







Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
4.1 Introduction
4.2 stat, fstat, fstatat, and lstat Functions
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int stat(const char *restrict pathname, struct stat *restrict buf );
int fstat(int fd, struct stat *buf );
int lstat(const char *restrict pathname, struct stat *restrict buf );
#include <fcntl.h> /* Definition of AT_* constants */
#include <sys/stat.h>
int fstatat(int fd, const char *restrict pathname, struct stat *restrict buf, int flag);
All four return: 0 if OK, −1 on error- stat: Give a pathname, returns a structure of information about the named file.
- fstat: obtains information about the file that is open on the descriptor fd.
- lstat: similar to stat, but when the named file is a symbolic link, lstat returns information about the symbolic link, not the file referenced by the symbolic link.
- fstatat: provides a way to return the file statistics for a pathname relative to an open directory represented by the fd argument.
- If pathname is an absolute pathname, the fd argument is ignored.
- If fd = AT_FDCWD & pathname is a relative pathname, then fstatat evaluates the pathname argument relative to the current directory.
- The flag argument controls whether symbolic links are followed:
- The default is to follow symbolic links, returning information about the file to which the symbolic link points.
- When the AT_SYMLINK_NOFOLLOW flag is set, fstatat will not follow symbolic links, returns information about the link itself.
- The buf argument is a pointer to a structure that we must supply. The functions fill in the structure. The definition of the structure can differ among implementations, but it could look like
struct stat
{
mode_t st_mode; /* file type & mode (permissions) */
ino_t st_ino; /* i-node number (serial number) */
dev_t st_dev; /* device number (file system) */
dev_t st_rdev; /* device number for special files */
nlink_t st_nlink; /* number of links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
off_t st_size; /* size in bytes, for regular files */
struct timespec st_atim; /* time of last access */
struct timespec st_mtim; /* time of last modification */
struct timespec st_ctim; /* time of last file status change */
blksize_t st_blksize; /* best I/O block size */
blkcnt_t st_blocks; /* number of disk blocks allocated */
};- The timespec structure type defines time in terms of seconds and nanoseconds. It includes at least the following fields:
time_t tv_sec;
long tv_nsec;4.3 File Types
- Regular file. The most common type of file, which contains data of some form. There is no distinction to the kernel whether this data is text or binary. Any interpretation of the contents of a regular file is left to the application processing the file. Exception is binary executable files. All binary executable files conform to a format that allows the kernel to identify where to load a program’s text and data.
- Directory file. A file that contains the names of other files and pointers to information on these files. Any process that has read permission for a directory file can read the contents of the directory, but only the kernel can write directly to a directory file. Processes must use system calls to make changes to a directory.
- Block special file. A type of file providing buffered I/O access in fixed-size units to devices such as disk drives. All access to devices is through the character special interface.
- Character special file. A type of file providing unbuffered I/O access in variable-sized units to devices. All devices on a system are either block special files or character special files.
- FIFO. A type of file used for communication between processes, also called pipe.
- Socket. A type of file used for network communication between processes. A socket can also be used for non-network communication between processes on a single host.
- Symbolic link. A type of file that points to another file.
- The type of a file is encoded in the st_mode(mode_t st_mode;) member of the stat structure. We can determine the file type with the macros in Figure 4.1. The argument to each of these macros is the st_mode member from the stat structure.

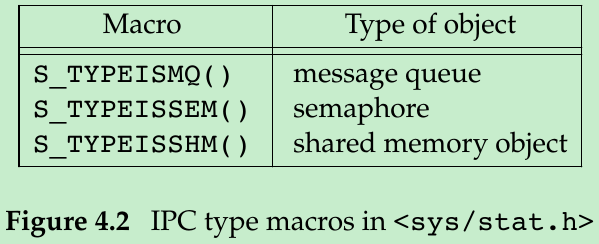
- POSIX.1 allows implementations(not including Linux) to represent interprocess communication(IPC) objects, such as message queues and semaphores, as files. The macros shown in Figure 4.2 allow us to determine the type of IPC object from the stat structure. Their argument is a pointer to the stat structure.

- The program in Figure 4.3 prints the type of file for each command-line argument.
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char *argv[])
{
struct stat buf;
char *ptr;
for(int index = 1; index < argc; ++index)
{
printf("%s: ", argv[index]);
if(lstat(argv[index], &buf) < 0)
{
Exit("lstat error");
continue;
}
if(S_ISREG(buf.st_mode))
{
ptr = "regular";
}
else if(S_ISDIR(buf.st_mode))
{
ptr = "directory";
}
else if(S_ISCHR(buf.st_mode))
{
ptr = "character special";
}
else if(S_ISBLK(buf.st_mode))
{
ptr = "block special";
}
else if(S_ISFIFO(buf.st_mode))
{
ptr = "fifo";
}
else if(S_ISLNK(buf.st_mode))
{
ptr = "symbolic link";
}
/*
FIXME: undefined reference to `S_ISSOCK'
else if(S_ISSOCK(buf.st_mode))
{
ptr = "socket";
}
*/
else
{
ptr = "** unknown mode **";
}
printf("%s\n", ptr);
}
exit(0);
}4.4 Set-User-ID and Set-Group-ID
- Every process has six or more IDs associated with it that are shown in Figure 4.5.

- The real user ID and real group ID identify who we really are. These two fields are taken from our entry in the password file when we log in. Normally, these values don’t change during a login session, although there are ways for a superuser process to change them(Section 8.11).
- The effective user ID, effective group ID, and supplementary group IDs(Section 1.8) determine our file access permissions.
Normally, effective user ID = real user ID, effective group ID = real group ID. - The saved set-user-ID = effective user ID; saved set-group-ID = effective group ID, when a program is executed.
- Every file has an owner and a group owner that are specified by the st_uid/st_gid member of the stat structure. When we execute a program file, the effective user ID of the process is usually the real user ID, and the effective group ID is usually the real group ID. But we can set the “set-user-ID bit” that causes the effective user ID = the owner of the file(st_uid), set the “set-group-ID bit” that causes the effective group ID = the group owner of the file(st_gid).
- If the owner of the file is the superuser and if the file’s set-user-ID bit is set, then while that program is running as a process, it has superuser privileges regardless of the real user ID of the process that executes the file. E.g.: UNIX allows anyone to change his or her password, passwd(1) is a set-user-ID program. This is required so that the program can write the new password to the password file that should be writable only by the superuser.
- The set-user-ID bit and the set-group-ID bit are contained in the file’s st_mode value. These two bits can be tested against the constants S_ISUID and S_ISGID respectively.
4.5 File Access Permissions
- All the file types have permissions. The st_mode value encodes the access permission bits for the file.
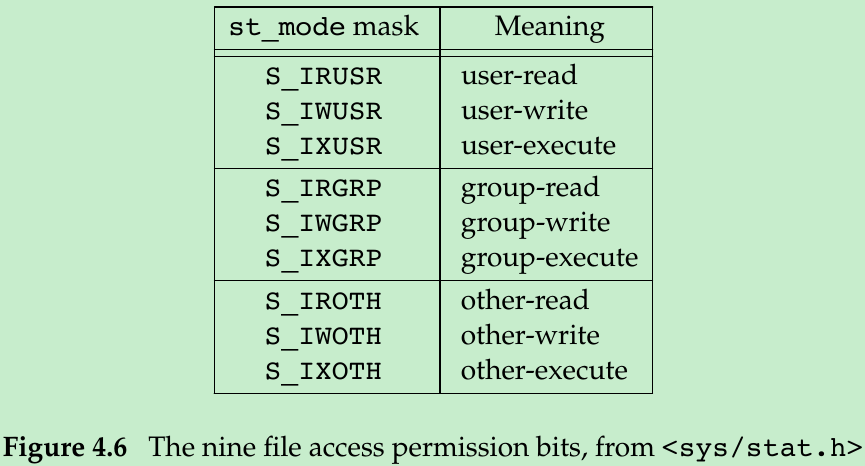
- User refers to the owner of the file.
- Whenever we want to open any type of file by name, we must have execute permission in each directory mentioned in the name. This is why the execute permission bit for a directory is often called the search bit.
- Differences between “read” and “execute” permission for a directory:
- Read permission lets us read the directory, obtaining a list of all the filenames in the directory.
- Execute permission lets us pass through the directory when it is a component of a pathname that we are trying to access.
- The read permission for a file determines whether we can open an existing file for reading: the O_RDONLY and O_RDWR flags for the open function.
- The write permission for a file determines whether we can open an existing file for writing: the O_WRONLY and O_RDWR flags for the open function. We must have write permission for a file to specify the O_TRUNC flag in the open function.
- We must have write permission and execute permission to create a new file in a directory.
- To delete an existing file, we need write permission and execute permission in the directory containing the file. We do not need read permission or write permission for the file itself.
- Execute permission for a file must be on if we want to execute the file using any of the seven exec functions(Section 8.10). The file has to be a regular file.
- The file access tests that the kernel performs each time a process opens, creates, or deletes a file depend on the owners of the file(st_uid and st_gid), the effective IDs of the process(effective user ID and effective group ID), and the supplementary group IDs of the process, if supported. The two owner IDs are properties of the file, whereas the two effective IDs and the supplementary group IDs are properties of the process.
- The tests performed by the kernel are as follows:
- Effective user ID of the process = 0(the superuser), access is allowed. This gives the superuser free rein throughout the entire file system.
- Effective user ID of the process = owner ID(st_uid) of the file(i.e., the process owns the file), access is allowed if the appropriate user access permission bit is set. Otherwise, permission is denied.
- Effective group ID of the process/One of the supplementary group IDs of the process = group ID(st_gid) of the file, access is allowed if the appropriate group access permission bit is set. Otherwise, permission is denied.
- If the appropriate other access permission bit is set, access is allowed. Otherwise, permission is denied.
- These four steps are tried in sequence. If the process owns the file(step 2), access is granted or denied based only on the user access permissions; the group permissions are never looked at. If the process does not own the file but belongs to an appropriate group, access is granted or denied based only on the group access permissions; the other permissions are not looked at.
4.6 Ownership of New Files and Directories
- The user ID of a new file is set to the effective user ID of the process.
- POSIX.1: The group ID of a new file can be
- effective group ID of the process.
- group ID of the directory in which the file is being created.
- Linux allow the choice between the two options to be selected using mount(1) command. Default is to determine the group ID of a new file depending on whether the set-group-ID bit is set for the directory in which the file is created.
- If set: the new file’s group ID is copied from the directory;
- If not set: the new file’s group ID is set to the effective group ID of the process.
4.7 access and faccessat Functions
- The access and faccessat functions base access tests on the real user and group IDs. (Replace effective with real in the four steps of Section 4.5.)
#include <unistd.h>
int access(const char *pathname, int mode);
#include <fcntl.h>
#include <unistd.h>
int faccessat(int fd, const char *pathname, int mode, int flag);
Both return: 0 if OK, −1 on error- The mode is either the value F_OK to test if a file exists, or the bitwise OR of any of the flags shown in Figure 4.7.

- faccessat:
- Behave like access when:
1) pathname is absolute; or
2) fd = AT_FDCWD & pathname is relative. - Otherwise, evaluates the pathname relative to the open directory referenced by the fd.
- When flag = AT_EACCESS, the access checks are made using the effective user and group IDs of the calling process instead of the real user and group IDs.
- Behave like access when:

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> // access()
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> // open()
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char *argv[])
{
if(argc != 2)
{
Exit("usage: ./a.out <pathname>");
}
if(access(argv[1], R_OK) < 0)
{
Exit("access error");
}
else
{
printf("read access OK\n");
}
if(open(argv[1], O_RDONLY) < 0)
{
Exit("open error");
}
else
{
printf("open for reading OK\n");
}
exit(0);
}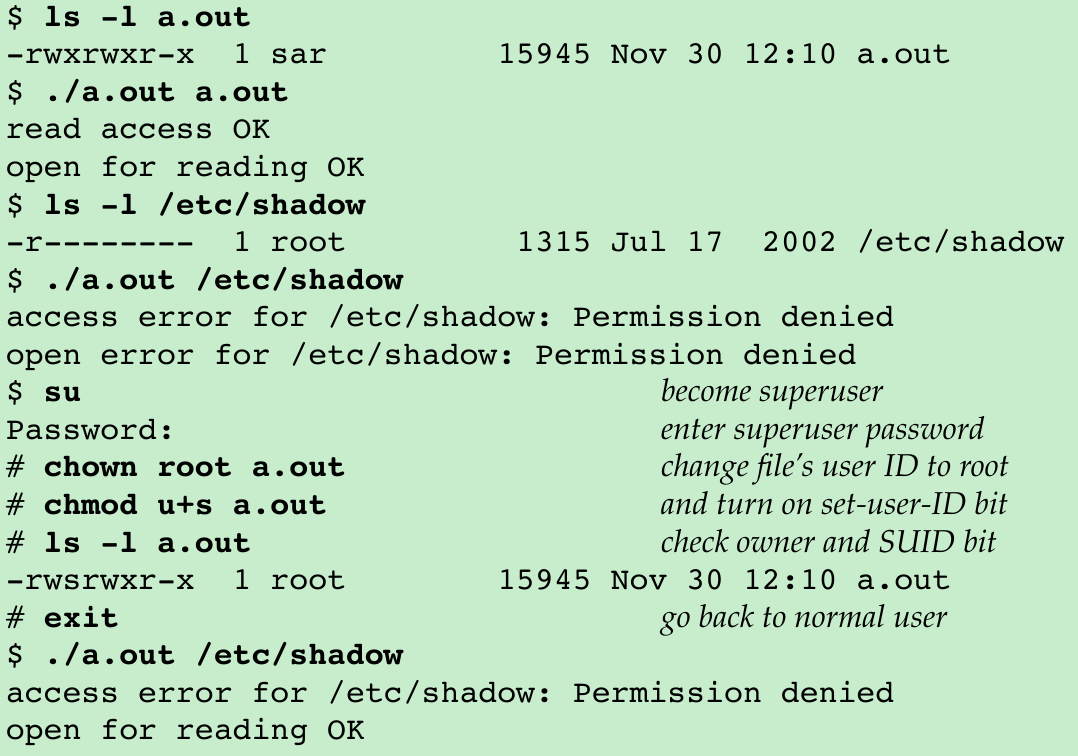
- The set-user-ID program can determine that the real user cannot normally read the file, even though the open function will succeed.
4.8 umask Function
- The umask function sets the file mode creation mask for the process and returns the previous value.
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t cmask);
Returns: previous file mode creation mask- The cmask argument is formed as the bitwise OR of any of the nine constants from Figure 4.6.
- The file mode creation mask is used whenever the process creates a new file or a new directory. Sections 3.3 and 3.4: Both open and creat accept a mode argument that specifies the new file’s access permission bits. Any bits that are on in the file mode creation mask are turned off in the file’s mode.

#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> // creat()
#define RW (S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH)
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char *argv[])
{
umask(0);
if(creat("foo", RW) < 0)
{
Exit("creat error for foo");
}
umask(S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH);
if(creat("bar", RW) < 0)
{
Exit("creat error for bar");
}
exit(0);
}- The program in Figure 4.9 creates two files: one with a umask of 0 and one with a umask that disables all the group and other permission bits.

- Users’ umask value is usually set once, on login, by the shell’s start-up file, and never changed. When creating new files, if we want to ensure that specific access permission bits are enabled, we must modify the umask value while the process is running. If we want to ensure that anyone can read a file, we should set the umask to 0. Otherwise, the umask value that is in effect when our process is running can cause permission bits to be turned off.
- We use the shell’s umask command to print the file mode creation mask both before running the program and after it completes. This shows that changing the file mode creation mask of a process doesn’t affect the mask of its parent(often a shell).
- Users can set the umask value to control the default permissions on the files they create. This value is expressed in octal(begin with 0), with one bit representing one permission to be masked off, as shown in Figure 4.10.
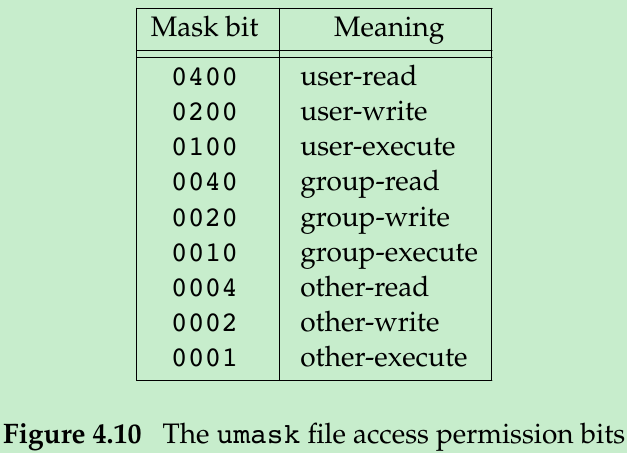
- Permissions can be denied by setting the corresponding bits.
002: prevent others from writing your files,
027: prevent group members from writing your files and others from reading, writing, or executing your files. - The Single UNIX Specification requires that the umask command support a symbolic mode of operation which specifies permissions that are to be allowed(i.e., clear in the file creation mask).

4.9 chmod, fchmod, and fchmodat Functions
- The chmod, fchmod, and fchmodat functions allow us to change the file access permissions for an existing file.
#include <sys/stat.h>
int chmod(const char *pathname, mode_t mode);
int fchmod(int fd, mode_t mode);
#include <fcntl.h>
#include <sys/stat.h>
int fchmodat(int fd, const char *pathname, mode_t mode, int flag);
All three return: 0 if OK, −1 on error- chmod operates on the specified file.
- fchmod operates on a file that has already been opened.
- fchmodat:
- Behaves like chmod when:
1) pathname is absolute or
2) fd = AT_FDCWD & pathname is relative. - Otherwise, evaluates the pathname relative to the open directory referenced by fd.
- When flag = AT_SYMLINK_NOFOLLOW, it doesn’t follow symbolic links.
- Behaves like chmod when:
- To change the permission bits of a file, the effective user ID of the process must be equal to the owner ID of the file, or the process must have superuser permissions.
- The mode is specified as the bitwise OR of the constants shown in Figure 4.11.
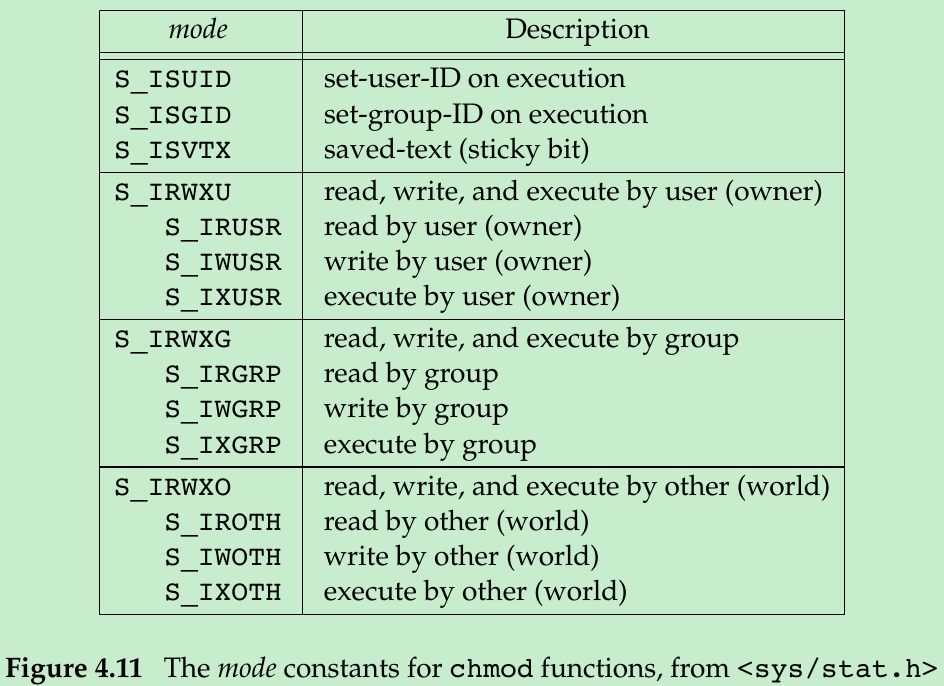
- The final state of the files foo and bar when we ran the program in Figure 4.9.
$ ls -l foo bar
-rw------- 1 sar 0 Dec 7 21:20 bar
-rw-rw-rw- 1 sar 0 Dec 7 21:20 foo
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h> // chmod()
#include <unistd.h> // stat()
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char *argv[])
{
struct stat statbuf;
// Turn on set-group-ID and turn off group-execute
if(stat("foo", &statbuf) < 0)
{
Exit("stat error for foo");
}
if(chmod("foo", (statbuf.st_mode & ~S_IXGRP) | S_ISGID) < 0)
{
Exit("chmod error for foo");
}
// Set absolute mode to "rw-r--r--"
if(chmod("bar", S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH) < 0)
{
Exit("chmod error for bar");
}
exit(0);
}- The program in Figure 4.12 modifies the mode of these two files. After running the program in Figure 4.12, we see that the final state of the two files is
$ ls -l foo bar
-rw-r--r-- 1 sar 0 Dec 7 21:20 bar
-rw-rwSrw- 1 sar 0 Dec 7 21:20 foo- We set the permissions of the file bar to an absolute value, regardless of the current permission bits.
- For the file foo, we set the permissions relative to their current state. We first call stat to obtain the current permissions and then modify them. We explicitly turned on the set-group-ID bit and turned off the group-execute bit. ls command lists the group-execute permission as S to signify that the set-group-ID bit is set without the group-execute bit being set.
- Note the time and date listed by the ls command did not change after we ran the program in Figure 4.12. Section 4.19: chmod updates only the time that the i-node was last changed. By default, the ls -l lists the time when the contents of the file were last modified.
- The chmod functions automatically clear two of the permission bits under the following conditions:
- On systems that place special meaning on the sticky bit when used with regular files, if we try to set the sticky bit(S_ISVTX) on a regular file and do not have superuser privileges, the sticky bit in the mode is automatically turned off. Only the superuser can set the sticky bit of a regular file. Linux 3.2.0 place no such restriction because the bit has no meaning when applied to regular files on Linux.
- The user ID of a new file is set to the effective user ID of the process.
- POSIX.1: The group ID of a new file can be
- effective group ID of the process.
- group ID of the directory in which the file is being created.
- Linux allow the choice between the two options to be selected using mount(1) command. Default is to determine the group ID of a new file depending on whether the set-group-ID bit is set for the directory in which the file is created.
- If set: the new file’s group ID is copied from the directory;
- If not set: the new file’s group ID is set to the effective group ID of the process.
- The group ID of a newly created file might be a group that the calling process does not belong to. Section 4.6: It’s possible for the group ID of the new file to be the group ID of the parent directory. If the group ID of the new file does not equal either the effective group ID of the process or one of the process’s supplementary group IDs and if the process does not have superuser privileges, then the set-group-ID bit is automatically turned off. This prevents a user from creating a set-group-ID file owned by a group that the user doesn’t belong to. Linux silently turn the bit off, but don’t fail the attempt to change the file access permissions.
- Linux 3.2.0 add a security feature to try to prevent misuse of some of the protection bits. If a process that does not have superuser privileges writes to a file, the set-user-ID and set-group-ID bits are automatically turned off. If malicious users find a set-group-ID or a set-user-ID file they can write to, even though they can modify the file, they lose the special privileges of the file.
4.10 Sticky Bit
- On UNIX that predated demand paging, S_ISVTX bit was known as the sticky bit. If it was set for an executable program file, then the first time the program was executed, a copy of the program’s text was saved in the swap area when the process terminated. The program would then load into memory more quickly the next time it was executed because the swap area was handled as a contiguous file, as compared to the possibly random location of data blocks in a normal UNIX file system. The name sticky came about because the text portion of the file stuck around in the swap area until the system was rebooted. UNIX referred to this as the saved-text bit(supported by Linux 3.2.0); hence the constant S_ISVTX. With today’s virtual memory system and a faster file system, the need for this technique has disappeared.
- Now, the use of the sticky bit has been extended. The Single UNIX Specification allows the sticky bit to be set for a directory. If the bit is set for a directory, a file in the directory can be removed or renamed only if the user has write permission for the directory and meets one of the following criteria:
- Owns the file
- Owns the directory
- Is the superuser
4.11 chown, fchown, fchownat, and lchown Functions
- chown changes a file’s user ID and group ID, but if either of the arguments owner or group is −1, the corresponding ID is left unchanged.
#include <unistd.h>
int chown(const char *pathname, uid_t owner, gid_t group);
int fchown(int fd, uid_t owner, gid_t group);
int lchown(const char *pathname, uid_t owner, gid_t group);
#include <fcntl.h>
#include <unistd.h>
int fchownat(int fd, const char *pathname, uid_t owner, gid_t group, int flag);
All four return: 0 if OK, −1 on error- For symbolic link: lchown and fchownat(with flag = AT_SYMLINK_NOFOLLOW) change the owners of the symbolic link itself, not the file pointed to by the symbolic link.
- fchown changes the ownership of the open file referenced by the fd argument.
- fchownat:
- = chown: (pathname is absolute) & (the AT_SYMLINK_NOFOLLOW flag is clear).
- = lchown: (fd = AT_FDCWD) & (pathname is relative) & (flag = AT_SYMLINK_NOFOLLOW).
- When (fd = file descriptor of an open directory) & (pathname is relative), fchownat evaluates the pathname relative to the open directory.
- Linux has the restriction that only the superuser can change the ownership of a file. Some systems allow all users to change the ownership of any files they own. POSIX.1 allows either form of operation, depending on the value of _POSIX_CHOWN_RESTRICTED.
- We’ll use ‘‘if _POSIX_CHOWN_RESTRICTED is in effect’’ to mean ‘‘if it applies to the particular file that we’re talking about’’ regardless of whether this actual constant is defined in the header.
- If _POSIX_CHOWN_RESTRICTED is in effect for the specified file, then
- Only a superuser process can change the user ID of the file.
- A non-superuser process can change the group ID of the file if the process owns the file(the effective user ID equals the user ID of the file), owner is specified as −1 or equals the user ID of the file, and group equals either the effective group ID of the process or one of the process’s supplementary group IDs.
- This means that when _POSIX_CHOWN_RESTRICTED is in effect, you can’t change the user ID of your files. You can change the group ID of files that you own, but only to groups that you belong to.
- If these functions are called by a process other than a superuser process, on successful return, both the set-user-ID and the set-group-ID bits are cleared.
4.12 File Size
- The st_size member of the stat structure contains the size of the file in bytes. This field is meaningful only for regular files, directories, and symbolic links.
- For a regular file, a file size of 0 is allowed. We’ll get an end-of-file indication on the first read of the file.
- For a directory, the file size is usually a multiple of a number, such as 16 or 512.
- For a symbolic link, the file size is the number of bytes in the filename. E.g.: the file size of 7 is the length of the pathname usr/lib:
lrwxrwxrwx 1 root 7 Sep 25 07:14 lib -> usr/lib - Linux provide the fields st_blksize and st_blocks. The first is the preferred block size for I/O for the file, and the latter is the actual number of 512-byte blocks that are allocated. It is effective to read or write st_blksize bytes at a time.
Holes in a File
- Holes are created by seeking past the current end of file and writing some data.
4.13 File Truncation
- We can truncate a file by chopping off data at the end of the file. Emptying a file by opening with O_TRUNC flag is a special case of truncation.
#include <unistd.h>
#include <sys/types.h>
int truncate(const char *pathname, off_t length);
int ftruncate(int fd, off_t length);
Both return: 0 if OK, −1 on error- These two functions truncate an existing file to length bytes
- If previous size > length, the data beyond length is no longer accessible.
- If previous size < length, the file size will increase and the data between the old end of file and the new end of file will read as 0(i.e., a hole is created in the file).
4.14 File Systems
- A disk drive is divided into one or more partitions. Each partition can contain a file system. The i-nodes are fixed-length entries that contain most of the information about a file.
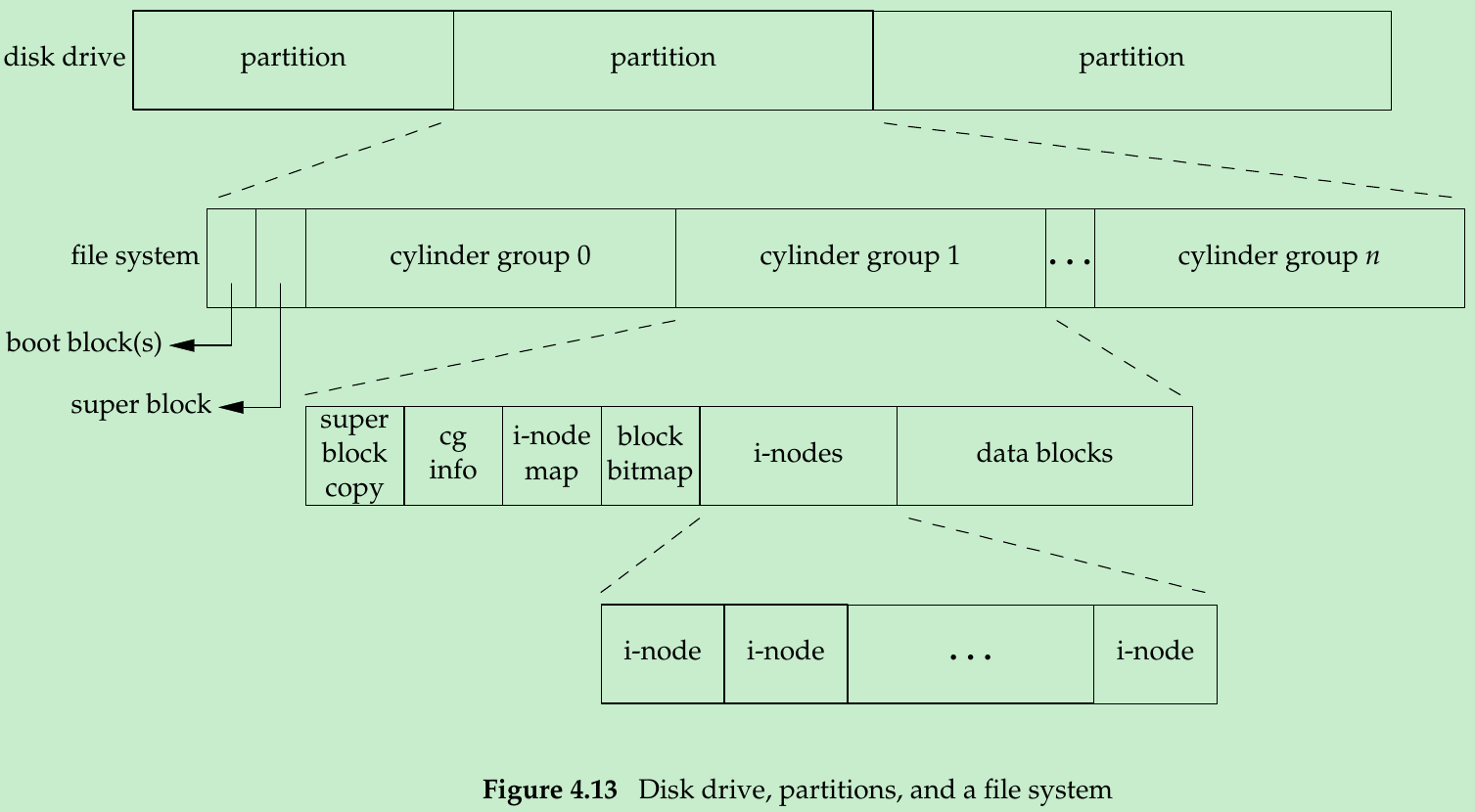
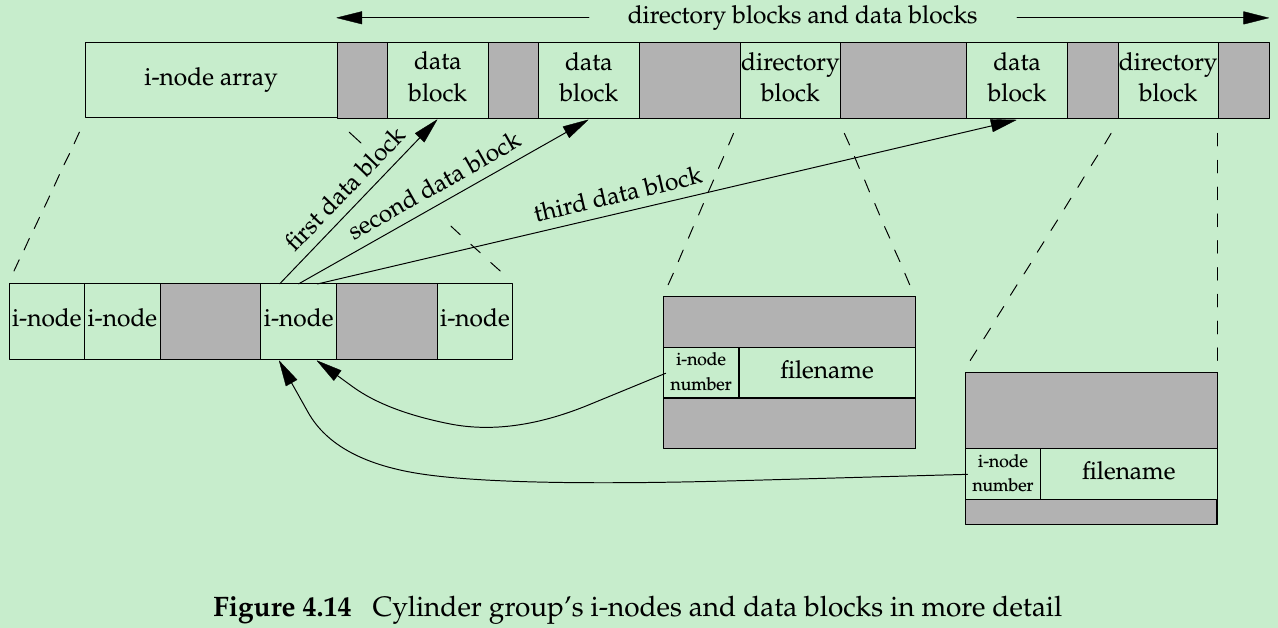
- Every i-node has a link count that contains the number of directory entries that point to it. Only when the link count goes to 0 can the file be deleted, releasing the data blocks associated with the file.
- This type of links are called hard links. The other type of link is called a symbolic link. Symbolic link’s file type in the i-node is S_IFLNK. With a symbolic link, the contents of the file(the data blocks) store the name of the file that the symbolic link points to. E.g.: the filename in the directory entry is the three-character string “lib” and the data blocks contain 7 bytes string “usr/lib”:
lrwxrwxrwx 1 root 7 Sep 25 07:14 lib -> usr/lib - The i-node contains all the information about the file: the file type/access permission bits/size/pointers to the data blocks, and so on. The filename and the i-node number are stored in the directory entry. The data type for the i-node number is ino_t.
- Because the i-node number in the directory entry points to an i-node in the same file system, a directory entry can’t refer to an i-node in a different file system.
- Rename a file: The contents of the file need not be moved, all needs is to add a new directory entry that points to the existing i-node and then unlink the old directory entry. The link count will remain the same. For example, to rename the file “/usr/lib/foo” to “/usr/foo”, the contents of the file foo need not be moved if the directories /usr/lib and /usr are on the same file system.
- Assume we make a new directory in the working directory, as
$ mkdir testdirFigure 4.15 shows the result: we explicitly show the entries for dot and dot-dot.
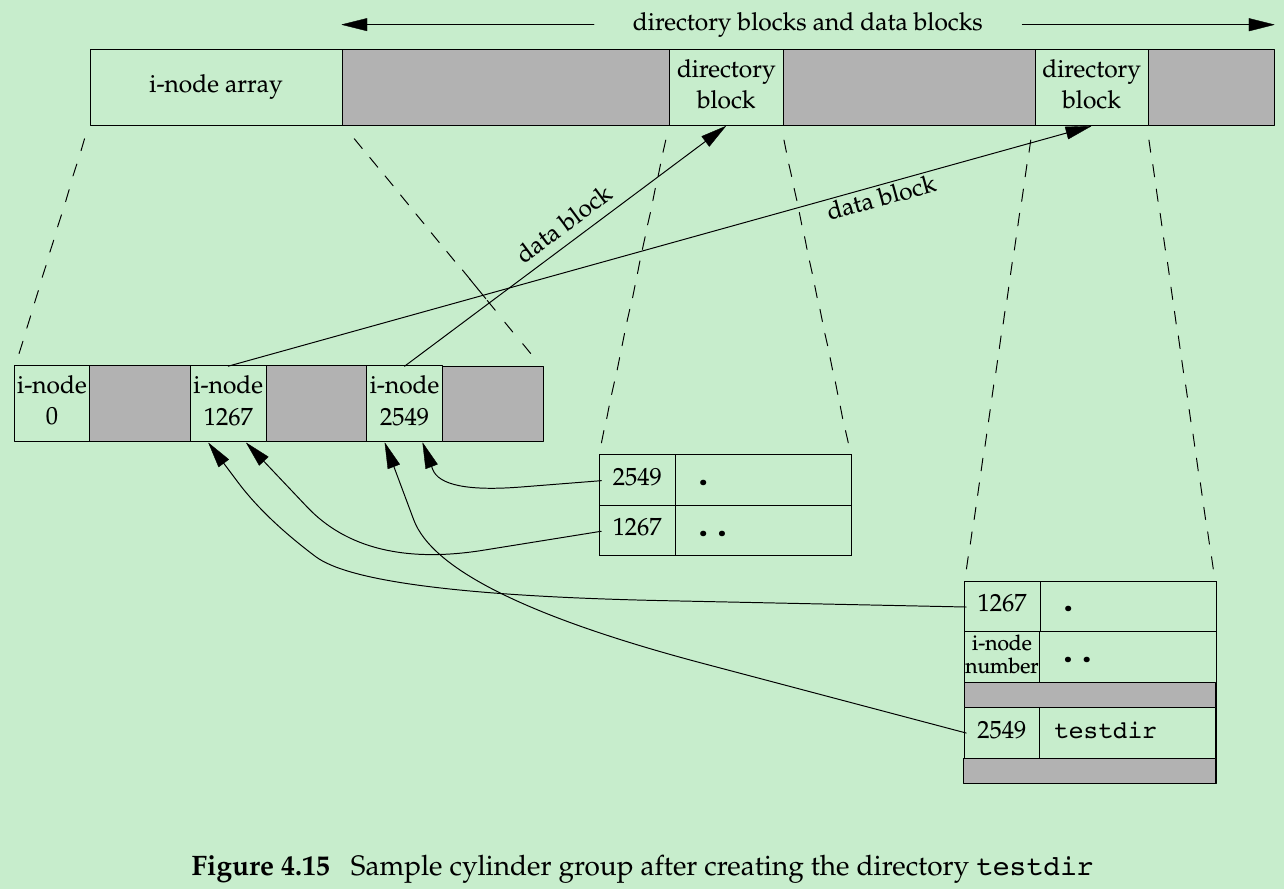
- The i-node whose number is 2549 has a type field of ‘‘directory’’ and a link count equal to 2. Any leaf directory(a directory that does not contain any other directories) always has a link count of 2 that comes from the directory entry that names the directory(testdir) and from the entry for dot in that directory.
- The i-node whose number is 1267 has a type field of ‘‘directory’’ and a link count that is greater than or equal to 3 because, at least, the i-node is pointed to from the directory entry that names it(not show in Figure 4.15), from dot, and from dot-dot in the testdir directory.
- Every subdirectory in a parent directory causes the parent directory’s link count to be increased by 1.
4.15 link, linkat, unlink, unlinkat, and remove Functions
- A file can have multiple directory entries pointing to its i-node. We can use the link/linkat function to create a link to an existing file.
#include <unistd.h>
int link(const char *existingpath, const char *newpath);
#include <fcntl.h>
#include <unistd.h>
int linkat(int efd, const char *existingpath, int nfd, const char *newpath, int flag);
Both return: 0 if OK, −1 on error- These functions create a new directory entry, newpath, that references the existing file existingpath. If the newpath already exists, an error is returned. Only the last component of the newpath is created, the rest of the path must already exist.
- linkat: the existing file is specified by efd & existingpath, and the new pathname is specified by nfd & newpath.
- If either pathname is absolute, then the corresponding file descriptor argument is ignored.
- If either pathname is relative, it is evaluated relative to the corresponding file descriptor.
- If either file descriptor = AT_FDCWD & the corresponding pathname is relative, pathname is evaluated relative to the current directory.
- When the existing file is a symbolic link: If
- flag is clear: a link is created to the symbolic link itself.
- flag = AT_SYMLINK_FOLLOW: a link is created to the file to which the symbolic link points.
- The creation of the new directory entry and the increment of the link count must be an atomic operation. Most implementations require that both pathnames be on the same file system, POSIX.1 allows an implementation to support linking across file systems.
- If an implementation supports the creation of hard links to directories, it is restricted to only the superuser because such hard links can cause loops in the file system, which most utilities aren’t capable of handling. Many file system implementations disallow hard links to directories for this reason.
- To remove an existing directory entry, we call the unlink function.
#include <unistd.h>
int unlink(const char *pathname);
#include <fcntl.h>
#include <unistd.h>
int unlinkat(int fd, const char *pathname, int flag);
Both return: 0 if OK, −1 on error- These functions remove the directory entry and decrement the link count of the file referenced by pathname. If there are other links to the file, the data in the file is still accessible through the other links. The file is not changed if an error occurs.
- To unlink a file, we must have write permission and execute permission in the directory containing the directory entry. Section 4.10: if the sticky bit is set in this directory, we must have write permission for the directory and meet one of the following criteria:
- Own the file
- Own the directory
- Have superuser privileges
- Only when
1) the link count reaches 0 and
2) no process has the file open
can the contents of the file be deleted. - unlinkat:
- pathname is absolute: fd is ignored.
- pathname is relative: evaluates the pathname relative to the directory represented by fd.
- fd = AT_FDCWD: pathname is evaluated relative to the current working directory of the calling process.
- flag = AT_REMOVEDIR: remove a directory. If flag is clear, unlinkat operates like unlink.

#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> // open()
#include <unistd.h> // unlink()
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char *argv[])
{
if(open("temp.txt", O_RDWR | O_CREAT) < 0)
{
Exit("open error");
}
sleep(5);
if(unlink("temp.txt") < 0)
{
Exit("unlink error");
}
printf("file unlinked\n");
sleep(3);
printf("done\n");
exit(0);
}- This program opens a file and then unlinks it. The program then goes to sleep for 15 seconds before terminating.
- This property of unlink is used by a program to ensure that a temporary file it creates won’t be left around in case the program crashes. The process creates a file using either open or creat and then immediately calls unlink. The file is not deleted because it is still open. Only when the process either closes the file or terminates, which causes the kernel to close all its open files, is the file deleted.
- If pathname is a symbolic link, unlink removes the symbolic link, not the file referenced by the link.
- We can also unlink a file or a directory with the remove function. For a file, remove is identical to unlink. For a directory, remove is identical to rmdir.
#include <stdio.h>
int remove(const char *pathname);
Returns: 0 if OK, −1 on error4.16 rename and renameat Functions
- A file or a directory is renamed with rename/renameat.
#include <stdio.h>
int rename(const char *oldname, const char *newname);
#include <stdio.h>
#include <fcntl.h>
int renameat(int oldfd, const char *oldname, int newfd, const char *newname);
Both return: 0 if OK, −1 on error- If oldname specifies a file or a symbolic link. In this case, if newname exists, it cannot refer to a directory. If newname exists and is not a directory, it is removed, and oldname is renamed to newname. We must have write permission for the directory containing oldname and the directory containing newname.
- If oldname specifies a directory, then we are renaming a directory. If newname exists, it must refer to a directory, and that directory must be empty.(When we say that a directory is empty, we mean that the only entries in the directory are dot and dot-dot.) If newname exists and is an empty directory, it is removed, and oldname is renamed to newname.
- Additionally, when we’re renaming a directory, newname cannot contain a path prefix that names oldname. E.g.: can’t rename /usr/foo -> /usr/foo/testdir, because the old name(/usr/foo) is a path prefix of the new name and cannot be removed.
- If either oldname or newname refers to a symbolic link, then the link itself is processed, not the file to which it resolves.
- We can’t rename dot or dot-dot. Neither dot nor dot-dot can appear as the last component of oldname or newname.
- If oldname and newname refer to the same file, the function returns successfully without changing anything.
- If newname already exists, we need permissions as if we were deleting it.
- Because we’re removing the directory entry for oldname and possibly creating a directory entry for newname, we need write permission and execute permission in the directory containing oldname and in the directory containing newname.
- renameat = rename except either oldname or newname refers to a relative pathname.
- If oldname/newname specifies a relative pathname, it is evaluated relative to the directory referenced by oldfd/newfd.
- Either the oldfd or newfd arguments(or both) can be set to AT_FDCWD to evaluate the corresponding pathname relative to the current directory.
4.17 Symbolic Links
- A symbolic link is an indirect pointer to a file; hard link points directly to the i-node of the file.
- Symbolic links were introduced to get around the limitations of hard links.
- Hard links require the link and the file reside in the same file system.
- Only the superuser can create a hard link to a directory when supported by the underlying file system.
- There are no file system limitations on a symbolic link and what it points to, and anyone can create a symbolic link to a directory.
- Figure 4.17 summarizes whether the functions described in this chapter follow a symbolic link.
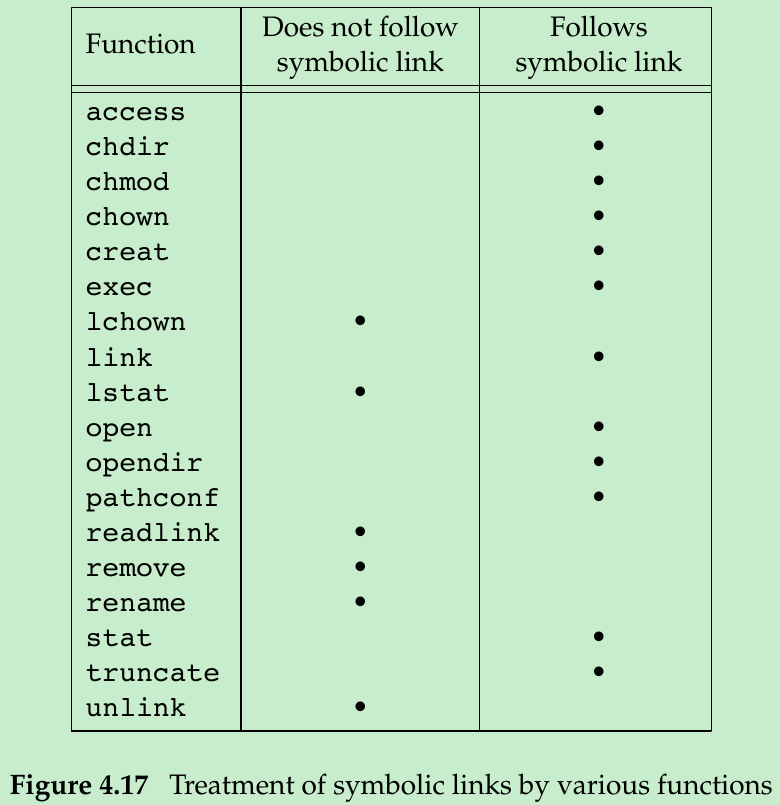
- The functions mkdir, mkfifo, mknod, and rmdir do not appear in this figure, as they return an error when the pathname is a symbolic link. The functions that take a file descriptor argument, such as fstat and fchmod, are not listed, as the function that returns the file descriptor(usually open) handles the symbolic link.
- One exception to Figure 4.17 occurs when the open function is called with both O_CREAT and O_EXCL set: if the pathname refers to a symbolic link, open will fail with errno set to EEXIST. This behavior is intended to close a security hole so that privileged processes can’t be fooled into writing to the wrong files.
Loop in the file system by using symbolic links.
- Most functions that look up a pathname return an errno of ELOOP when this occurs.
$ mkdir foo
$ touch foo/a #create a 0-length file
$ ln -s ../foo foo/testdir #create a symbolic link
$ ls -l foo
total 0
-rw-rw-r-- 1 xiang xiang 0 8月 6 10:12 a
lrwxrwxrwx 1 xiang xiang 6 8月 6 10:12 testdir -> ../foo- This creates a directory foo that contains the file “a” and a symbolic link that points to “foo” as is shown in Figure 4.18(a directory is a circle and a file is a square).
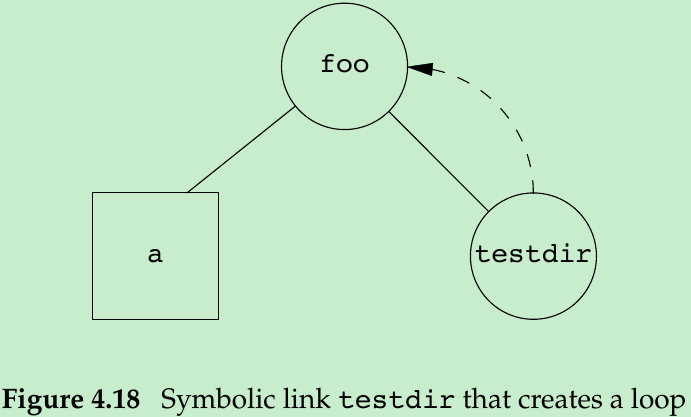
/foo $ cd testdir/
foo/testdir $ cd testdir/
foo/testdir/testdir $ cd testdir/
foo/testdir/testdir/testdir $ cd testdir/
foo/testdir/testdir/testdir/testdir $ cd testdir/
foo/testdir/testdir/testdir/testdir/testdir $ cd testdir/- We can unlink the file foo/testdir to remove a loop of this form, as unlink does not follow a symbolic link. But a hard link that forms this kind loop is difficult to remove. This is why the link function will not form a hard link to a directory unless the process has superuser privileges.
- With symbolic links and the mkdir function, there is no need for users to create hard links to directories.
- When we open a file, if the pathname passed to open specifies a symbolic link, open follows the link to the specified file. If the file pointed to by the symbolic link doesn’t exist, open returns an error saying that it can’t open the file.
$ ln -s /no/such/file myfile
$ ls myfile
myfile
$ cat myfile
cat: myfile: No such file or directory
$ ls -l myfile
lrwxrwxrwx 1 xiang xiang 13 8月 6 10:27 myfile -> /no/such/file- The file myfile exists, yet cat says there is no such file, because myfile is a symbolic link and the file pointed to by the symbolic link doesn’t exist. The -l option: the first character is an l, which means a symbolic link, and the sequence -> also indicates a symbolic link.
4.18 Creating and Reading Symbolic Links
- A symbolic link is created with either the symlink or symlinkat function.
#include <unistd.h>
int symlink(const char *actualpath, const char *sympath);
#include <fcntl.h>
#include <unistd.h>
int symlinkat(const char *actualpath, int fd, const char *sympath);
Both return: 0 if OK, −1 on error- A new directory entry, sympath, is created that points to actualpath. It is not required that actualpath exist when the symbolic link is created. Actualpath and sympath need not reside in the same file system.
- symlinkat
- = symlink: when sympath is absolute or fd = AT_FDCWD.
- Otherwise: sympath is evaluated relative to the directory referenced by the open file descriptor fd.
- The open function follows a symbolic link. The readlink and readlinkat functions open the link itself and read the name in the link.
#include <unistd.h>
ssize_t readlink(const char* restrict pathname, char *restrict buf, size_t bufsize);
#include <fcntl.h>
#include <unistd.h>
ssize_t readlinkat(int fd, const char* restrict pathname, char *restrict buf, size_t bufsize);
Both return: number of bytes read if OK, −1 on error- These functions combine the actions of open, read, and close. If successful, they return the number of bytes placed into buf. The contents of the symbolic link that are returned in buf are not null terminated.
- readlinkat:
- = readlink: when pathname is absolute or when fd = AT_FDCWD.
- Otherwise: when fd is a valid file descriptor of an open directory & pathname is relative, readlinkat evaluates the pathname relative to fd.
4.19 File Times
- Section 4.2: The timespec type in stat structure defines time in terms of seconds and nanoseconds. It includes at least the following fields:
time_t tv_sec;
long tv_nsec;- The actual resolution stored with each file’s attributes depends on the file system implementation.
- For file systems that store timestamps in second granularity, the nanoseconds fields = 0.
- For file systems that store timestamps in a resolution higher than seconds, the partial seconds value will be converted into nanoseconds and returned in the nanoseconds fields.
- Three time fields are maintained for each file. Their purpose in Figure 4.19.

- Difference between st_mtim and st_ctim
- st_mtim: when the contents of the file were last modified.
- st_ctim: when the i-node of the file was last modified. All the information in the i-node is stored separately from the actual contents of the file. Many operations that affect the i-node without changing the contents of the file: changing the file access permissions/user ID/number of links and so on.
- The access time is used by system administrators to delete files that have not been accessed for a certain amount of time.
- The ls command sorts only on one of the three time values. By default, when invoked with -l / -t, it uses the modification time of a file. -u use the access time, and -c use the changed-status time.
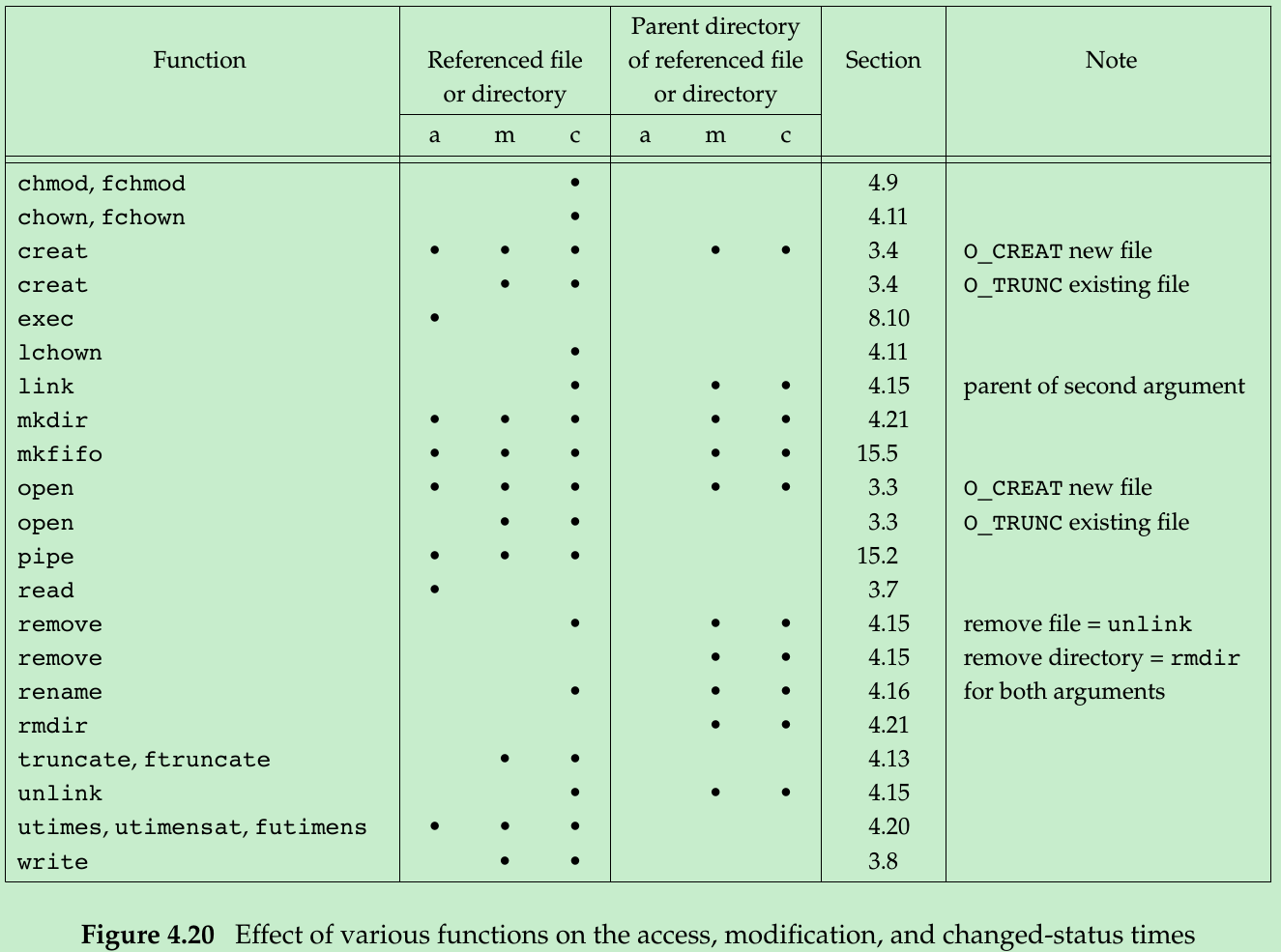
- Figure 4.20 summarizes the effects of the functions that we’ve described on three times.
- A directory is a file containing directory entries: filenames and associated i-node numbers. Adding, deleting, or modifying these directory entries can affect the three times associated with that directory. This is why Figure 4.20 contains one column for the three times associated with the parent directory of the referenced file or directory. For example, creating a new file affects the directory that contains the new file, and it affects the i-node for the new file. Reading or writing a file affects only the i-node of the file and has no effect on the directory.
4.20 futimens, utimensat, and utimes Functions
- The futimens and utimensat functions provide nanosecond granularity for specifying timestamps, using the timespec structure:
time_t tv_sec;
long tv_nsec;#include <fcntl.h>
#include <sys/stat.h>
int futimens(int fd, const struct timespec times[2]);
int utimensat(int fd, const char *path, const struct timespec times[2], int flag);
Both return: 0 if OK, −1 on error- In both functions, times[0] contains the access time, times[1] contains the modification time. The two time values are calendar times, which count seconds since the Epoch.
- Partial seconds are expressed in nanoseconds. Timestamps can be specified in one of four ways:
- The times argument is a null pointer: both timestamps are set to the current time.
- The times argument points to an array of two timespec structures. If either tv_nsec field has the special value UTIME_NOW, the corresponding timestamp is set to the current time. The corresponding tv_sec field is ignored.
- The times argument points to an array of two timespec structures. If either tv_nsec field has the special value UTIME_OMIT, then the corresponding timestamp is unchanged. The corresponding tv_sec field is ignored.
- The times argument points to an array of two timespec structures and the tv_nsec field contains a value other than UTIME_NOW or UTIME_OMIT. In this case, the corresponding timestamp is set to the value specified by the corresponding tv_sec and tv_nsec fields.
- The privileges required to execute these functions depend on the value of the times argument.
- If times is a null pointer or if either tv_nsec field is set to UTIME_NOW, either the effective user ID of the process must equal the owner ID of the file, the process must have write permission for the file, or the process must be a superuser process.
- If times is a non-null pointer and either tv_nsec field has a value other than UTIME_NOW or UTIME_OMIT, the effective user ID of the process must equal the owner ID of the file, or the process must be a superuser process.
- If times is a non-null pointer and both tv_nsec fields are set to UTIME_OMIT, no permissions checks are performed.
- With futimens, you need to open the file to change its times.
- utimensat:
- fd is a file descriptor of an open directory: pathname is evaluated relative to fd;
- fd = AT_FDCWD: pathname is evaluated relative to the current directory of the calling process.
- pathname is absolute: fd is ignored.
- flag = AT_SYMLINK_NOFOLLOW: the times of the symbolic link itself are changed(if the pathname refers to a symbolic link). The default behavior is to follow a symbolic link and modify the times of the file to which the link refers.
#include <sys/time.h>
int utimes(const char *pathname, const struct timeval times[2]);
Returns: 0 if OK, −1 on error- The utimes function operates on a pathname. The times argument is a pointer to an array of two timestamps(access time and modification time) which are expressed in seconds and microseconds.
struct timeval
{
time_t tv_sec; /* seconds */
long tv_usec; /* microseconds */
};- We are unable to specify a value for the changed-status time(st_ctim: the time the i-node was last changed) since it is automatically updated when the utime function is called.
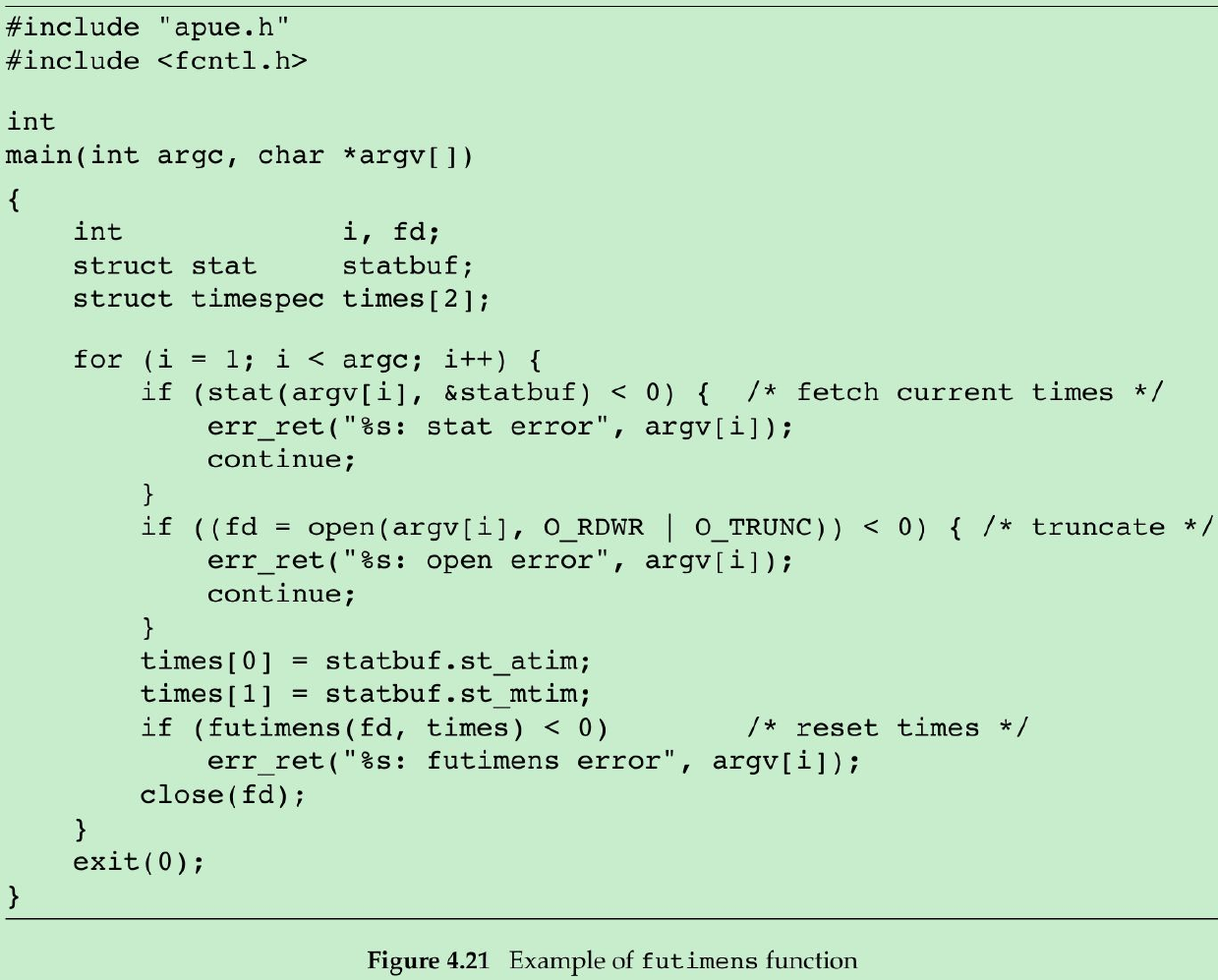
- This program truncates files to zero length using the O_TRUNC option of the open function, but does not change their access time or modification time.
- To do this, the program first obtains the times with the stat function, truncates the file, and then resets the times with the futimens function.
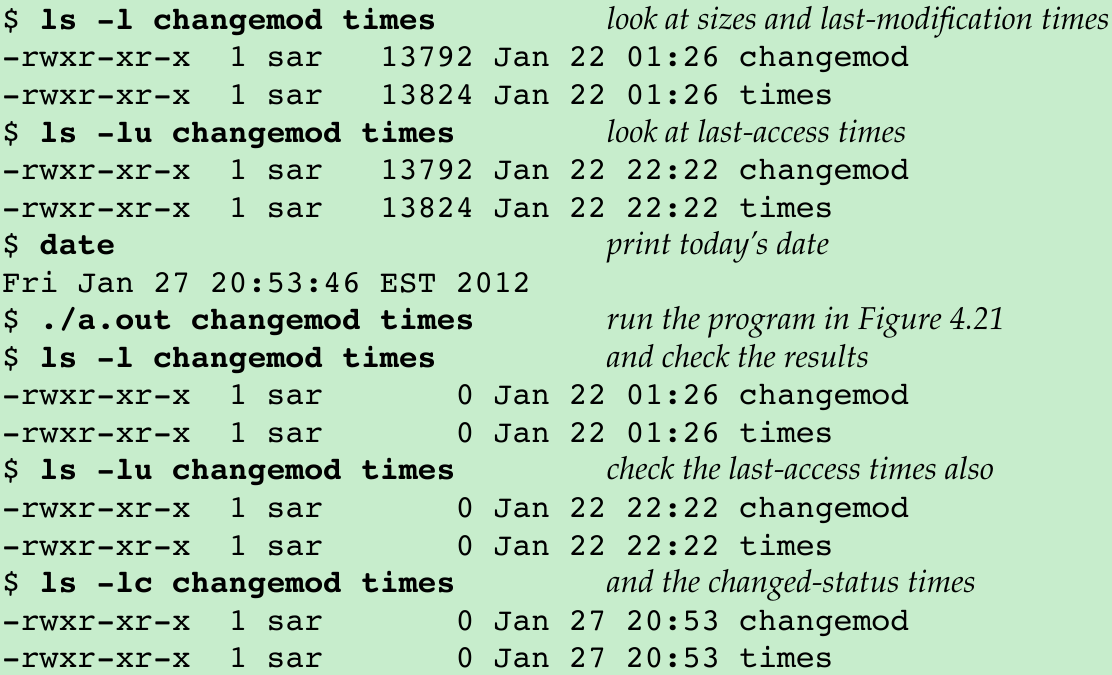
- Result: last-modification times and last-access times have not changed; changed-status times have changed to the time that the program was run.
4.21 mkdir, mkdirat, and rmdir Functions
- Directories are created with the mkdir and mkdirat functions, and deleted with the rmdir function.
#include <sys/stat.h>
#include <sys/types.h>
int mkdir(const char *pathname, mode_t mode);
#include <fcntl.h>
#include <sys/stat.h>
int mkdirat(int fd, const char *pathname, mode_t mode);
Both return: 0 if OK, −1 on error- These functions create a new, empty directory. The entries for dot and dot-dot are created automatically. The specified file access permissions, mode, are modified by the file mode creation mask of the process. We normally want at least one of the execute bits enabled, to allow access to filenames within the directory.
- The user ID and group ID of the new directory are established according to the rules described in Section 4.6.
- Linux 3.2.0 have the new directory inherit the set-group-ID bit from the parent directory. Files created in the new directory will then inherit the group ID of that directory. The file system implementation determines whether this behavior is supported. For example, the ext2, ext3, and ext4 file systems allow this behavior to be controlled by an option to the mount(1) command. With the Linux implementation of the UFS file system, the behavior is not selectable; it inherits the set-group-ID bit to mimic the historical BSD implementation, where the group ID of a directory is inherited from the parent directory.
- mkdirat:
- =mkdir: when fd = AT_FDCWD, or pathname is absolute;
- Otherwise: fd is an open directory from which relative pathnames will be evaluated.
- An empty directory(one that contains entries only for dot and dot-dot) is deleted with the rmdir function.
#include <unistd.h>
int rmdir(const char *pathname);
Returns: 0 if OK, −1 on error- If the link count of the directory becomes 0 with this call, and if no other process has the directory open, then the space occupied by the directory is freed. If one or more processes have the directory open when the link count reaches 0, the last link is removed and the dot and dot-dot entries are removed before this function returns.
- No new files can be created in the directory. The directory is not freed until the last process closes it. Even though some other process has the directory open, it can’t be doing much in the directory, as the directory had to be empty for the rmdir function to succeed.
4.22 Reading Directories
- Directories can be read by anyone who has access permission to read the directory. But only the kernel can write to a directory, to preserve file system sanity. The write permission bits and execute permission bits for a directory determine if we can create new files in the directory and remove files from the directory, they don’t specify if we can write to the directory itself.
- The format of a directory depends on the UNIX implementation and the design of the file system.
#include <sys/types.h>
#include <dirent.h>
DIR *opendir(const char *pathname);
DIR *fdopendir(int fd);
Both return: pointer if OK, NULL on error
#include <dirent.h>
struct dirent *readdir(DIR *dp);
Returns: pointer if OK, NULL at end of directory or error
#include <sys/types.h>
#include <dirent.h>
void rewinddir(DIR *dp);
int closedir(DIR *dp);
Returns: 0 if OK, −1 on error
#include <dirent.h>
long telldir(DIR *dp);
Returns: current location in directory associated with dp
#include <dirent.h>
void seekdir(DIR *dp, long loc);- The fdopendir function provides a way to convert an open file descriptor into a DIR structure for use by the directory handling functions.
- The dirent structure defined in
ino_t d_ino; /* i-node number */
char d_name[]; /* null-terminated filename */- The size of the d_name entry isn’t specified, but it is guaranteed to hold at least NAME_MAX characters, not including the terminating null byte(Figure 2.15.)
- Since the filename is null terminated, it doesn’t matter how d_name is defined in the header, because the array size doesn’t indicate the length of the filename.
- The DIR structure is an internal structure used by these seven functions to maintain information about the directory being read.
- The pointer to a DIR structure returned by opendir and fdopendir is then used with the other five functions. The opendir function initializes things so that the first readdir returns the first entry in the directory. When the DIR structure is created by fdopendir, the first entry returned by readdir depends on the file offset associated with the file descriptor passed to fdopendir. Note that the ordering of entries within the directory is implementation dependent and is usually not alphabetical.



- This program takes the starting pathname and recursively descends the hierarchy from that point.
4.23 chdir, fchdir, and getcwd Functions
- Every process has a current working directory where the search for all relative pathnames starts. The current working directory is an attribute of a process; the home directory is an attribute of a login name.
#include <unistd.h>
int chdir(const char *pathname);
int fchdir(int fd);
Both return: 0 if OK, −1 on error- We can specify the new current working directory either as a pathname or through an open file descriptor.

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
if(chdir("/tmp") < 0)
{
Exit("chdir error");
}
printf("chdir to /tmp succeeded\n");
exit(0);
}$ pwd
/home/xiang/Gao/Notes/OS/APUE/Codes
$ ./a.out
chdir to /tmp succeeded
$ pwd
/home/xiang/Gao/Notes/OS/APUE/Codes- Because it is an attribute of a process, the current working directory cannot affect processes that invoke the process that executes the chdir. So, the current working directory for the shell that executed this program didn’t change.
- The kernel keeps information about the directory, such as a pointer to the directory’s v-node.
- We need a function that starts at the current working directory (dot) and works its way up the directory hierarchy, using dot-dot to move up one level. At each level, the function reads the directory entries until it finds the name that corresponds to the i-node of the directory that it just came from. Repeating this procedure until the root is encountered yields the entire absolute pathname of the current working directory. Fortunately, a function already exists that does this work for us.
#include <unistd.h>
char *getcwd(char *buf, size_t size);
Returns: buf if OK, NULL on error- We pass to this function the address of a buffer, buf, and its size(in bytes). The buffer must be large enough to accommodate the absolute pathname plus a terminating null byte, or else an error will be returned.

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
char ptr[256];
if(chdir("/home/xiang/Gao") < 0)
{
Exit("chdir failed");
}
if(getcwd(ptr, 256) == NULL)
{
Exit("getcwd failed");
}
printf("cwd = %s\n", ptr);
exit(0);
}- This program changes to a specific directory and then calls getcwd to print the working directory.
$ ./a.out
cwd = /var/spool/uucppublic
$ ls -l /usr/spool
lrwxrwxrwx 1 root 12 Jan 31 07:57 /usr/spool -> ../var/spool- chdir follows the symbolic link, but when it goes up the directory tree, getcwd has no idea when it hits the /var/spool directory that it is pointed to by the symbolic link /usr/spool. This is a characteristic of symbolic links.
- Use getcwd when we needs to return to the location in the file system where it started out. We can save the starting location by calling getcwd before we change our working directory. After we complete our processing, we can pass the pathname obtained from getcwd to chdir to return to our starting location in the file system.
- fchdir: We can open the current directory and save the file descriptor before we change to a different location in the file system. When we want to return to where we started, we can pass the file descriptor to fchdir.
4.24 Device Special Files
- We’ll need to use the two fields st_dev and st_rdev in Section 18.9 when we write the ttyname function. The rules for their use are simple.
- Every file system is known by its major and minor device numbers, which are encoded in the primitive system data type dev_t. The major number identifies the device driver and sometimes encodes which peripheral board to communicate with; the minor number identifies the specific sub-device. A disk drive often contains several file systems. Each file system on the same disk drive would usually have the same major number, but a different minor number.
- We can access the major and minor device numbers through two macros: major and minor. Linux defines these macros in
4.25 Summary of File Access Permission Bits
- Figure 4.26 summarizes these permission bits and their interpretation when applied to a regular file and a directory.
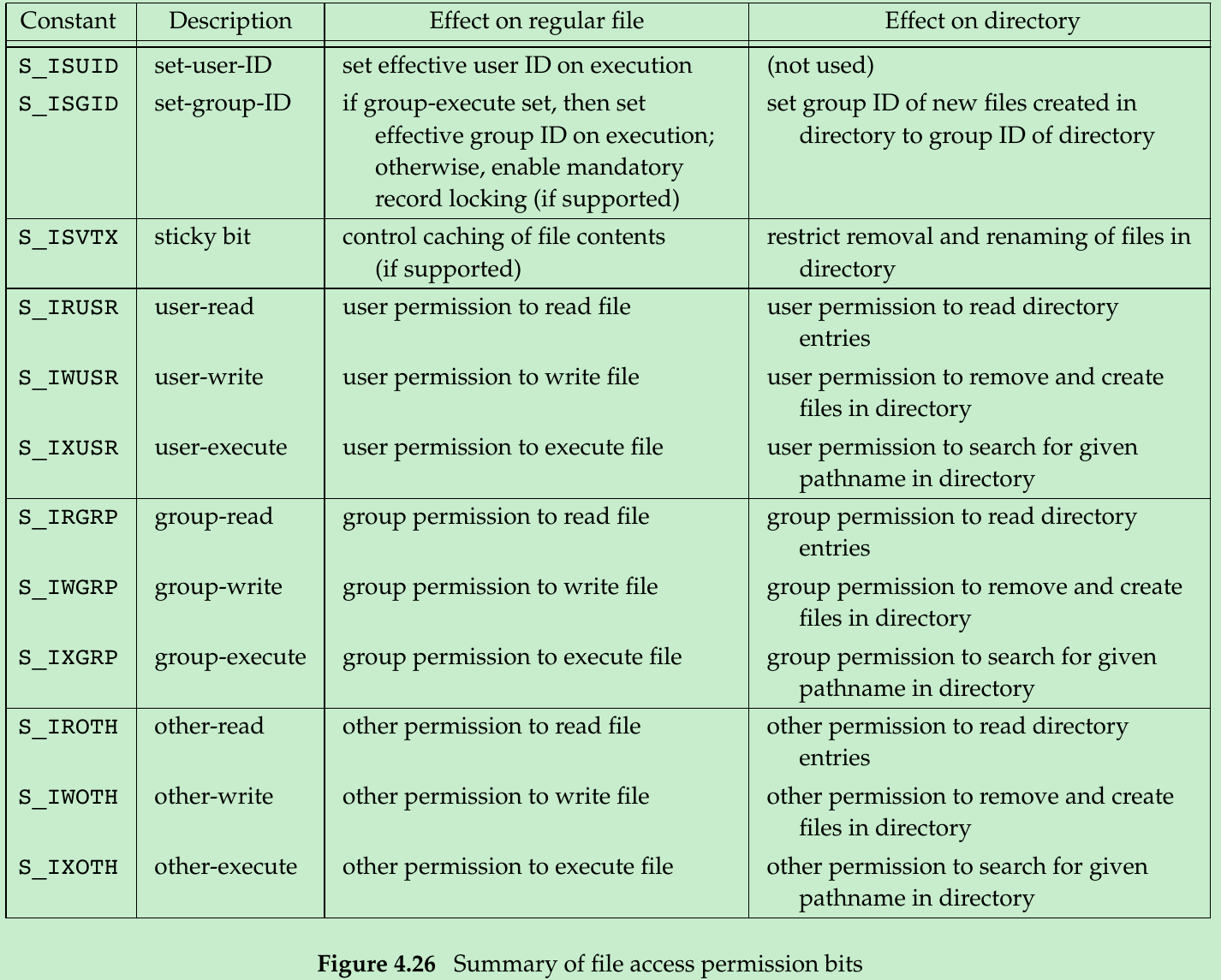
- The final nine constants can also be grouped into threes, as follows:
S_IRWXU = S_IRUSR | S_IWUSR | S_IXUSR
S_IRWXG = S_IRGRP | S_IWGRP | S_IXGRP
S_IRWXO = S_IROTH | S_IWOTH | S_IXOTH
4.26 Summary
Exercises 1
Modify the program in Figure 4.3 to use stat instead of lstat. What changes if one of the command-line arguments is a symbolic link?
- If stat is called, it always tries to follow a symbolic link, so the program will never print a file type of ‘‘symbolic link.’’ If the symbolic link points to a nonexistent file, stat returns an error.
Exercises 2.
What happens if the file mode creation mask is set to 777 (octal)? Verify the results using your shell’s umask command.
- All permissions are turned off:
$ umask 777
$ date > temp
$ ls -l temp
---------- 1 xiang xiang 43 8月 7 20:01 tempExercises 3.
Verify that turning off user-read permission for a file that you own denies your access to the file.
$ date > foo
$ chmod u-r foo
$ ls -l foo
--w-rw-r-- 1 xiang xiang 43 8月 7 20:05 foo
$ cat foo
cat: foo: Permission deniedExercises 4.
Run the program in Figure 4.9 after creating the files foo and bar. What happens?
- If we try, using either open or creat, to create a file that already exists, the file’s access permission bits are not changed.

Exercises 5.
In Section 4.12, we said that a file size of 0 is valid for a regular file. We also said that the st_size field is defined for directories and symbolic links. Should we ever see a file size of 0 for a directory or a symbolic link?
- The size of a directory should never be 0, since there should always be entries for dot and dot-dot.
- The size of a symbolic link is the number of characters in the pathname contained in the symbolic link, and this pathname must always contain at least one character.
Exercises 7.
Note in the output from the ls command in Section 4.12 that the files core and core.copy have different access permissions. If the umask value didn’t change between the creation of the two files, explain how the difference could have occurred.
- The kernel has a default setting for the file access permission bits when it creates a new core file. In this example, it was rw-r–r–. This default value may or may not be modified by the umask value.
- The shell also has a default setting for the file access permission bits when it creates a new file for redirection. In this example, it was rw-rw-rw-, and this value is always modified by our current umask. In this example, our umask was 02.
Exercises 8.
When running the program in Figure 4.16, we check the available disk space with the df(1) command. Why didn’t we use the du(1) command?
- We can’t use du, because it requires either the name of the file, as in
du tempfile
or a directory name, as in
du .
But when the unlink function returns, the directory entry for tempfile is gone. - The du . command just shown would not account for the space still taken by tempfile. We have to use the df command in this example to see the actual amount of free space on the file system.
Exercises 9.
In Figure 4.20, we show the unlink function as modifying the changed-status time of the file itself. How can this happen?
- If the link being removed is not the last link to the file, the file is not removed. In this case, the changed-status time of the file is updated. But if the link being removed is the last link to the file, it makes no sense to update this time, because all the information about the file (the i-node) is removed with the file.
Exercises 10.
In Section 4.22, how does the system’s limit on the number of open files affect the myftw function?
- We recursively call our function dopath after opening a directory with opendir. Assuming that opendir uses a single file descriptor, this means that each time we descend one level, we use another descriptor. (We assume that the descriptor isn’t closed until we’re finished with a directory and call closedir.) This limits the depth of the file system tree that we can traverse to the maximum number of open descriptors for the process. Note that the nftw function as specified in the XSI option of the Single UNIX Specification allows the caller to specify the number of descriptors to use, implying that it can close and reuse descriptors.
Exercises 12.
Each process also has a root directory that is used for resolution of absolute pathnames. This root directory can be changed with the chroot function. Look up the description for this function in your manuals. When might this function be useful?
- The chroot function is used by the Internet File Transfer Protocol (FTP) program to aid in security. Users without accounts on a system (termed anonymous FTP) are placed in a separate directory, and a chroot is done to that directory. This prevents the user from accessing any file outside this new root directory.
- In addition, chroot can be used to build a copy of a file system hierarchy at a new location and then modify this new copy without changing the original file system. This could be used, for example, to test the installation of new software packages.
- Only the superuser can execute chroot, and once you change the root of a process, it (and all its descendants) can never get back to the original root.
Exercises 13.
How can you set only one of the two time values with the utimes function?
- First, call stat to fetch the three times for the file; then call utime to set the desired value. The value that we don’t want to change in the call to utime should be the corresponding value from stat.
Exercises 14.
Some versions of the finger(1) command output ‘‘New mail received …’’ and ‘‘unread since …’’ where … are the corresponding times and dates. How can the program determine these two times and dates?
- The finger(1) command calls stat on the mailbox. The last-modification time is the time that mail was last received, and the last-access time is when the mail was last read.
Exercises 15.
Examine the archive formats used by the cpio(1) and tar(1) commands. (These descriptions are usually found in Section 5 of the UNIX Programmer’s Manual.) How many of the three possible time values are saved for each file? When a file is restored, what value do you think the access time is set to, and why?
- Both cpio and tar store only the modification time (st_mtime) in the archive. The access time isn’t stored, because its value corresponds to the time the archive was created, since the file has to be read to be archived. The -a option to cpio has it reset the access time of each input file after the file has been read. This way, the creation of the archive doesn’t change the access time. (Resetting the access time, however, does modify the changed-status time.) The changed-status time isn’t stored in the archive, because we can’t set this value on extraction even if it was archived. (The utimes function and its related functions, futimens and utimensat, can change only the access time and the modification time.)
- When the archive is read back (extracted), tar, by default, restores the modification time to the value in the archive. The m option to tar tells it to not restore the modification time from the archive; instead, the modification time is set to the time of extraction. In all cases with tar, the access time after extraction will be the time of extraction.
- In contrast, cpio sets the access time and the modification time to the time of extraction. By default, it doesn’t try to set the modification time to the value on the archive. The -m option to cpio has it set both the access time and the modification time to the value that was archived.
Exercises 16.
Does the UNIX System have a fundamental limitation on the depth of a directory tree? To find out, write a program that creates a directory and then changes to that directory, in a loop. Make certain that the length of the absolute pathname of the leaf of this directory is greater than your system’s PATH_MAX limit. Can you call getcwd to fetch the directory’s pathname? How do the standard UNIX System tools deal with this long pathname? Can you archive the directory using either tar or cpio?
- The kernel has no inherent limit on the depth of a directory tree. Nevertheless, many commands will fail on pathnames that exceed PATH_MAX. The program shown in Figure C.3 creates a directory tree that is 1,000 levels deep, with each level being a 45-character name. We are able to create this structure on all platforms; however, we cannot obtain the absolute pathname of the directory at the 1,000th level using getcwd on all platforms. On Mac OS X 10.6.8, we can never get getcwd to succeed while in the directory at the end of this long path.
- The program is able to retrieve the pathname on FreeBSD 8.0, Linux 3.2.0, and Solaris 10, but we have to call realloc numerous times to obtain a buffer that is large enough. Running this program on Linux 3.2.0 gives us

- We are not able to archive this directory, however, using cpio. It complains that many of the filenames are too long. In fact, cpio is unable to archive this directory on all four platforms. In contrast, we can archive this directory using tar on FreeBSD 8.0, Linux 3.2.0, and Mac OS X 10.6.8. However, we are unable to extract the directory hierarchy from the archive on Linux 3.2.0.
Exercises 17.
In Section 3.16, we described the /dev/fd feature. For any user to be able to access these files, their permissions must be rw-rw-rw-. Some programs that create an output file delete the file first, in case it already exists, ignoring the return code:
unlink(path);
if ((fd = creat(path, FILE_MODE)) < 0)
err_sys(...);What happens if path is /dev/fd/1?
- The /dev directory has write permissions turned off to prevent a normal user from removing the filenames in the directory. This means that the unlink attempt fails.
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1















 6087
6087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









