerror_rate'
,'srv_rerror_rate'
,'same_srv_rate'
,'diff_srv_rate'
,'srv_diff_host_rate'
,'dst_host_count'
,'dst_host_srv_count'
,'dst_host_same_srv_rate'
,'dst_host_diff_srv_rate'
,'dst_host_same_src_port_rate'
,'dst_host_srv_diff_host_rate'
,'dst_host_serror_rate'
,'dst_host_srv_serror_rate'
,'dst_host_rerror_rate'
,'dst_host_srv_rerror_rate'
,'label'
,'level'])
df.columns = columns
2.1.2 one-hot编码
对分类变量(categorical variables)进行one-hot编码处理。one-hot编码可以让分类变量转换为便于计算交叉熵的one-hot向量。给定分类变量
x
1
x_1
x1
x
2
x_2
x2
…
\ldots
…
x
n
x_n
xn,编码后的向量变为:
x
1
=
[
1
,
0
,
…
,
0
]
T
,
x_1=[1,0,\ldots,0]^\mathrm T,
x1=[1,0,…,0]T,
x
2
=
[
0
,
1
,
…
,
0
]
T
,
x_2=[0,1,\ldots,0]^\mathrm T,
x2=[0,1,…,0]T,
…
\ldots
…
x
n
=
[
0
,
0
,
…
,
1
]
T
,
x_n=[0,0,\ldots,1]^\mathrm T,
xn=[0,0,…,1]T,
one-hot向量可以方便的与cnn的输出(logits)计算交叉熵
# 数值列
number_col = df.select_dtypes(include=['number']).columns
# 分类变量
cat_col = df.columns.difference(number_col)
cat_col = cat_col.drop('label')
# 将分类变量筛选出来
df_cat = df[cat_col].copy()
# one-hot编码
one_hot_data = pd.get_dummies(df_cat, columns=cat_col)
# 将原数据的分类变量去掉
one_hot_df = pd.concat([df, one_hot_data],axis=1)
one_hot_df.drop(columns=cat_col, inplace=True)
2.1.3 归一化
将数值列的元素缩放到 [ 0 , 1 ] [0,1] [0,1]区间
minmax_scale = MinMaxScaler(feature_range=(0, 1))
def normalization(df,col):
for i in col:
arr = df[i]
arr = np.array(arr)
df[i] = minmax_scale.fit_transform(arr.reshape(len(arr),1))
return df
normalized_df = normalization(one_hot_df.copy(), number_col)
2.1.4 标签编码
类标签编码,如normal编码为0,backdoor编码为1等
# 为不同的类别进行编码
labels = pd.DataFrame(df.label)
label_encoder = LabelEncoder()
enc_label = labels.apply(label_encoder.fit_transform)
normalized_df.label = enc_label
label_encoder.classes_
data = normalized_df
2.2 数据加载
训练集与测试集按照2:8的比例划分
X = data.drop(columns=['label'])
y = data['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=50)
定义pytorch的load函数,加载数据,返回样本 X X X与标签 y y y
class LoadData(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, index):
X = torch.tensor(self.X.iloc[index])
y = torch.tensor(self.y.iloc[index])
return X, y
train_data = LoadData(X_train, y_train)
test_data = LoadData(X_test, y_test)
X_dimension = len(X_train.columns)
y_dimension = len(y_train.value_counts())
print(f"X的维度:{X_dimension}")
print(f"y的维度:{y_dimension}")
batch_size = 128
train_dataloader = DataLoader(train_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
2.3 搭建模型
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
CNN模块可以替换为ResNet等更深的网络模型
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.backbone = nn.Sequential(
nn.Conv1d(1, 3, kernel_size=2),
nn.MaxPool1d(2, 2),
nn.Conv1d(3, 8, kernel_size=2),
nn.MaxPool1d(2, 2),
nn.Conv1d(8, 16, kernel_size=2)
)
self.flatten = nn.Flatten()
self.fc = nn.Sequential(
nn.Linear(464, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, y_dimension)
)
def forward(self, X):
X = self.backbone(X)
X = self.flatten(X)
logits = self.fc(X)
return logits
CNN_model = CNN()
CNN_model.to(device=device)
2.4 模型训练
# 定义超参数
epochs = 20
lr = 1e-3
momentum = 0.9
optimizer = torch.optim.SGD(CNN_model.parameters(), lr=lr, momentum=momentum)
loss_fn = nn.CrossEntropyLoss()
def train(model, optimizer, loss_fn, epochs):
losses = []
iter = 0
for epoch in range(epochs):
print(f"epoch {epoch+1}\n-----------------")
for i, (X, y) in enumerate(train_dataloader):
X, y = X.to(device).to(torch.float32), y.to(device).to(torch.float32)
X = X.reshape(X.shape[0], 1, X_dimension)
y_pred = model(X)
loss = loss_fn(y_pred, y.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(f"loss: {loss.item()}\t[{(i+1)*len(X)}/{len(train_data)}]")
iter += 1
losses.append(loss.item())
return losses, iter
def test(model):
positive = 0
negative = 0
with torch.no_grad():
iter = 0
loss_sum = 0
for X, y in test_dataloader:
X, y = X.to(device).to(torch.float32), y.to(device).to(torch.float32)
X = X.reshape(X.shape[0], 1, X_dimension)
y_pred = model(X)
loss = loss_fn(y_pred, y.long())
loss_sum += loss.item()
iter += 1
for item in zip(y_pred, y):
if torch.argmax(item[0]) == item[1]:
positive += 1
else:
negative += 1
acc = positive / (positive + negative)
avg_loss = loss_sum / iter
print("Accuracy:", acc)
print("Average Loss:", avg_loss)
def loss_value_plot(losses, iter):
plt.figure()
plt.plot([i for i in range(1, iter+1)], losses)
plt.xlabel('Iterations (×100)')
plt.ylabel('Loss Value')
if os.path.exists('CNN_model.pth'):
CNN_model.load_state_dict(torch.load('CNN_model.pth'))
else:
losses, iter = train(CNN_model, optimizer, loss_fn, epochs)
torch.save(CNN_model.state_dict(), 'CNN_model.pth')
loss_value_plot(losses, iter)
plt.savefig('CNN_loss.png')
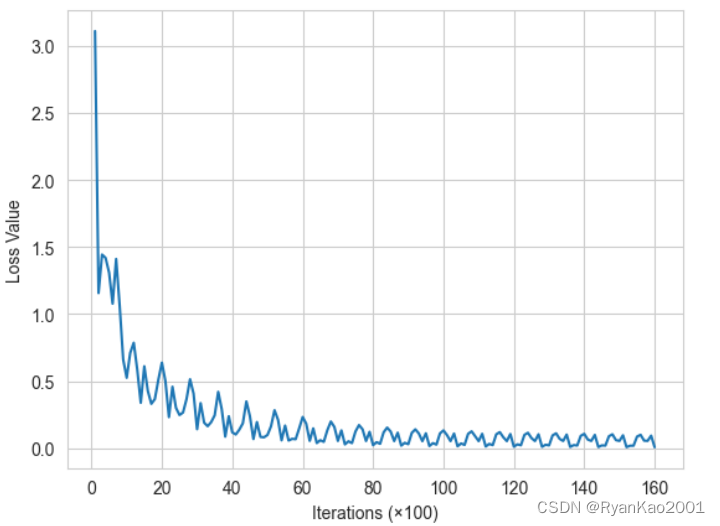
3 实验结果
执行test函数,得到结果
test(CNN_model)

4 完整代码
https://github.com/gwcrepo/kdd99-classification
github上的代码额外实现了全连接网络的分类

















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









