







Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
15.1 Introduction
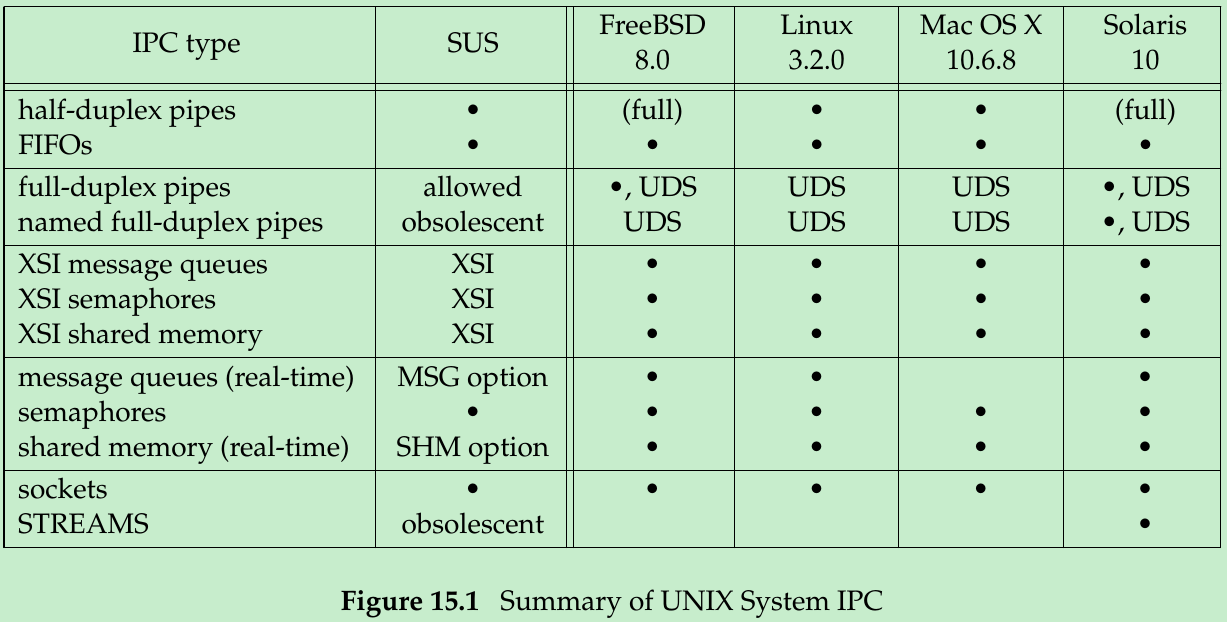
- Figure 15.1 summarizes the various forms of IPC that are supported by the four systems discussed in this text.
- For full-duplex pipes, if the feature can be provided through UNIX domain sockets(Section 17.2), we show “UDS” in the column.
- The first ten forms of IPC in Figure 15.1 are restricted to IPC between processes on the same host. The final two rows(sockets and STREAMS) are the only two forms that are supported for IPC between processes on different hosts.
15.2 Pipes
- Pipes have two limitations.
- They are half duplex(i.e., data flows in only one direction).
- Pipes can be used only between processes that have a common ancestor. A pipe is created by a process, that process calls fork, and the pipe is used between the parent and the child.
- FIFOs(Section 15.5) get around the second limitation, and UNIX domain sockets(Section 17.2) get around both limitations.
- Every time you type a sequence of commands in a pipeline for the shell to execute, the shell creates a separate process for each command and links the standard output of one process to the standard input of the next using a pipe.
#include <unistd.h>
int pipe(int fd[2]);
Returns: 0 if OK, -1 on error- A pipe is created by calling the pipe function. Two file descriptors are returned through the fd argument: fd[0] is open for reading, and fd[1] is open for writing. The output of fd[1] is the input for fd[0].
- POSIX.1 allows for systems to support full-duplex pipes. For these implementations, fd[0] and fd[1] are open for both reading and writing.
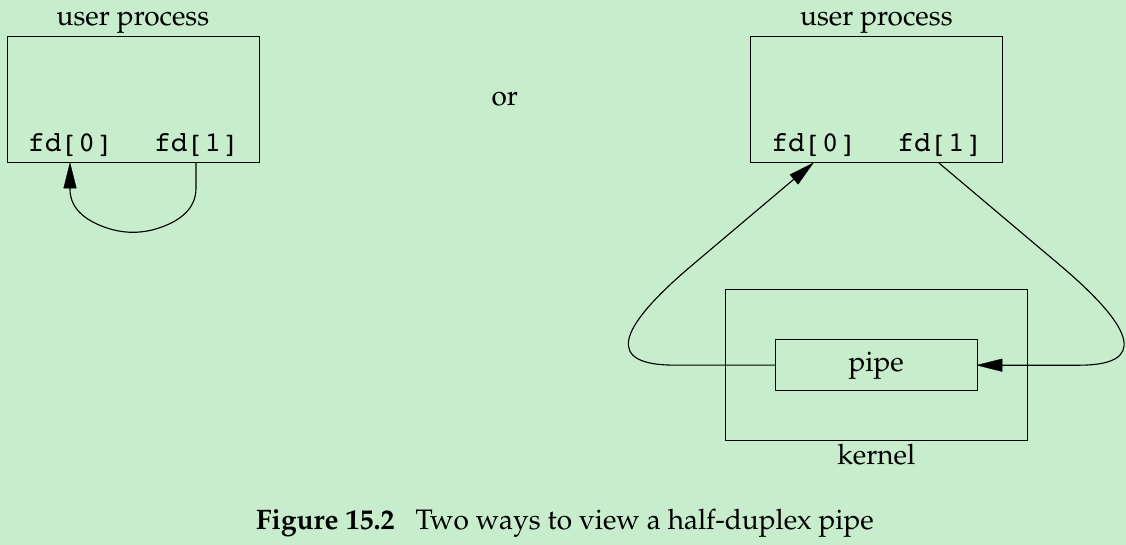
- Two ways to picture a half-duplex pipe are shown in Figure 15.2. The left half shows the two ends of the pipe connected in a single process. The right half emphasizes that the data in the pipe flows through the kernel.
- The fstat function(Section 4.2) returns a file type of FIFO for the file descriptor of either end of a pipe. We can test for a pipe with the S_ISFIFO macro.
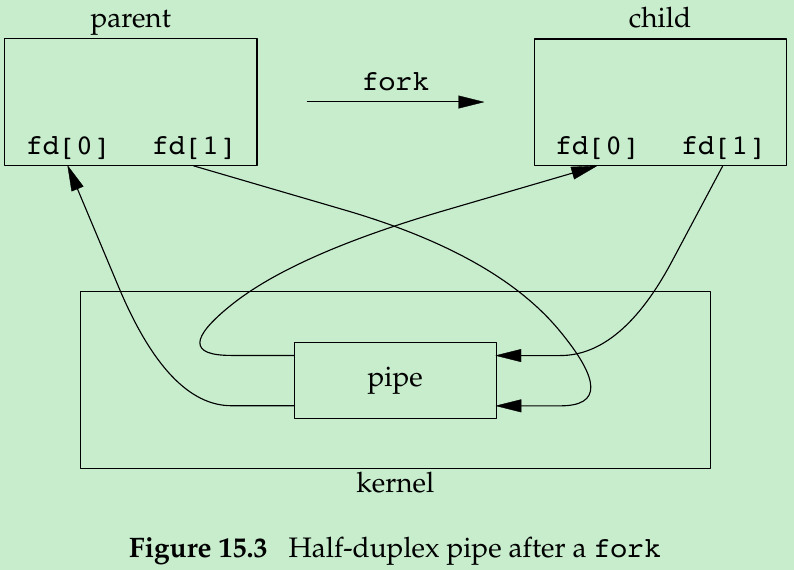
- Normally, the process that calls pipe then calls fork, creating an IPC channel from the parent to the child, or vice versa. Figure 15.3 shows this scenario.
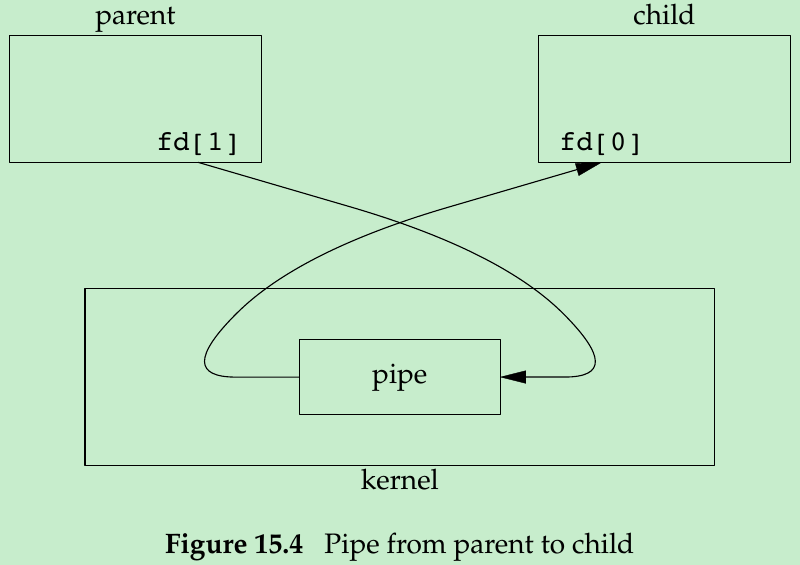
- For a pipe from the parent to the child, the parent closes the read end of the pipe(fd[0]), and the child closes the write end(fd[1]). Figure 15.4 shows the resulting arrangement of descriptors.(For a pipe from the child to the parent, the parent closes fd[1], and the child closes fd[0].)
- When one end of a pipe is closed, two rules apply.
- If we read from a pipe whose write end has been closed, read returns 0 to indicate an end of file after all the data has been read.
- If we write to a pipe whose read end has been closed, the SIGPIPE signal is generated. If we either ignore the signal or catch it and return from the signal handler, write returns -1 with errno set to EPIPE.
- When we’re writing to a pipe(or FIFO), the constant PIPE_BUF specifies the kernel’s pipe buffer size. A write of PIPE_BUF bytes or less will not be interleaved with the writes from other processes to the same pipe(or FIFO). But if multiple processes are writing to a pipe(or FIFO), and if we write more than PIPE_BUF bytes, the data might be interleaved with the data from the other writers. We can determine the value of PIPE_BUF by using pathconf or fpathconf(Figure 2.12).
- Figure 15.5 shows the code to create a pipe between a parent and its child and to send data down the pipe.

#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#define MAX 100
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
int fd[2];
pid_t pid;
char line[MAX];
int nread;
if(pipe(fd) < 0)
{
Exit("pipe error");
}
if((pid = fork()) < 0)
{
Exit("fork error");
}
else if(pid > 0)
{
close(fd[0]);
write(fd[1], "gaoxiangnumber1\n", 16);
}
else
{
close(fd[1]);
nread = read(fd[0], line, MAX);
write(STDOUT_FILENO, line, nread);
}
exit(0);
}- What’s interesting is to duplicate the pipe descriptors onto standard input or standard output. The child then runs some other program, and that program can either read from its standard input(the pipe that we created) or write to its standard output(the pipe).
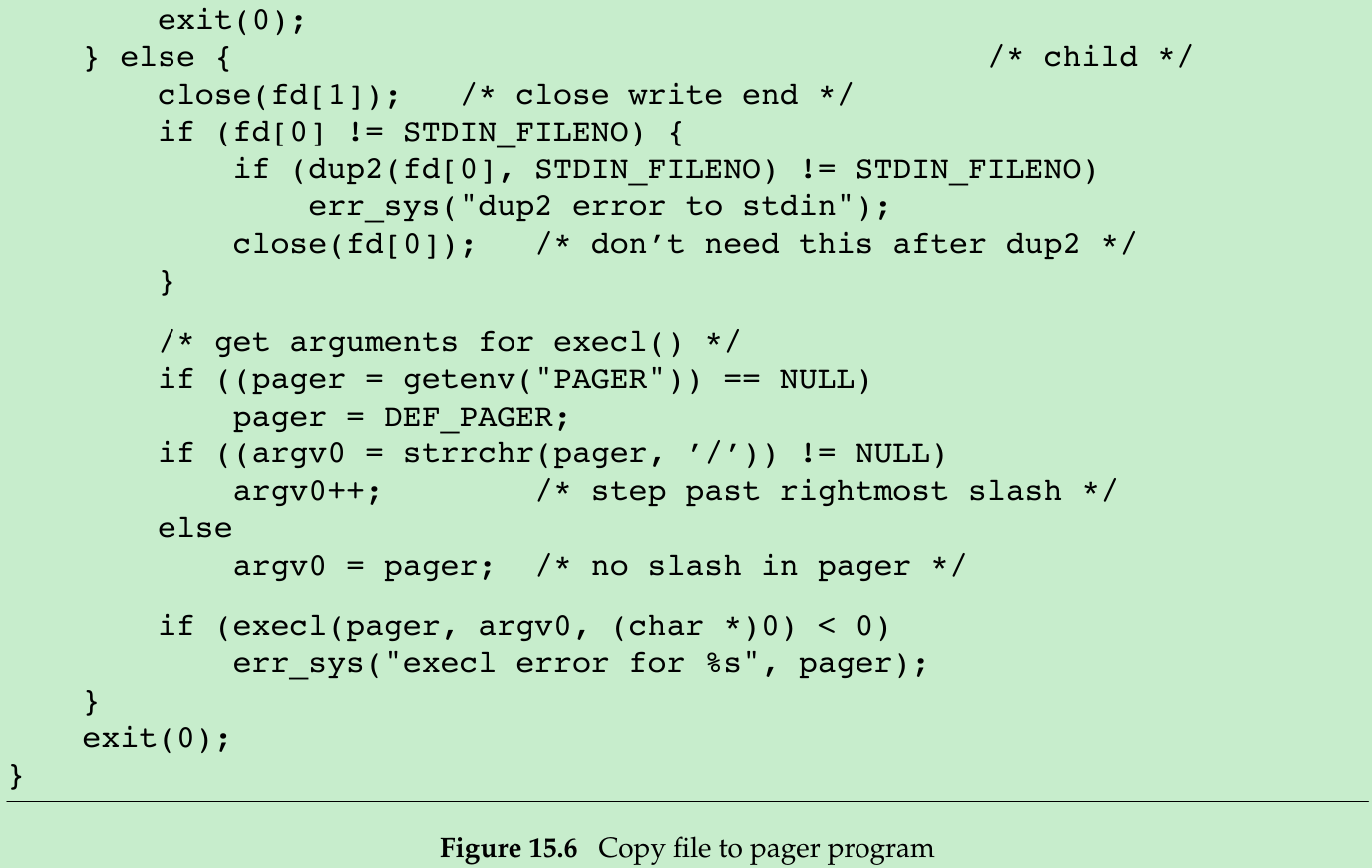
- Consider a program that displays output that it has created, one page at a time. To avoid writing all the data to a temporary file and calling system to display that file, we want to pipe the output directly to the pager. So, we create a pipe, fork a child process, set up the child’s standard input to be the read end of the pipe, and exec the user’s pager program. Figure 15.6: This example takes a command-line argument to specify the name of a file to display.

#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/wait.h>
#include <string.h>
#define MAX 1000
#define DEF_PAGER "/bin/more"
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char **argv)
{
int nread;
char line[MAX];
int fd[2];
pid_t pid;
char *pager, *argv0;
FILE *fp;
if(argc != 2)
{
Exit("Usage: ./a.out pathname");
}
if((fp = fopen(argv[1], "r")) == NULL)
{
Exit("Can't open this file");
}
if(pipe(fd) < 0)
{
Exit("pipe error");
}
if((pid = fork()) < 0)
{
Exit("fork error");
}
else if(pid > 0)
{
close(fd[0]);
while(fgets(line, MAX, fp) != NULL)
{
nread = strlen(line);
if(write(fd[1], line, nread) != nread)
{
Exit("write error to pipe");
}
}
if(ferror(fp))
{
Exit("fgets error");
}
close(fd[1]);
if(waitpid(pid, NULL, 0) < 0)
{
Exit("waitpid error");
}
exit(0);
}
else
{
close(fd[1]);
if(fd[0] != STDIN_FILENO)
{
if(dup2(fd[0], STDIN_FILENO) != STDIN_FILENO)
{
Exit("dup2 error to stdin");
}
close(fd[0]);
}
if((pager = getenv("PAGER")) == NULL)
{
pager = DEF_PAGER;
}
if((argv0 = strrchr(pager, '/')) == NULL)
{
argv0++;
}
else
{
argv0 = pager;
}
if(execl(pager, argv0,(char *)0) < 0)
{
Exit("execl error for pager");
}
}
exit(0);
}- Before calling fork, we create a pipe. After the fork, the parent closes its read end, and the child closes its write end. The child then calls dup2 to have its standard input be the read end of the pipe. When the pager program is executed, its standard input will be the read end of the pipe.
- When we duplicate one descriptor onto another(fd[0] onto standard input in the child), we have to be careful that the descriptor doesn’t already have the desired value. If the descriptor already had the desired value and we called dup2 and close, the single copy of the descriptor would be closed.(Section 3.12: the operation of dup2 when its two arguments are equal.)
- Figure 15.7 shows implementation of the five functions TELL_WAIT, TELL_PARENT, TELL_CHILD, WAIT_PARENT, and WAIT_CHILD using pipes.

- We create two pipes before fork(Figure 15.8). The parent writes the character “p” across the top pipe when TELL_CHILD is called, and the child writes the character “c” across the bottom pipe when TELL_PARENT is called. The corresponding WAIT_xxx functions do a blocking read for the single character.
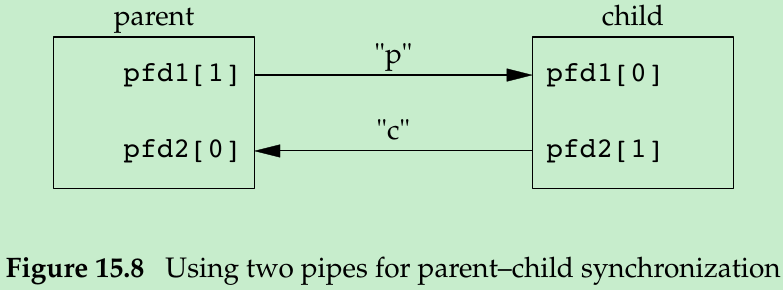
- Each pipe has an extra reader which doesn’t matter. In addition to the child reading from pfd1[0], the parent has this end of the top pipe open for reading. This doesn’t affect us, since the parent doesn’t try to read from this pipe.
15.3 popen and pclose Functions
- The popen and pclose functions handle all work: creating a pipe, forking a child, closing the unused ends of the pipe, executing a shell to run the command, and waiting for the command to terminate.
#include <stdio.h>
FILE *popen(const char *cmdstring, const char *type);
Returns: file pointer if OK, NULL on error
int pclose(FILE *fp);
Returns: termination status of cmdstring, or -1 on error- popen does a fork and exec to execute the cmdstring and returns a standard I/O file pointer.
- If type is “r”, the file pointer is connected to the standard output of cmdstring(Figure 15.9).


- pclose closes the standard I/O stream, waits for the command to terminate, and returns the termination status of the shell.(the termination status in Section 8.6. The system function in Section 8.13 also returns the termination status.) If the shell cannot be executed, the termination status returned by pclose is as if the shell had executed exit(127).
- The cmdstring is executed by the Bourne shell, as in
sh -c cmdstring
The shell expands any of its special characters in cmdstring. This allows us:
fp = popen("ls *.c", "r");or
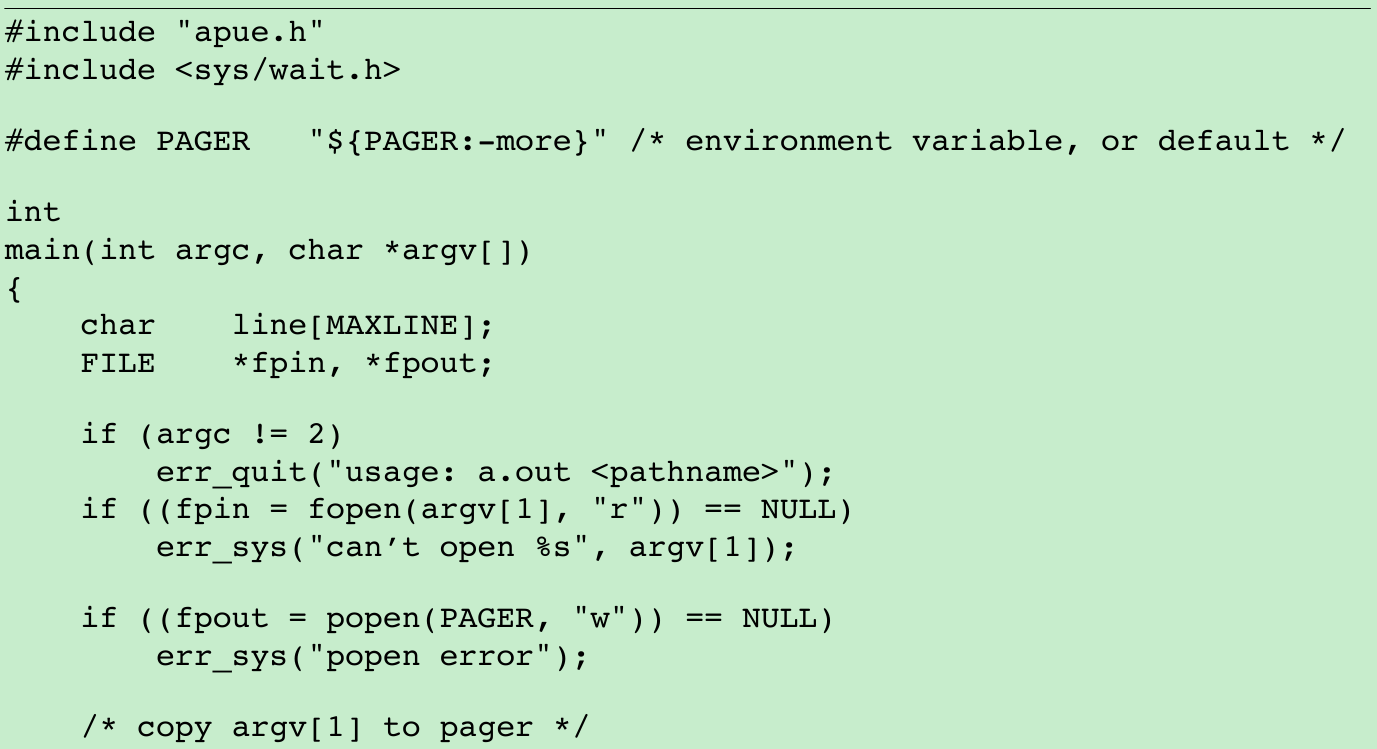
fp = popen("cmd 2>&1", "r"); - Figure 15.11: using popen to redo the program from Figure 15.6.

#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#define MAX 1000
#define PAGER "${PAGER:-more}"
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main(int argc, char **argv)
{
if(argc != 2)
{
Exit("Usage: ./a.out pathname");
}
char line[MAX];
FILE *fpin, *fpout;
if((fpin = fopen(argv[1], "r")) == NULL)
{
Exit("Can't open file.");
}
if((fpout = popen(PAGER, "w")) == NULL)
{
Exit("popen error");
}
while(fgets(line, MAX, fpin) != NULL)
{
if(fputs(line, fpout) == EOF)
{
Exit("fputs error to pipe");
}
}
if(ferror(fpin))
{
Exit("fgets error");
}
if(pclose(fpout) == -1)
{
Exit("pclose error");
}
exit(0);
}- The shell command
${PAGER:-more}says to use the value of the shell variable PAGER if it is defined and non-null; otherwise, use the string more.


#include <stdio.h>
#include <stdlib.h>
static pid_t *childpid = NULL;
static int maxfd;
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
FILE *Popen(const char *cmdstring, const char *type)
{
if((type[0] != 'r' && type[0] != 'w') || type[1] != 0)
{
errno = EINVAL; // Invalid argument
return NULL;
}
if(childpid == NULL)
{
maxfd = open_max(); // Figure 2.17
if((childpid = calloc(maxfd, sizeof(pid_t))) == NULL)
{
return NULL;
}
}
int pfd[2];
pid_t pid;
FILE *fp;
if(pipe(pfd) < 0)
{
return NULL;
}
if(pfd[0] >= maxfd || pfd[1] >= maxfd)
{
close(pfd[0]);
close(pfd[1]);
errno = EMFILE; // Too many open files
return NULL;
}
if((pid = fork()) < 0)
{
return NULL;
}
else if(pid == 0)
{
if(*type == 'r')
{
close(pfd[0]);
if(pfd[1] != STDOUT_FILENO)
{
dup2(pfd[1], STDOUT_FILENO);
close(pfd[1]);
}
}
else
{
close(pfd[1]);
if(pfd[0] != STDIN_FILENO)
{
dup2(pfd[0], STDIN_FILENO);
close(pfd[0]);
}
}
for(int fd = 0; fd < maxfd; ++fd)
{
if(childpid[fd] > 0)
{
close(fd);
}
}
execl("/bin/sh", "sh", "-c", cmdstring,(char *)0);
_exit(127);
}
if(*type == 'r')
{
close(pfd[1]);
if((fp = fdopen(pfd[0], type)) == NULL)
{
return NULL;
}
}
else
{
close(pfd[0]);
if((fp = fdopen(pfd[1], type)) == NULL)
{
return NULL;
}
}
childpid[fileno(fp)] = pid;
return fp;
}
int Pclose(FILE *fp)
{
int fd, stat;
pid_t pid;
if(childpid == NULL)
{
errno = EINVAL;
return -1;
}
fd = fileno(fp);
if(fd >= maxfd)
{
errno = EINVAL;
return -1;
}
if((pid = childpid[fd]) == 0)
{
errno = EINVAL;
return -1;
}
childpid[fd] = 0;
if(fclose(fp) == EOF)
{
return -1;
}
while(waitpid(pid, &stat, 0) < 0)
{
if(errno != EINTR)
{
return -1;
}
}
return stat;
}
int main()
{
exit(0);
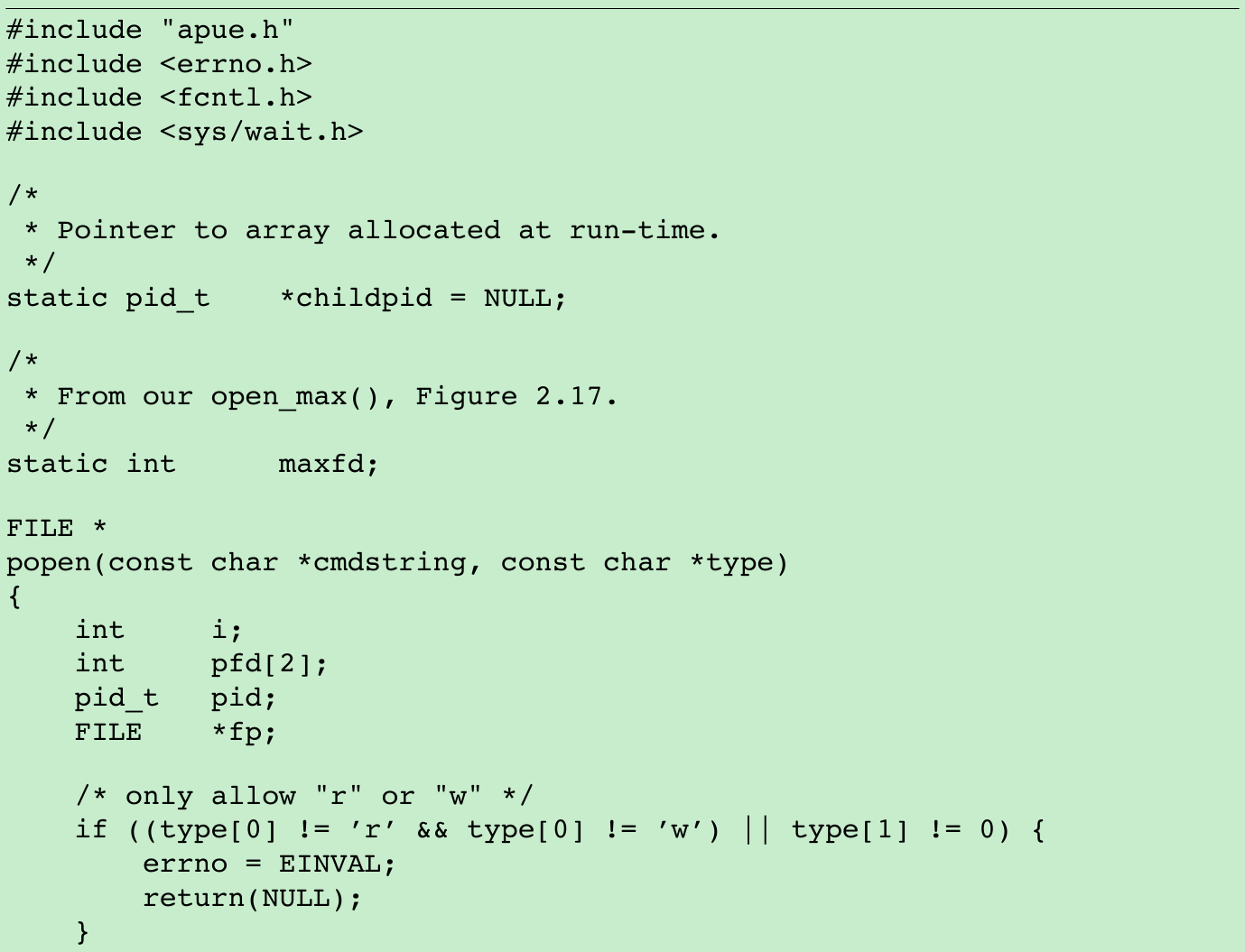
}- Each time popen is called, we have to remember the process ID of the child that we create and either its file descriptor or FILE pointer. We choose to save the child’s process ID in the array childpid, which we index by the file descriptor. In this way, when pclose is called with the FILE pointer as its argument, we call the standard I/O function fileno to get the file descriptor and then have the child process ID for the call to waitpid. Since it’s possible for a given process to call popen more than once, we dynamically allocate the childpid array(the first time popen is called), with room for as many children as there are file descriptors.
- Note that open_max function from Figure 2.17 can return a guess of the maximum number of open files if this value is indeterminate for the system. We need to be careful not to use a pipe file descriptor whose value is larger than(or equal to) what the open_max function returns.
In popen, if the value returned by open_max happens to be too small, we close the pipe file descriptors, set errno to EMFILE to indicate too many file descriptors are open, and return -1.
In pclose, if the file descriptor corresponding to the file pointer argument is larger than expected, we set errno to EINVAL and return -1. - POSIX.1 requires that popen close any streams that are still open in the child from previous calls to popen. To do this, we go through the childpid array in the child, closing any descriptors that are still open.
- What happens if the caller of pclose has established a signal handler for SIGCHLD? The call to waitpid from pclose would return an error of EINTR. Since the caller is allowed to catch this signal(or any other signal that might interrupt the call to waitpid), we simply call waitpid again if it is interrupted by a caught signal.
- If the application calls waitpid and obtains the exit status of the child created by popen, we will call waitpid when the application calls pclose, find that the child no longer exists, and return -1 with errno set to ECHILD. This is the behavior required by POSIX.1 in this situation.
- popen should never be called by a set-user-ID or set-group-ID program. When it executes the command, popen does the equivalent of
execl("/bin/sh", "sh", "-c", command, NULL);
which executes the shell and command with the environment inherited by the caller. A malicious user can manipulate the environment so that the shell executes commands other than those intended, with the elevated permissions granted by the set-ID file mode. - One thing that popen is suited for is executing filters to transform the input or output of the running command. Consider an application that writes a prompt to standard output and reads a line from standard input. With popen, we can interpose a program between the application and its input to transform the input. Figure 15.13 shows the arrangement of processes in this situation.
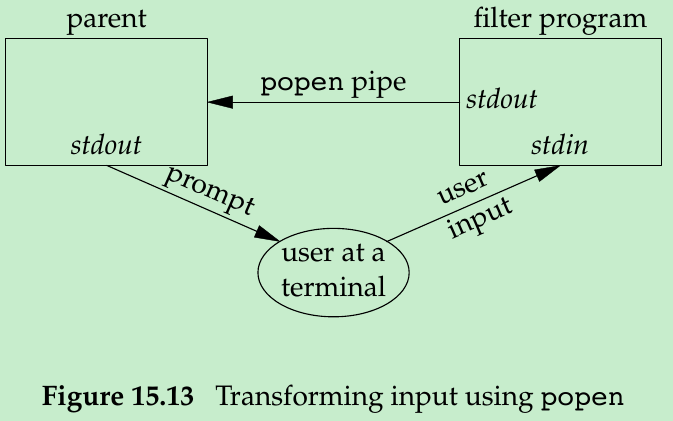
- Figure 15.14 shows a filter to demonstrate this operation. The filter copies standard input to standard output, converting any uppercase character to lowercase. The reason for fflush standard output after writing a newline is discussed in next section.

#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
char ch;
while((ch = getchar()) != EOF)
{
if(isupper(ch))
{
ch = tolower(ch);
}
if(putchar(ch) == EOF)
{
Exit("output error");
}
if(ch == '\n')
{
fflush(stdout);
}
}
exit(0);
}- We compile this filter into the executable file filter, which we then invoke from the program in Figure 15.15 using popen.

#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#define MAX 100
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
char line[MAX];
FILE *fpin;
if((fpin = popen("/home/xiang/Gao/Notes/OS/APUE/Codes/filter", "r")) == NULL)
{
Exit("popen error");
}
for(;;)
{
fputs("$ ", stdout);
fflush(stdout);
if(fgets(line, MAX, fpin) == NULL)
{
break;
}
if(fputs(line, stdout) == EOF)
{
Exit("fputs error to pipe");
}
}
if(pclose(fpin) == -1)
{
Exit("pclose error");
}
putchar('\n');
exit(0);
}- We need to call fflush after writing the prompt, because the standard output is normally line buffered, and the prompt does not contain a newline.
15.4 Coprocesses
- A UNIX system filter is a program that reads from standard input and writes to standard output. A filter becomes a coprocess when the same program generates the filter’s input and reads the filter’s output.
- A coprocess normally runs in the background from a shell, and its standard input and standard output are connected to another program using a pipe.
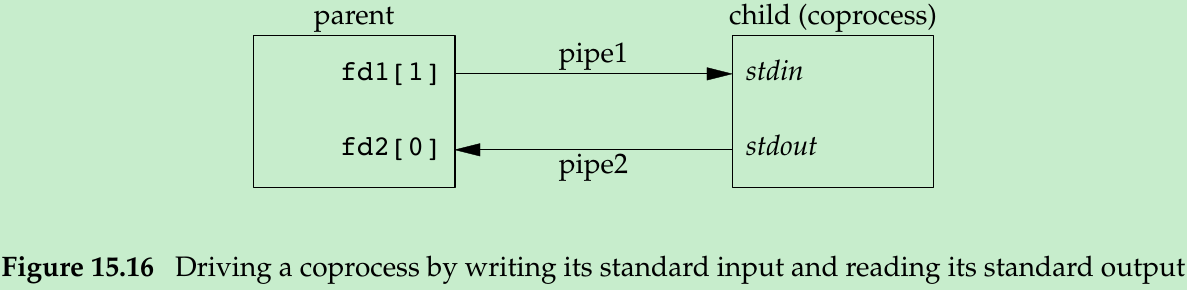
- popen gives us a one-way pipe to the standard input or from the standard output of another process, with a coprocess we have two one-way pipes to the other process: one to its standard input and one from its standard output. We want to write to its standard input, let it operate on the data, and then read from its standard output.
- Figure 15.16. The process creates two pipes: one is the standard input of the coprocess and the other is the standard output of the coprocess.
- The program in Figure 15.17 is a coprocess that reads two numbers from its standard input, computes their sum, and writes the sum to its standard output.

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#define MAX 100
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
int nread, num1, num2;
char line[MAX];
while((nread = read(STDIN_FILENO, line, MAX)) > 0)
{
line[nread] = 0;
if(sscanf(line, "%d%d", &num1, &num2) == 2)
{
sprintf(line, "%d\n", num1 + num2);
int length = strlen(line);
if(write(STDOUT_FILENO, line, length) != length)
{
Exit("write error");
}
}
else
{
if(write(STDOUT_FILENO, "invalid args\n", 13) != 13)
{
Exit("write error");
}
}
}
exit(0);
}- We compile this program to the executable file add2. The program in Figure 15.18 invokes the add2 coprocess after reading two numbers from its standard input. The value from the coprocess is written to its standard output.



#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <string.h>
#define MAX 1000
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
static void sig_pipe(int signo)
{
printf("Catch SIGPIPE signal\n");
exit(1);
}
int main()
{
int nread, fd1[2], fd2[2];
pid_t pid;
char line[MAX];
if(signal(SIGPIPE, sig_pipe) == SIG_ERR)
{
Exit("signal error");
}
if(pipe(fd1) < 0 || pipe(fd2) < 0)
{
Exit("pipe error");
}
if((pid = fork()) < 0)
{
Exit("foek error");
}
else if(pid > 0)
{
close(fd1[0]);
close(fd2[1]);
while(fgets(line, MAX, stdin) != NULL)
{
nread = strlen(line);
if(write(fd1[1], line, nread) != nread)
{
Exit("write error to pipe");
}
if((nread = read(fd2[0], line, MAX)) < 0)
{
Exit("read error form pipe");
}
if(nread == 0)
{
printf("child closed pipe\n");
break;
}
line[nread] = 0;
if(fputs(line, stdout) == EOF)
{
Exit("fputs error");
}
}
if(ferror(stdin))
{
Exit("fgets error on stdin");
}
exit(0);
}
else
{
close(fd1[1]);
close(fd2[0]);
if(fd1[0] != STDIN_FILENO)
{
if(dup2(fd1[0], STDIN_FILENO) != STDIN_FILENO)
{
Exit("dup2 error to stdin");
}
close(fd1[0]);
}
if(fd2[1] != STDOUT_FILENO)
{
if(dup2(fd2[1], STDOUT_FILENO) != STDOUT_FILENO)
{
Exit("dup2 error to stdout");
}
close(fd2[1]);
}
if(execl("./add2", "add2",(char *)0) < 0)
{
Exit("execl error");
}
}
exit(0);
}- We create two pipes, with the parent and the child closing the ends they don’t need. We use two pipes: one for the standard input of the coprocess and one for its standard output. The child then calls dup2 to move the pipe descriptors onto its standard input and standard output, before calling execl.
- If we kill the add2 coprocess while the program in Figure 15.18 is waiting for our input and then enter two numbers, the signal handler is invoked when the program writes to the pipe that has no reader.(Exercise 15.4.)
- In the coprocess add2(Figure 15.17), we use UNIX I/O system calls: read and write. Figure 15.19 use standard I/O.

- If we invoke this new coprocess from the program in Figure 15.18, it no longer works. The problem is the default standard I/O buffering. When the program in Figure 15.19 is invoked, the first fgets on the standard input causes the standard I/O library to allocate a buffer and choose the type of buffering. Since the standard input is a pipe, the standard I/O library defaults to fully buffered. The same thing happens with the standard output. While add2 is blocked reading from its standard input, the program in Figure 15.18 is blocked reading from the pipe. We have a deadlock.
- We can change the program in Figure 15.19 by adding the following four lines before the while loop. These lines cause fgets to return when a line is available and cause printf to do an fflush when a newline is output(Section 5.4).
if(setvbuf(stdin, NULL, _IOLBF, 0) != 0)
err_sys("setvbuf error");
if(setvbuf(stdout, NULL, _IOLBF, 0) != 0)
err_sys("setvbuf error");- If we aren’t able to modify the program that we’re piping the output into, other techniques are required. E.g., if we use awk(1) as a coprocess from our program, the following won’t work:
#! /bin/awk -f
{ print $1 + $2 }- The reason this won’t work is the standard I/O buffering, but we cannot modify the executable of awk in any way to change the way the standard I/O buffering is handled.
- The solution is to make the coprocess being invoked(awk in this case) think that its standard input and standard output are connected to a terminal. That causes the standard I/O routines in the coprocess to line buffer these two I/O streams, similar to what we did with the explicit calls to setvbuf previously.
15.5 FIFOs
- FIFOs are also called named pipes. Unnamed pipes can be used only between related processes when a common ancestor has created the pipe. With FIFOs, unrelated processes can exchange data.
- Chapter 4: A FIFO is a type of file. One of the encodings of the st_mode member of the stat structure(Section 4.2) indicates that a file is a FIFO. We can test for this with the S_ISFIFO macro.
#include <sys/stat.h>
int mkfifo(const char *path, mode_t mode);
int mkfifoat(int fd, const char *path, mode_t mode);
Both return: 0 if OK, −1 on error- The pathname for a FIFO exists in the file system.
- The specification of the mode argument is the same as for the open function(Section 3.3).
- The rules for the user and group ownership of the new FIFO are the same as in Section 4.6.
- The mkfifoat function can be used to create a FIFO in a location relative to the directory represented by the fd file descriptor argument. There are three cases:
- path is absolute: fd is ignored and mkfifoat behaves like mkfifo.
- path is relative and fd is a valid file descriptor for an open directory: the pathname is evaluated relative to this directory.
- path is relative and fd = AT_FDCWD: the pathname is evaluated starting in the current working directory.
- After we use mkfifo/mkfifoat to create a FIFO, we use normal file I/O functions(open, close, read, write, unlink) to work with FIFOs.
- Linux support the mkfifo(1) command and we can create a FIFO using a shell command and then access it with the normal shell I/O redirection. When we open a FIFO, the nonblocking flag(O_NONBLOCK) affects what happens.
- Without O_NONBLOCK: an open for read-only blocks until some other process opens the FIFO for writing; an open for write-only blocks until some other process opens the FIFO for reading.
- With O_NONBLOCK: an open for read-only returns immediately; an open for write-only returns -1 with errno = ENXIO if no process has the FIFO open for reading.
- As with pipes, if we write to a FIFO that no process has open for reading, the SIGPIPE signal is generated. When the last writer for a FIFO closes the FIFO, an end of file is generated for the reader of the FIFO.
- It is common to have multiple writers for a given FIFO and we must concern atomic writes if we don’t want the writes from multiple processes to be interleaved. As with pipes, the constant PIPE_BUF specifies the maximum amount of data that can be written atomically to a FIFO.
- Two uses for FIFOs.
- Used by shell commands to pass data from one shell pipeline to another without creating intermediate temporary files.
- Used as rendezvous points in client-server applications to pass data between the clients and the servers.
Using FIFOs to Duplicate Output Streams
- FIFOs can be used to duplicate an output stream in a series of shell commands. This prevents writing the data to an intermediate disk file, like using pipes to avoid intermediate disk files. But pipes can be used only for linear connections between processes, a FIFO has a name and it can be used for nonlinear connections.
- Consider a procedure that needs to process a filtered input stream twice.
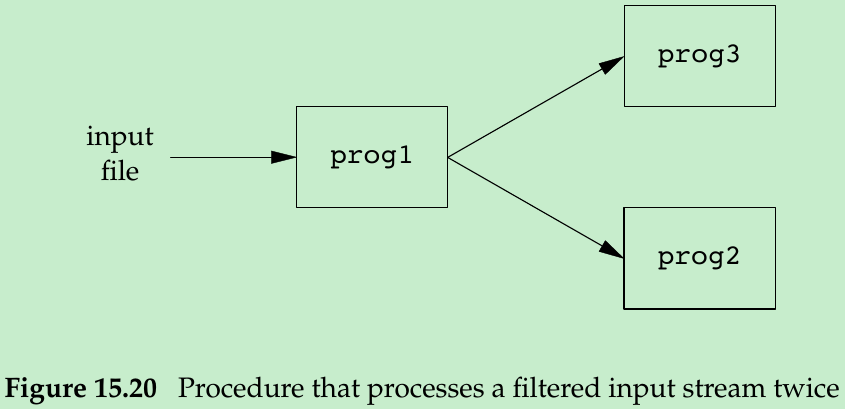
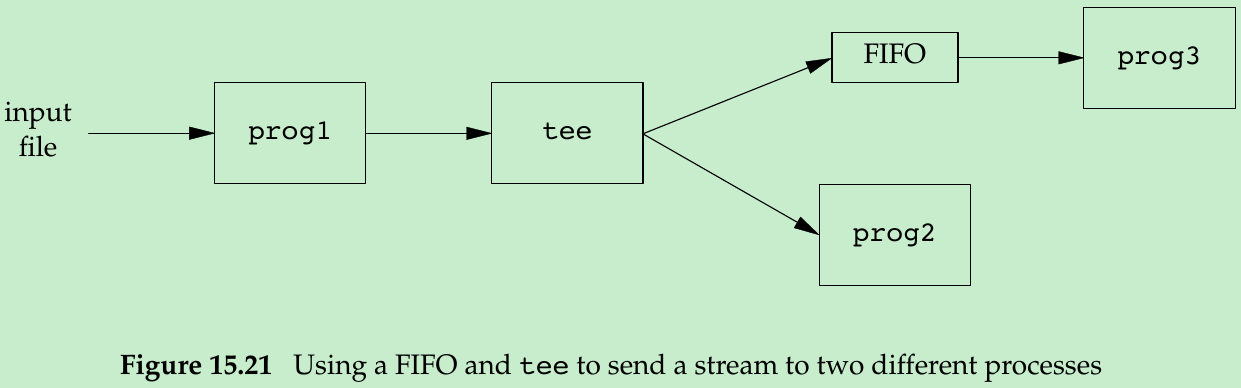
- With a FIFO and the UNIX program tee(1), we can accomplish this procedure without using a temporary file. The tee program copies its standard input to both its standard output and the file named on its command line.
mkfifo fifo1
prog3 < fifo1 &
prog1 < infile | tee fifo1 | prog2- We create the FIFO and then start prog3 in the background, reading from the FIFO. We then start prog1 and use tee to send its input to both the FIFO and prog2. Figure 15.21 shows the process arrangement.
Client-Server Communication Using a FIFO
- Another use for FIFOs is to send data between a client and a server. If we have a server that is contacted by many clients, each client can write its request to a well-known FIFO(the pathname of the FIFO is known to all clients) that the server creates. Figure 15.22 shows this arrangement.
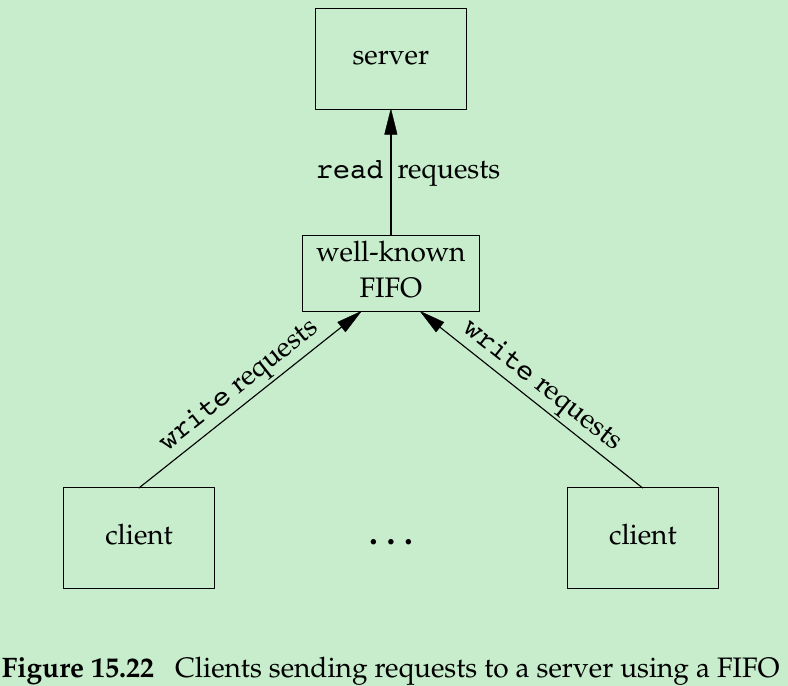
- Since there are multiple writers for the FIFO, the requests sent by the clients to the server need to be less than PIPE_BUF bytes in size. This prevents any interleaving of the client writes.
- Problem is how to send replies back from the server to each client. A single FIFO can’t be used, as the clients would never know when to read their response versus responses for other clients. Solution is for each client to send its process ID with the request. The server then creates a unique FIFO for each client, using a pathname based on the client’s process ID, shown in Figure 15.23.
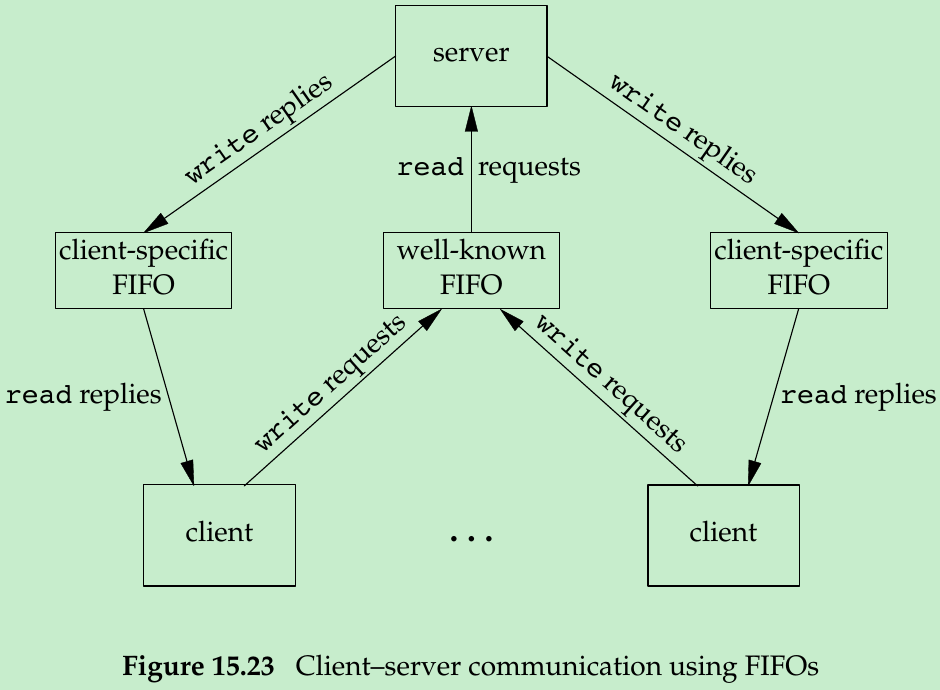
- This arrangement works, but the server can’t tell whether a client crashes. The server must catch SIGPIPE, since it’s possible for a client to send a request and terminate before reading the response, leaving the client-specific FIFO with one writer(the server) and no reader.
- Figure 15.23: If the server opens its well-known FIFO read-only(since it only reads from it) each time the number of clients goes from 1 to 0, the server will read an end of file on the FIFO. To prevent the server from handling this case, a trick is to have the server open its well-known FIFO for read-write(Exercise 15.10.)
15.6 XSI IPC
15.6.1 Identifiers and Keys
- Each IPC structure(message queue, semaphore, or shared memory segment) in the kernel is referred to by a non-negative integer identifier. To send a message to or fetch a message from IPC structure, all we need know is its identifier. When a given IPC structure is created and then removed, the identifier associated with that structure continually increases until it reaches the maximum positive value for an integer, and then wraps around to 0.
- The identifier is an internal name for an IPC object. Cooperating processes need an external name to be able to rendezvous using the same IPC object. So, an IPC object is associated with a key that acts as an external name.
- Whenever an IPC structure is being created, a key of type key_t(a long integer in
#include <sys/ipc.h>
key_t ftok(const char *path, int id);
Returns: key if OK,(key_t)-1 on error- path must refer to an existing file.
Only the lower 8 bits of id are used. - The key created by ftok is formed by taking parts of the st_dev and st_ino fields in the stat structure(Section 4.2) corresponding to the given pathname and combining them with the project ID. If two pathnames refer to two different files, then ftok usually returns two different keys for the two pathnames. But both i-node numbers and keys are stored in long integers, information loss can occur when creating a key, so, two different pathnames can generate the same key if the same project ID is used.
- The three get functions(msgget, semget, and shmget) all have two similar arguments: a key and an integer flag. A new IPC structure is created if key is IPC_PRIVATE or key is not currently associated with an IPC structure of the particular type and the IPC_CREAT bit of flag is specified.
- To reference an existing queue, key must equal the key that was specified when the queue was created, and IPC_CREAT must not be specified. It’s impossible to specify IPC_PRIVATE to reference an existing queue since this key value creates a new queue. To reference an existing queue that was created with a key of IPC_PRIVATE, we must know the associated identifier and then use that identifier in the other IPC calls, bypassing the get function.
- If we want to create a new IPC structure, making sure that we don’t reference an existing one with the same identifier, we must specify a flag with both IPC_CREAT and IPC_EXCL bits set. Doing this causes an error return of EEXIST if the IPC structure already exists.
15.6.2 Permission Structure
- Each IPC structure associates with an ipc_perm structure that defines the permissions and owner and includes at least the following members:
struct ipc_perm
{
uid_t uid; /* owner’s effective user ID */
gid_t gid; /* owner’s effective group ID */
uid_t cuid; /* creator’s effective user ID */
gid_t cgid; /* creator’s effective group ID */
mode_t mode; /* access modes */
...
};- All the fields are initialized when the IPC structure is created. We can modify the uid, gid, and mode fields by calling msgctl, semctl, or shmctl later. To change these values, the calling process must be either the creator of the IPC structure or the superuser.
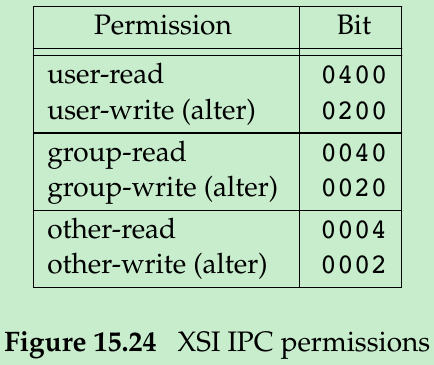
- There is no execute permission for any of the IPC structures. Message queues and shared memory use the terms read and write, but semaphores use the terms read and alter. Figure 15.24:
15.6.3 Configuration Limits
- You can display the IPC-related limits by running ipcs -l.
$ ipcs -l
------Shared Memory Limits --------
max number of segments = 4096
max seg size(kbytes) = 18014398509465599
max total shared memory(kbytes) = 18446744073642442748
min seg size(bytes) = 1
------Semaphore Limits --------
max number of arrays = 128
max semaphores per array = 250
max semaphores system wide = 32000
max ops per semop call = 32
semaphore max value = 32767
------Messages Limits --------
max queues system wide = 15825
max size of message(bytes) = 8192
default max size of queue(bytes) = 1638415.6.4 Advantages and Disadvantages
- First problem: The IPC structures are system-wide and do not have a reference count. E.g., if we create a message queue, place some messages on the queue, and then terminate, the message queue and its contents are not deleted. They remain in the system until specifically read or deleted by msgrcv() or msgctl(), by executing the ipcrm(1) command, or by the system being rebooted.
Pipe is completely removed when the last process to reference it terminates. For FIFO, though the name stays in the file system until explicitly removed, any data left in a FIFO is removed when the last process to reference the FIFO terminates. - Second problem: These IPC structures are not known by names in the file system and we can’t access them or modify their properties with the functions in Ch 3 and 4. Because these IPC don’t use file descriptors, we can’t use the multiplexed I/O functions(select and poll) with them which makes it harder to use more than one of these IPC structures at a time or to use any of these IPC structures with file or device I/O. E.g., we can’t have a server wait for a message to be placed on one of two message queues without some form of busy-wait loop.
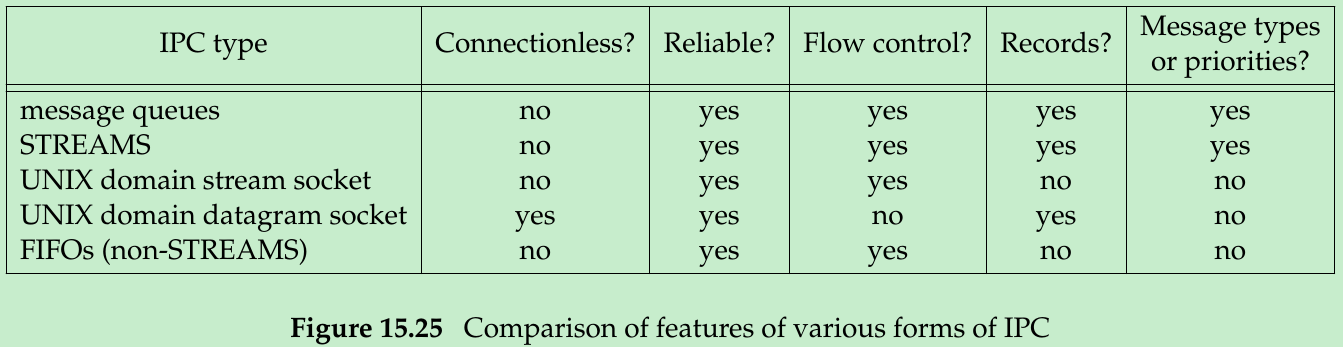
- Figure 15.25:
- “Connectionless” means the ability to send a message without calling some form of open function first.
- Since all these forms of IPC are restricted to a single host, all are reliable.
- “Flow control” means that the sender is put to sleep if there is a shortage of system resources(buffers) or if the receiver can’t accept any more messages. When the flow control condition subsides(i.e., when there is room in the queue), the sender should automatically be awakened.
15.7 Message Queues
- A message queue is a linked list of messages stored within the kernel and identified by a message queue identifier(queue ID).
- Each queue has the following msqid_ds structure associated with it:
struct msqid_ds
{
struct ipc_perm msg_perm; /* Section 15.6.2 */
msgqnum_t msg_qnum; /* # of messages on queue */
msglen_t msg_qbytes; /* max # of bytes on queue */
pid_t msg_lspid; /* pid of last msgsnd() */
pid_t msg_lrpid; /* pid of last msgrcv() */
time_t msg_stime; /* last-msgsnd() time */
time_t msg_rtime; /* last-msgrcv() time */
time_t msg_ctime; /* last-change time */
...
};- This structure defines the current status of the queue. systems include additional fields not covered by the standard.
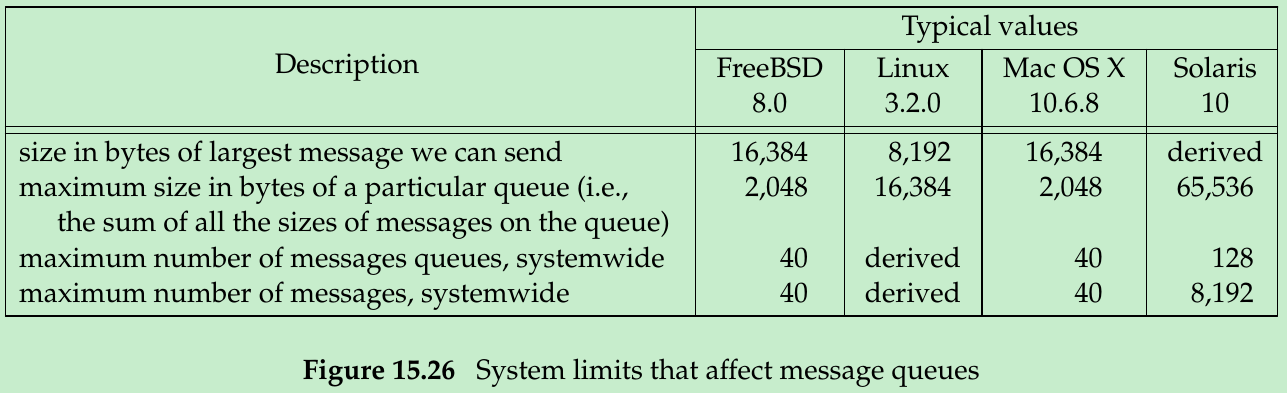
- Figure 15.26 lists the system limits that affect message queues. “derived” means a limit is derived from other limits. E.g., the maximum number of messages is based on the maximum number of queues and the maximum amount of data allowed on the queues. The maximum number of queues is based on the amount of RAM installed in the system. The queue maximum byte size limit further limits the maximum size of a message to be placed on a queue.
-
- New messages are added to the end of a queue by msgsnd. Every message has a positive long integer type field, a non-negative length, and the actual data bytes, all of them are specified to msgsnd when the message is added to a queue.
- We can fetch messages based on type field from a queue by msgrcv.
#include <sys/msg.h>
int msgget(key_t key, int flag);
Returns: message queue ID if OK, -1 on error- msgget: create a new queue or open an existing queue.
- When a new queue is created, the following members of the msqid_ds structure are initialized.
• ipc_perm is initialized as described in Section 15.6.2. The mode member of this structure is set to the corresponding permission bits of flag. These permissions are specified with the values from Figure 15.24.
• msg_qnum, msg_lspid, msg_lrpid, msg_stime, and msg_rtime are all set to 0.
• msg_ctime is set to the current time.
• msg_qbytes is set to the system limit. - On success, msgget returns the non-negative queue ID that is used with the other three message queue functions.
#include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
Returns: 0 if OK, -1 on error- msgctl() and related functions for semaphores and shared memory(semctl and shmctl) are the ioctl-like functions for XSI IPC(i.e., the garbage-can functions).
- cmd specifies the command to be performed on the queue specified by msqid.
- IPC_STAT
Fetch the msqid_ds structure for this queue and store it in the structure pointed to by buf. - IPC_SET
Copy the following fields from the structure pointed to by buf to the msqid_ds structure associated with this queue: msg_perm.uid, msg_perm.gid, msg_perm.mode, and msg_qbytes.
This command can be executed only by a process whose effective user ID equals msg_perm.cuid or msg_perm.uid or by a process with superuser privileges. Only the superuser can increase the value of msg_qbytes. - IPC_RMID
Remove the message queue from the system and any data on the queue immediately. Any other process still using the message queue will get an error of EIDRM on its next attempted operation on the queue.
This command can be executed only by a process whose effective user ID equals msg_perm.cuid or msg_perm.uid or by a process with superuser privileges.
- IPC_STAT
#include <sys/msg.h>
int msgsnd(int msqid, const void *ptr, size_t nbytes, int flag);
Returns: 0 if OK, -1 on error- msgsnd: place data onto a message queue. Each message is composed of a positive long integer type field, a non-negative length(nbytes), and the data bytes(corresponding to the length). Messages are always placed at the end of the queue.
- ptr points to a long integer that contains the positive integer message type, and it is immediately followed by the message data. There is no message data if nbytes is 0. If the largest message we send is 512 bytes, we can define the following structure: ptr is a pointer to a my_message structure. The message type can be used by the receiver to fetch messages in an order other than first in, first out.
struct my_message
{
long type; /* positive message type */
char text[512]; /* message data of length nbytes */
};- flag: If the message queue is full,
flag = IPC_NOWAITcauses msgsnd to return immediately with an error of EAGAIN; otherwise, we are blocked until there is room for the message, the queue is removed from the system(return error of EIDRM(identifier removed)), or a signal is caught and the signal handler returns(return error of EINTR). - Since a reference count is not maintained with each message queue, the removal of a queue generates errors on the next queue operation by processes still using the queue. Semaphores handle this removal in the same fashion. In contrast, when a file is removed, the file’s contents are not deleted until the last open descriptor for the file is closed.
- When msgsnd returns successfully, the msqid_ds structure associated with the message queue is updated to indicate the process ID that made the call(msg_lspid), the time that the call was made(msg_stime), and one more message is on the queue(msg_qnum).
#include <sys/msg.h>
ssize_t msgrcv(int msqid, void *ptr, size_t nbytes, long type, int flag);
Returns: size of data portion of message if OK, -1 on error- msgrcv: retrieve messages from a queue.
- ptr points to a long integer(where the message type of the returned message is stored) followed by a data buffer for the actual message data.
- nbytes is the size of the data buffer. When the returned message is larger than nbytes and if the MSG_NOERROR bit in flag is
- set: the message is truncated without any notification given to us.
- not set: an error of E2BIG is returned and the message stays on the queue.
- type specifies which message we want.
- = 0: The first message on the queue is returned.
- > 0: The first message on the queue whose message type equals type is returned.
- < 0: The first message on the queue whose message type is the lowest value less than or equal to the absolute value of type is returned.
- A nonzero type is used to read the messages in an order other than FIFO. E.g., type could be a priority value if the application assigns priorities to the messages.
Another use of type is to contain the process ID of the client if a single message queue is being used by multiple clients and a single server(if a process ID fits in a long integer). - When a message of the specified type is not available, flag
- = IPC_NOWAIT: msgrcv return -1 with errno set to ENOMSG.
- != IPC_NOWAIT: the operation blocks until a message of the specified type is available, the queue is removed from the system(return -1 with errno set to EIDRM), or a signal is caught and the signal handler returns(return -1 with errno set to EINTR).
- When msgrcv succeeds, the kernel updates the msqid_ds structure associated with the message queue to indicate the caller’s process ID(msg_lrpid), the time of the call(msg_rtime), and that one less message is on the queue(msg_qnum).
Example-Timing Comparison of Message Queues and Full-Duplex Pipes
- If we need a bidirectional flow of data between a client and a server, we can use message queues or full-duplex pipes(available through the UNIX domain sockets mechanism(Section 17.2)).
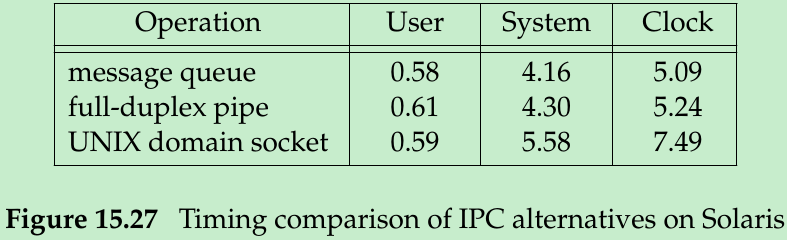
- Figure 15.27 shows a timing comparison of message queues, full-duplex(STREAMS) pipes, and UNIX domain sockets on Solaris. The tests consisted of a program that created the IPC channel, called fork, and then sent about 200 megabytes of data from the parent to the child. The data was sent using 100,000 calls to msgsnd, with a message length of 2,000 bytes for the message queue, and 100,000 calls to write, with a length of 2,000 bytes for the full-duplex pipe and UNIX domain socket. The times are all in seconds.
- Message queues are not much faster than other forms of IPC. When we consider the problems in using message queues(Section 15.6.4), we shouldn’t use them for new applications.
15.8 Semaphores
- A semaphore is a counter used to provide access to a shared data object for multiple processes.
- To obtain a shared resource, a process needs to do the following:
- Test the semaphore that controls the resource.
- If the value of the semaphore is positive, the process can use the resource. The process decrements the semaphore value by 1, indicating that it has used one unit of the resource. When the process is done with the resource, the semaphore value is incremented by 1. If any other processes are asleep waiting for the semaphore, they are awakened.
- Otherwise, if the value of semaphore is 0, the process goes to sleep until the semaphore value is greater than 0. When the process wakes up, it returns to step 1.
- To implement semaphores correctly, the test of a semaphore’s value and the decrementing of this value must be an atomic operation. So, semaphores are normally implemented inside the kernel.
- A binary semaphore controls a single resource and its value is initialized to 1. A semaphore can be initialized to any positive value that indicates how many units of the shared resource are available for sharing.
- XSI semaphores are complicate with three features.
- A semaphore is not a single non-negative value, we have to define a semaphore as a set of one or more semaphore values. When we create a semaphore, we specify the number of values in the set.
- The creation of a semaphore(semget) is independent of its initialization(semctl).
- Since all forms of XSI IPC remain in existence even when no process is using them, a program may terminates without releasing the semaphores it has been allocated. The undo feature is supposed to handle this.
- The kernel maintains a semid_ds structure for each semaphore set, systems can define additional members in the semid_ds structure.
struct semid_ds
{
struct ipc_perm sem_perm; /* see Section 15.6.2 */
unsigned short sem_nsems; /* # of semaphores in set */
time_t sem_otime; /* last-semop() time */
time_t sem_ctime; /* last-change time */
...
};- Each semaphore is represented by an anonymous structure containing at least the following members:
struct
{
unsigned short semval; /* semaphore value, always >= 0 */
pid_t sempid; /* pid for last operation */
unsigned short semncnt; /* processes awaiting semval > curval */
unsigned short semzcnt; /* processes awaiting semval == 0 */
...
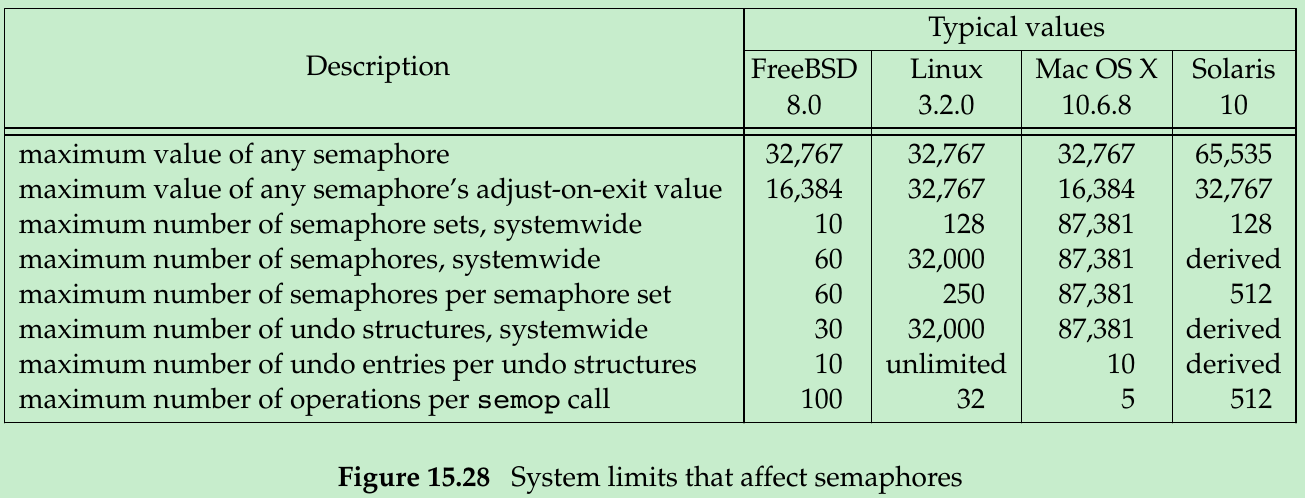
};- Figure 15.28 lists the system limits that affect semaphore sets.
#include <sys/sem.h>
int semget(key_t key, int nsems, int flag);
Returns: semaphore ID if OK, -1 on error- semget: obtain a semaphore ID.
- When a new set is created, the following members of the semid_ds structure are initialized.
• ipc_perm is initialized as described in Section 15.6.2. The mode member of this structure is set to the corresponding permission bits of flag. These permissions are specified with the values from Figure 15.24.
• sem_otime is set to 0.
• sem_ctime is set to the current time.
• sem_nsems is set to nsems. - nsems is the number of semaphores in the set. If a new set is created, we must specify nsems. If we are referencing an existing set, we can specify nsems as 0.
#include <sys/sem.h>
int semctl(int semid, int semnum, int cmd, ... /* union semun arg */);
Returns: (see following)- arg is optional, depending on cmd; if present, it is of type semun which is a union of various command-specific arguments.
union semun
{
int val; /* for SETVAL */
struct semid_ds* buf; /* for IPC_STAT and IPC_SET */
unsigned short* array; /* for GETALL and SETALL */
};- The cmd argument specifies one of the following ten commands to be performed on the set specified by semid. The five commands that refer to one particular semaphore value use semnum to specify one member of the set. The value of semnum is [0, nsems-1].
- IPC_STAT
Fetch the semid_ds structure for this set, storing it in the structure pointed to by arg.buf. - IPC_SET
Set the sem_perm.uid, sem_perm.gid, and sem_perm.mode fields from the structure pointed to by arg.buf in the semid_ds structure associated with this set. This command can be executed only by a process whose effective user ID equals sem_perm.cuid or sem_perm.uid or by a process with superuser privileges. - IPC_RMID
Remove the semaphore set from the system. This removal is immediate. Any other process still using the semaphore will get an error of EIDRM on its next attempted operation on the semaphore. This command can be executed only by a process whose effective user ID equals sem_perm.cuid or sem_perm.uid or by a process with superuser privileges. - GETVAL
Return the value of semval for the member semnum. - SETVAL
Set the value of semval for the member semnum. The value is specified by arg.val. - GETPID
Return the value of sempid for the member semnum. - GETNCNT
Return the value of semncnt for the member semnum. - GETZCNT
Return the value of semzcnt for the member semnum. - GETALL
Fetch all the semaphore values in the set. These values are stored in the array pointed to by arg.array. - SETALL
Set all the semaphore values in the set to the values pointed to by arg.array.
- IPC_STAT
- For all GET commands other than GETALL, the function returns the corresponding value; for the remaining commands, the return value is 0 if the call succeeds. On error, it sets errno and returns -1.
#include <sys/sem.h>
int semop(int semid, struct sembuf semoparray[], size_t nops);
Returns: 0 if OK, -1 on error- semoparray is a pointer to an array of semaphore operations, represented by sembuf structures:
struct sembuf
{
unsigned short sem_num; /* member in set (0, 1, ..., nsems-1) */
short sem_op; /* operation (negative, 0, or positive) */
short sem_flg; /* IPC_NOWAIT, SEM_UNDO */
};- nops specifies the number of operations(elements) in the array.
- The operation on each member of the set is specified by the corresponding sem_op value that can be negative, 0, or positive. Semaphores’ undo flag corresponds to the SEM_UNDO bit in the corresponding sem_flg member.
- sem_op is positive. This case corresponds to the returning of resources by the process. The value of sem_op is added to the semaphore’s value.
If the undo flag is specified, sem_op is also subtracted from the semaphore’s adjustment value for this process. - sem_op is negative, we want to obtain resources that the semaphore controls.
-1-If the semaphore’s value is greater than or equal to the absolute value of sem_op(the resources are available), the absolute value of sem_op is subtracted from the semaphore’s value. This guarantees the resulting semaphore value is greater than or equal to 0. If the undo flag is specified, the absolute value of sem_op is also added to the semaphore’s adjustment value for this process.
-2-If the semaphore’s value is less than the absolute value of sem_op(the resources are not available), the following conditions apply.
a. If IPC_NOWAIT is specified, semop returns with an error of EAGAIN.
b. If IPC_NOWAIT is not specified, the semncnt value for this semaphore is incremented(since the caller is about to go to sleep), and the calling process is suspended until one of the following occurs.
i. The semaphore’s value becomes greater than or equal to the absolute value of sem_op(i.e., some other process has released some resources). The value of semncnt for this semaphore is decremented(since the calling process is done waiting), and the absolute value of sem_op is subtracted from the semaphore’s value. If the undo flag is specified, the absolute value of sem_op is also added to the semaphore’s adjustment value for this process.
ii.The semaphore is removed from the system. In this case, the function returns an error of EIDRM.
iii. A signal is caught by the process, and the signal handler returns. In this case, the value of semncnt for this semaphore is decremented(since the calling process is no longer waiting), and the function returns an error of EINTR. - sem_op is 0, this means that the calling process wants to wait until the semaphore’s value becomes 0.
-1-If the semaphore’s value is currently 0, the function returns immediately.
-2-If the semaphore’s value is nonzero, the following conditions apply.
a. If IPC_NOWAIT is specified, return is made with an error of EAGAIN.
b. If IPC_NOWAIT is not specified, the semzcnt value for this semaphore is incremented(since the caller is about to go to sleep), and the calling process is suspended until one of the following occurs.
i. The semaphore’s value becomes 0. The value of semzcnt for this semaphore is decremented(since the calling process is done waiting).
ii.The semaphore is removed from the system. In this case, the function returns an error of EIDRM.
iii. A signal is caught by the process, and the signal handler returns. In this case, the value of semzcnt for this semaphore is decremented(since the calling process is no longer waiting), and the function returns an error of EINTR.
- sem_op is positive. This case corresponds to the returning of resources by the process. The value of sem_op is added to the semaphore’s value.
- The semop function operates atomically; it does either all the operations in the array or none of them.
Semaphore Adjustment on exit
- As we mentioned earlier, it is a problem if a process terminates while it has resources allocated through a semaphore. Whenever we specify the SEM_UNDO flag for a semaphore operation and we allocate resources(a sem_op value less than 0), the kernel remembers how many resources we allocated from that particular semaphore(the absolute value of sem_op). When the process terminates, either voluntarily or involuntarily, the kernel checks whether the process has any outstanding semaphore adjustments and, if so, applies the adjustment to the corresponding semaphore.
- If we set the value of a semaphore using semctl, with either the SETVAL or SETALL commands, the adjustment value for that semaphore in all processes is set to 0.
Example-Timing Comparison of Semaphores, Record Locking, and Mutexes
- If we are sharing a single resource among multiple processes, we can use one of three techniques to coordinate access. We can use a a semaphore, record locking, or a mutex that is mapped into the address spaces of both processes. It’s interesting to compare the timing differences between the three techniques.
- With a semaphore, we create a semaphore set consisting of a single member and initialize the semaphore’s value to 1. To allocate the resource, we call semop with a sem_op of -1; to release the resource, we perform a sem_op of +1. We also specify SEM_UNDO with each operation, to handle the case of a process that terminates without releasing its resource.
- With record locking, we create an empty file and use the first byte of the file(which need not exist) as the lock byte. To allocate the resource, we obtain a write lock on the byte; to release it, we unlock the byte. The record locking properties guarantee that if a process terminates while holding a lock, the kernel automatically releases the lock.
- To use a mutex, we need both processes to map the same file into their address spaces and initialize a mutex at the same offset in the file using the PTHREAD_PROCESS_SHARED mutex attribute. To allocate the resource, we lock the mutex; to release the resource, we unlock the mutex. If a process terminates without releasing the mutex, recovery is difficult unless we use a robust mutex(recall the pthread_mutex_consistent function discussed in Section 12.4.1).
- Figure 15.29 shows the time required to perform these three locking techniques on Linux. In each case, the resource was allocated and then released 1,000,000 times. This was done simultaneously by three different processes. The times in Figure 15.29 are the totals in seconds for all three processes.
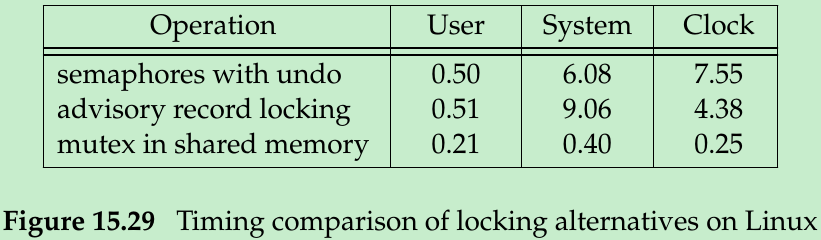
- On Linux, record locking is faster than semaphores, but mutexes in shared memory outperform both semaphores and record locking. If we’re locking a single resource and don’t need all the fancy features of XSI semaphores, record locking is preferred over semaphores. The reasons are that it is much simpler to use, it is faster(on this platform), and the system takes care of any lingering locks when a process terminates.
- Even though using a mutex in shared memory is the fastest option on this platform, we still prefer to use record locking, unless performance is the primary concern. There are two reasons for this. First, recovery from process termination is more difficult using a mutex in memory shared among multiple processes. Second, the process-shared mutex attribute isn’t universally supported yet. In older versions of the Single UNIX Specification, it was optional. Although it is still optional in SUSv4, it is now required by all XSI-conforming implementations.
15.9 Shared Memory
- Shared memory allows two or more processes to share a given region of memory. This is the fastest form of IPC because the data does not need to be copied between client and server.
- We should synchronize access to a given region among multiple processes: if the server is placing data into a shared memory region, the client shouldn’t try to access the data until the server is done. Semaphores, record locking or mutexes are used to synchronize shared memory access.
- The XSI shared memory differs from memory-mapped files in that there is no associated file. The XSI shared memory segments are anonymous segments of memory. The kernel maintains a structure with at least the following members for each shared memory segment.
struct shmid_ds
{
struct ipc_perm shm_perm; /* see Section 15.6.2 */
size_t shm_segsz; /* size of segment in bytes */
pid_t shm_lpid; /* pid of last shmop() */
pid_t shm_cpid; /* pid of creator */
shmatt_t shm_nattch; /* number of current attaches */
time_t shm_atime; /* last-attach time */
time_t shm_dtime; /* last-detach time */
time_t shm_ctime; /* last-change time */
...
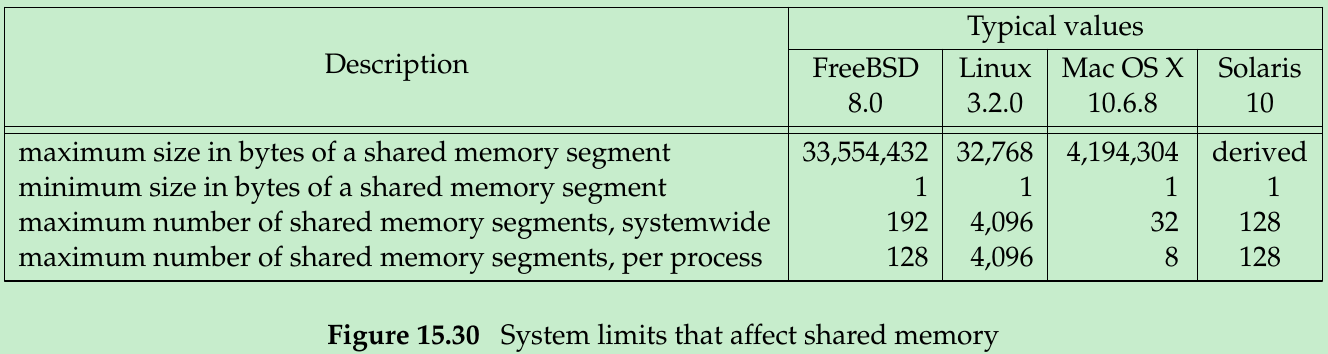
};- The type shmatt_t is defined to be an unsigned integer at least as large as an unsigned short. Figure 15.30 lists the system limits that affect shared memory.
#include <sys/shm.h>
int shmget(key_t key, size_t size, int flag);
Returns: shared memory ID if OK, -1 on error- shmget() obtains a shared memory identifier.
- Section 15.6.1 described the rules for converting the key into an identifier and whether a new segment is created or an existing segment is referenced. When a new segment is created, the following members of the shmid_ds structure are initialized.
• The ipc_perm structure is initialized as described in Section 15.6.2. The mode member of this structure is set to the corresponding permission bits of flag. These permissions are specified with the values from Figure 15.24.
• shm_lpid, shm_nattch, shm_atime, and shm_dtime are all set to 0.
• shm_ctime is set to the current time.
• shm_segsz is set to the size requested. - The size parameter is the size of the shared memory segment in bytes.
- If a new segment is being created, we must specify its size and the contents of the segment are initialized with zeros. Systems usually round up this size to a multiple of the system’s page size, if an application specifies size as a value other than an integral multiple of the system’s page size, the remainder of the last page will be unavailable for use.
- If we are referencing an existing segment, we can specify size as 0.
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf );
Returns: 0 if OK, -1 on error- cmd specifies one of the following five commands to be performed on the segment specified by shmid
- IPC_STAT
Fetch the shmid_ds structure for this segment, storing it in the structure pointed to by buf. - IPC_SET
Set the following three fields from the structure pointed to by buf in the shmid_ds structure associated with this shared memory segment: shm_perm.uid, shm_perm.gid, and shm_perm.mode. This command can be executed only by a process whose effective user ID equals shm_perm.cuid or shm_perm.uid or by a process with superuser privileges. - IPC_RMID
Remove the shared memory segment set from the system. Since an attachment count is maintained for shared memory segments(the shm_nattch field in the shmid_ds structure), the segment is not removed until the last process using the segment terminates or detaches it. Regardless of whether the segment is in use, the segment’s identifier is immediately removed so that shmat can no longer attach the segment. This command can be executed only by a process whose effective user ID equals shm_perm.cuid or shm_perm.uid or by a process with superuser privileges. - SHM_LOCK
Lock the shared memory segment in memory. This command can be executed only by the superuser. - SHM_UNLOCK
Unlock the shared memory segment. This command can be executed only by the superuser.
- IPC_STAT
#include <sys/shm.h>
void *shmat(int shmid, const void *addr, int flag);
Returns: pointer to shared memory segment if OK, -1 on error- shmat: attaches a shared memory segment to calling process’s address space.
- The address in the calling process at which the segment is attached depends on the addr argument and whether the SHM_RND bit is specified in flag. If:
- addr = 0: the segment is attached at the first available address selected by the kernel. This is the recommended technique.
- addr != 0 and SHM_RND is not specified: the segment is attached at the address given by addr.
- addr != 0 and SHM_RND is specified: the segment is attached at the address given by (addr - addr % SHMLBA). SHM_RND stands for “round”. SHMLBA stands for “low boundary address multiple” and is always a power of 2. What the arithmetic does is round the address down to the next multiple of SHMLBA.
- If the SHM_RDONLY bit is specified in flag, the segment is attached as read-only; otherwise, the segment is attached as read-write.
- The value returned by shmat is the address at which the segment is attached, or -1 if an error occurred. If shmat succeeds, the kernel will increment the shm_nattch counter in the shmid_ds structure associated with the shared memory segment.
#include <sys/shm.h>
int shmdt(const void *addr);
Returns: 0 if OK, -1 on error- shmdt: detach a shared memory segment. This does not remove the identifier and its associated data structure from the system. The identifier remains in existence until some process specifically removes it by calling shmctl with a command of IPC_RMID.
- addr is the value that was returned by a previous call to shmat. If successful, shmdt will decrement the shm_nattch counter in the associated shmid_ds structure.
- Figure 15.31 shows a program that prints some information on where system places various types of data.
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/types.h>
#include <sys/shm.h>
#define ARRAY_SIZE 40000
#define MALLOC_SIZE 100000
#define SHM_SIZE 100000
#define SHM_MODE 0600 /* user read&write */
char array[ARRAY_SIZE]; /* uninitialized data = bss */
void Exit(char *string)
{
printf("%s\n", string);
exit(1);
}
int main()
{
int shmid;
char *ptr, *shmptr;
printf("array[] from %p to %p\n", (void *)&array[0],
(void *)&array[ARRAY_SIZE]);
printf("stack around %p\n", (void *)&shmid);
if((ptr = malloc(MALLOC_SIZE)) == NULL)
{
Exit("malloc error");
}
printf("malloced from %p to %p\n", (void *)ptr, (void *)ptr+MALLOC_SIZE);
if((shmid = shmget(IPC_PRIVATE, SHM_SIZE, SHM_MODE)) < 0)
{
Exit("shmget error");
}
if((shmptr = shmat(shmid, 0, 0)) == (void *)-1)
{
Exit("shmat error");
}
printf("shared memory attached from %p to %p\n", (void *)shmptr,
(void *)shmptr+SHM_SIZE);
if (shmctl(shmid, IPC_RMID, 0) < 0)
{
Exit("shmctl error");
}
exit(0);
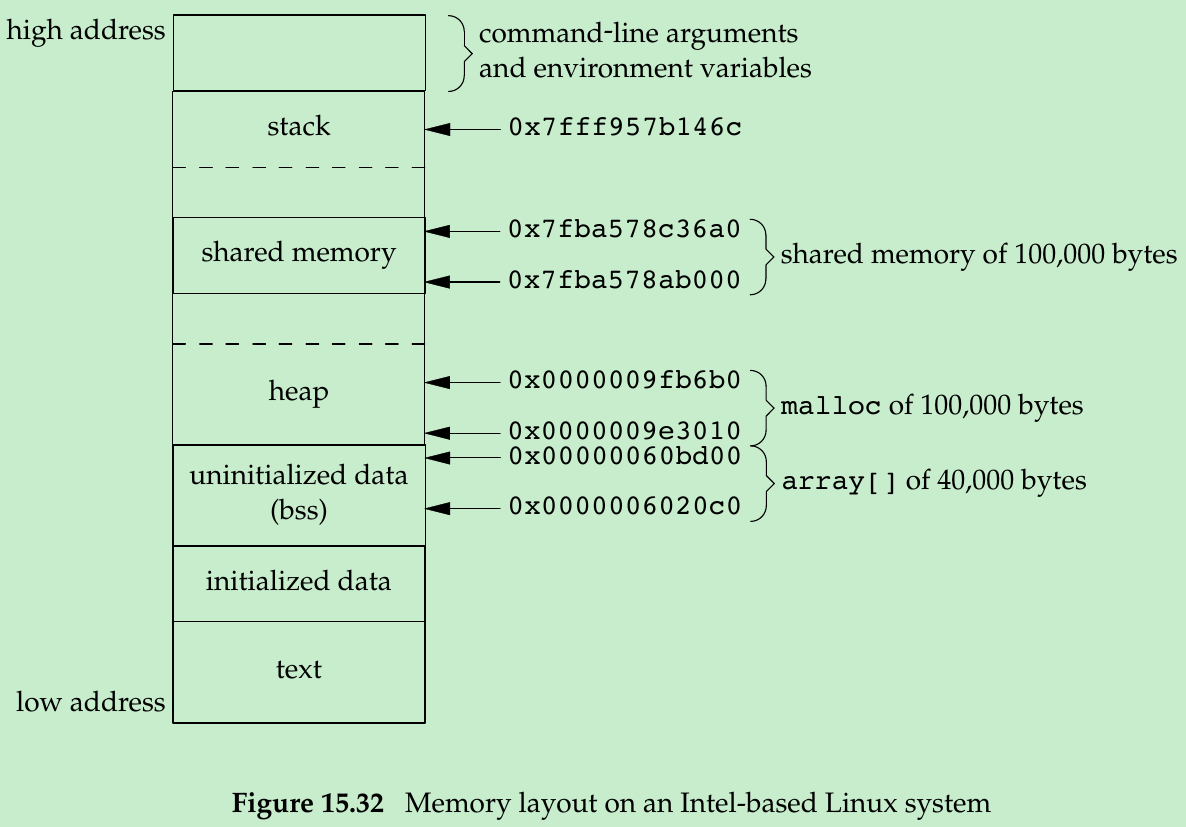
}$ ./a.out
array[] from 0x6020c0 to 0x60bd00
stack around 0x7fff957b146c
malloc from 0x9e3010 to 0x9fb6b0
shared memory attached from 0x7fba578ab000 to 0x7fba578c36a0- Figure 15.32 shows a picture of this, the shared memory segment is placed below the stack.
- The mmap function(Section 14.8) can be used to map portions of a file into the address space of a process. Difference with shmat() is that the memory segment mapped with mmap is backed by a file, whereas no file is associated with a shared memory segment.
Example-Memory Mapping of /dev/zero
- Shared memory can be used between unrelated processes; if the processes are related, some systems provide a different technique. Linux support the mapping of character devices into the address space of a process.
- The device /dev/zero is an infinite source of 0 bytes when read, it accepts and ignores any data that is written to it. When it is memory mapped:
- An unnamed memory region is created whose size is the second argument to mmap, rounded up to the nearest page size on the system.
- The memory region is initialized to 0.
- Multiple processes can share this region if a common ancestor specifies the MAP_SHARED flag to mmap.

- The program opens the /dev/zero device and calls mmap with a size of a long integer. Once the region is mapped, we can close the device. The process then creates a child. Since MAP_SHARED was specified in the call to mmap, writes to the memory-mapped region by one process are seen by the other process. If we specified MAP_PRIVATE instead, this example wouldn’t work.
- The parent and the child then alternate running, incrementing a long integer in the shared memory-mapped region, using the synchronization functions from Section 8.9. The memory-mapped region is initialized to 0 by mmap. The parent increments it to 1, then the child increments it to 2, then the parent increments it to 3, and so on.
- Advantage of using /dev/zero in this manner: An actual file need not exist before we call mmap to create the mapped region. Mapping /dev/zero automatically creates a mapped region of the specified size.
Disadvantage: It works only between related processes. With related processes, it is simpler and more efficient to use threads. No matter which technique is used, we still need to synchronize access to the shared data.
Example-Anonymous Memory Mapping
- Linux provide anonymous memory mapping(similar to the /dev/zero feature). To use it, we specify the MAP_ANON or MAP_ANONYMOUS flag to mmap and specify the file descriptor as -1. The resulting region is anonymous(since it’s not associated with a pathname through a file descriptor) and creates a memory region that can be shared with descendant processes.
- We make 3 changes in Figure 15.33 to use this facility:
(a) remove the open of /dev/zero,
(b) remove the close of fd, and
(c) change the call to mmap to the following:
if((area = mmap(0, SIZE, PROT_READ | PROT_WRITE, MAP_ANON | MAP_SHARED, -1, 0)) == MAP_FAILED)15.10 POSIX Semaphores
- The POSIX semaphore interfaces were meant to address several deficiencies with the XSI semaphore interfaces:
• The POSIX semaphore interfaces allow for higher-performance systems compared to XSI semaphores.
• The POSIX semaphore interfaces are simpler to use: there are no semaphore sets, and several of the interfaces are patterned after familiar file system operations. Although there is no requirement that they be implemented in the file system, some systems do take this approach.
• The POSIX semaphores behave more gracefully when removed. Recall that when an XSI semaphore is removed, operations using the same semaphore identifier fail with errno set to EIDRM. With POSIX semaphores, operations continue to work normally until the last reference to the semaphore is released. - POSIX semaphores are available in two flavors: named and unnamed. They differ in how they are created and destroyed, but otherwise work the same. Unnamed semaphores exist in memory only and require that processes have access to the memory to be able to use the semaphores. This means they can be used only by threads in the same process or threads in different processes that have mapped the same memory extent into their address spaces. Named semaphores, in contrast, are accessed by name and can be used by threads in any processes that know their names.
- To create a new named semaphore or use an existing one, we call the sem_open function.
#include <semaphore.h>
sem_t *sem_open(const char *name, int oflag, ... /* mode_t mode, unsigned int value */ );
Returns: Pointer to semaphore if OK, SEM_FAILED on error- When using an existing named semaphore, we specify only two arguments: the name of the semaphore and a zero value for the oflag argument. When the oflag argument has the O_CREAT flag set, we create a new named semaphore if it does not yet exist. If it already exists, it is opened for use, but no additional initialization takes place.
- When we specify the O_CREAT flag, we need to provide two additional arguments. The mode argument specifies who can access the semaphore. It can take on the same values as the permission bits for opening a file: user-read, user-write, user-execute, group-read, group-write, group-execute, other-read, other-write, and other-execute.
- The resulting permissions assigned to the semaphore are modified by the caller’s file creation mask(Sections 4.5 and 4.8). Note, however, that only read and write access matter, but the interfaces don’t allow us to specify the mode when we open an existing semaphore. systems usually open semaphores for both reading and writing.
- The value argument is used to specify the initial value for the semaphore when we create it. It can take on any value from 0 to SEM_VALUE_MAX(Figure 2.9).
- If we want to ensure that we are creating the semaphore, we can set the oflag argument to O_CREAT|O_EXCL. This will cause sem_open to fail if the semaphore already exists.
- To promote portability, we must follow certain conventions when selecting a semaphore name.
• The first character in the name should be a slash(/). Although there is no requirement that an implementation of POSIX semaphores uses the file system, if the file system is used, we want to remove any ambiguity as to the starting point from which the name is interpreted.
• The name should contain no other slashes to avoid implementation-defined behavior. E.g., if the file system is used, the names /mysem and //mysem would evaluate to the same filename, but if the implementation doesn’t use the file system, the two names could be treated as different(consider what would happen if the implementation hashed the name to an integer value used to identify the semaphore).
• The maximum length of the semaphore name is implementation defined. The name should be no longer than _POSIX_NAME_MAX(Figure 2.8) characters, because this is the minimum acceptable limit to the maximum name length if the implementation does use the file system. - The sem_open function returns a semaphore pointer that we can pass to other semaphore functions when we want to operate on the semaphore. When we are done with the semaphore, we can call the sem_close function to release any resources associated with the semaphore.
#include <semaphore.h>
int sem_close(sem_t *sem);
Returns: 0 if OK, -1 on error- If our process exits without having first called sem_close, the kernel will close any open semaphores automatically. Note that this doesn’t affect the state of the semaphore value-if we have incremented its value, this doesn’t change just because we exit. Similarly, if we call sem_close, the semaphore value is unaffected. There is no mechanism equivalent to the SEM_UNDO flag found with XSI semaphores.
- To destroy a named semaphore, we can use the sem_unlink function.
#include <semaphore.h>
int sem_unlink(const char *name);
Returns: 0 if OK, -1 on error- The sem_unlink function removes the name of the semaphore. If there are no open references to the semaphore, then it is destroyed. Otherwise, destruction is deferred until the last open reference is closed.
- Unlike with XSI semaphores, we can only adjust the value of a POSIX semaphore by one with a single function call. Decrementing the count is analogous to locking a binary semaphore or acquiring a resource associated with a counting semaphore.
- Note that there is no distinction of semaphore type with POSIX semaphores. Whether we use a binary semaphore or a counting semaphore depends on how we initialize and use the semaphore. If a semaphore only ever has a value of 0 or 1, then it is a binary semaphore.
- When a binary semaphore has a value of 1, we say that it is “unlocked;” when it has a value of 0, we say that it is “locked.” To decrement the value of a semaphore, we can use either the sem_wait or sem_trywait function.
#include <semaphore.h>
int sem_trywait(sem_t *sem);
int sem_wait(sem_t *sem);
Both return: 0 if OK, -1 on error- With the sem_wait function, we will block if the semaphore count is 0. We won’t return until we have successfully decremented the semaphore count or are interrupted by a signal. We can use the sem_trywait function to avoid blocking. If the semaphore count is zero when we call sem_trywait, it will return -1 with errno set to EAGAIN instead of blocking.
- A third alternative is to block for a bounded amount of time. We can use the sem_timedwait function for this purpose.
#include <semaphore.h>
#include <time.h>
int sem_timedwait(sem_t *restrict sem,
const struct timespec *restrict tsptr);
Returns: 0 if OK, -1 on error- The tsptr argument specifies the absolute time when we want to give up waiting for the semaphore. The timeout is based on the CLOCK_REALTIME clock(recall Figure 6.8). If the semaphore can be decremented immediately, then the value of the timeout doesn’t matter-even though it might specify some time in the past, the attempt to decrement the semaphore will still succeed. If the timeout expires without being able to decrement the semaphore count, then sem_timedwait will return -1 with errno set to ETIMEDOUT.
- To increment the value of a semaphore, we call the sem_post function. This is analogous to unlocking a binary semaphore or releasing a resource associated with a counting semaphore.
#include <semaphore.h>
int sem_post(sem_t *sem);
Returns: 0 if OK, -1 on error- If a process is blocked in a call to sem_wait(or sem_timedwait) when we call sem_post, the process is awakened and the semaphore count that was just incremented by sem_post is decremented by sem_wait(or sem_timedwait).
- When we want to use POSIX semaphores within a single process, it is easier to use unnamed semaphores. This only changes the way we create and destroy the semaphore. To create an unnamed semaphore, we call the sem_init function.
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
Returns: 0 if OK, -1 on error- The pshared argument indicates if we plan to use the semaphore with multiple processes. If so, we set it to a nonzero value. The value argument specifies the initial value of the semaphore.
- Instead of returning a pointer to the semaphore like sem_open does, we need to declare a variable of type sem_t and pass its address to sem_init for initialization. If we plan to use the semaphore between two processes, we need to ensure that the sem argument points into the memory extent that is shared between the processes.
- When we are done using the unnamed semaphore, we can discard it by calling the sem_destroy function.
#include <semaphore.h>
int sem_destroy(sem_t *sem);
Returns: 0 if OK, -1 on error- After calling sem_destroy, we can’t use any of the semaphore functions with sem unless we reinitialize it by calling sem_init again.
- One other function is available to allow us to retrieve the value of a semaphore. We call the sem_getvalue function for this purpose.
#include <semaphore.h>
int sem_getvalue(sem_t *restrict sem, int *restrict valp);
Returns: 0 if OK, -1 on error- On success, the integer pointed to by the valp argument will contain the value of the semaphore. Be aware, however, that the value of the semaphore can change by the time that we try to use the value we just read. Unless we use additional synchronization mechanisms to avoid this race, the sem_getvalue function is useful only for debugging. The sem_getvalue function is not supported by Mac OS X 10.6.8.
Example
- One of the motivations for introducing the POSIX semaphore interfaces was that they can be made to perform significantly better than the existing XSI semaphore interfaces. It is instructive to see if this goal was reached in existing systems, even though these systems were not designed to support real-time applications.
- In Figure 15.34, we compare the performance of using XSI semaphores(without SEM_UNDO) and POSIX semaphores when 3 processes compete to allocate and release the semaphore 1,000,000 times on two platforms(Linux 3.2.0 and Solaris 10).
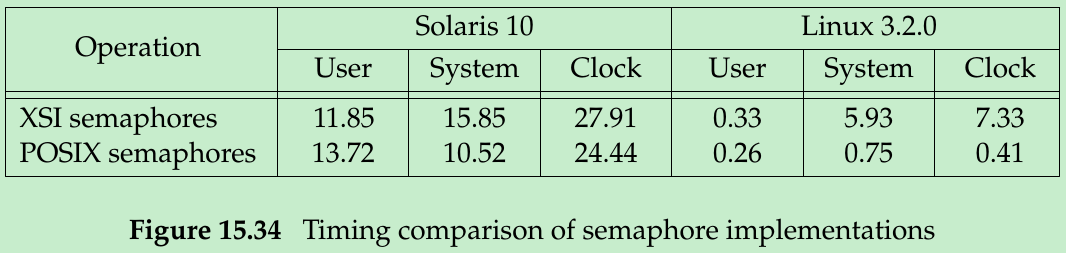
- In Figure 15.34, we can see that POSIX semaphores provide only a 12% improvement over XSI semaphores on Solaris, but on Linux the improvement is 94%(almost 18 times faster)! If we trace the programs, we find that the Linux implementation of POSIX semaphores maps the file into the process address space and performs individual semaphore operations without using system calls.
Example
- Recall from Figure 12.5 that the Single UNIX Specification doesn’t define what happens when one thread locks a normal mutex and a different thread tries to unlock it, but that error-checking mutexes and recursive mutexes generate errors in this case. Because a binary semaphore can be used like a mutex, we can use a semaphore to create our own locking primitive to provide mutual exclusion.
- Assuming we were to create our own lock that could be locked by one thread and unlocked by another, our lock structure might look like
struct slock
{
sem_t* semp;
char name[_POSIX_NAME_MAX];
};- The program in Figure 15.35 shows an implementation of a semaphore-based mutual exclusion primitive.


- We create a name based on the process ID and a counter. We don’t bother to protect the counter with a mutex, because if two racing threads call s_alloc at the same time and end up with the same name, using the O_EXCL flag in the call to sem_open will cause one to succeed and one to fail with errno set to EEXIST, so we just retry if this happens. Note that we unlink the semaphore after opening it. This destroys the name so that no other process can access it and simplifies cleanup when the process ends.
15.11 Client-Server Properties
- Let’s detail some of the properties of clients and servers that are affected by the various types of IPC used between them. The simplest type of relationship is to have the client fork and exec the desired server. Two half-duplex pipes can be created before the fork to allow data to be transferred in both directions. Figure 15.16 is an example of this arrangement. The server that is executed can be a set-user-ID program, giving it special privileges. Also, the server can determine the real identity of the client by looking at its real user ID.(Recall from Section 8.10 that the real user ID and real group ID don’t change across an exec.)
- With this arrangement, we can build an open server.(We show an implementation of this client-server mechanism in Section 17.5.) It opens files for the client instead of the client calling the open function. This way, additional permission checking can be added, above and beyond the normal UNIX system user/group/other permissions. We assume that the server is a set-user-ID program, giving it additional permissions(root permission, perhaps). The server uses the real user ID of the client to determine whether to give it access to the requested file. This way, we can build a server that allows certain users permissions that they don’t normally have.
- In this example, since the server is a child of the parent, all the server can do is pass back the contents of the file to the parent. Although this works fine for regular files, it can’t be used for special device files, E.g.. We would like to be able to have the server open the requested file and pass back the file descriptor. Whereas a parent can pass a child an open descriptor, a child cannot pass a descriptor back to the parent(unless special programming techniques are used, which we cover in Chapter 17).
- We showed the next type of server in Figure 15.23. The server is a daemon process that is contacted using some form of IPC by all clients. We can’t use pipes for this type of client-server arrangement. A form of named IPC is required, such as FIFOs or message queues. With FIFOs, we saw that an individual per-client FIFO is also required if the server is to send data back to the client. If the client-server application sends data only from the client to the server, a single well-known FIFO suffices.(The System V line printer spooler used this form of client-server arrangement. The client was the lp(1) command, and the server was the lpsched daemon process. A single FIFO was used, since the flow of data was only from the client to the server. Nothing was sent back to the client.)
- Multiple possibilities exist with message queues.
- A single queue can be used between the server and all the clients, using the type field of each message to indicate the message recipient. E.g., the clients can send their requests with a type field of 1. Included in the request must be the client’s process ID. The server then sends the response with the type field set to the client’s process ID. The server receives only the messages with a type field of 1(the fourth argument for msgrcv), and the clients receive only the messages with a type field equal to their process IDs.
- Alternatively, an individual message queue can be used for each client. Before sending the first request to a server, each client creates its own message queue with a key of IPC_PRIVATE. The server also has its own queue, with a key or identifier known to all clients. The client sends its first request to the server’s well-known queue, and this request must contain the message queue ID of the client’s queue. The server sends its first response to the client’s queue, and all future requests and responses are exchanged on this queue.
- One problem with this technique is that each client-specific queue usually has only a single message on it: a request for the server or a response for a client. This seems wasteful of a limited systemwide resource(a message queue), and a FIFO can be used instead. Another problem is that the server has to read messages from multiple queues. Neither select nor poll works with message queues.
- Either of these two techniques using message queues can be implemented using shared memory segments and a synchronization method(a semaphore or record locking).
- The problem with this type of client-server relationship(the client and the server being unrelated processes) is for the server to identify the client accurately. Unless the server is performing a nonprivileged operation, it is essential that the server know who the client is. This is required, E.g., if the server is a set-user-ID program.
- Although all these forms of IPC go through the kernel, there is no facility provided by them to have the kernel identify the sender.
- With message queues, if a single queue is used between the client and the server(so that only a single message is on the queue at a time, E.g.), the msg_lspid of the queue contains the process ID of the other process. But when writing the server, we want the effective user ID of the client, not its process ID. There is no portable way to obtain the effective user ID, given the process ID.(Naturally, the kernel maintains both values in the process table entry, but other than rummaging around through the kernel’s memory, we can’t obtain one, given the other.)
- We’ll use the following technique in Section 17.2 to allow the server to identify the client. The same technique can be used with FIFOs, message queues, semaphores, and shared memory. For the following description, assume that FIFOs are being used, as in Figure 15.23. The client must create its own FIFO and set the file access permissions of the FIFO so that only user-read and user-write are on. We assume that the server has superuser privileges(or else it probably wouldn’t care about the client’s true identity), so the server can still read and write to this FIFO. When the server receives the client’s first request on the server’s well-known FIFO(which must contain the identity of the client-specific FIFO), the server calls either stat or fstat on the client-specific FIFO.
- The server assumes that the effective user ID of the client is the owner of the FIFO(the st_uid field of the stat structure). The server verifies that only the user-read and user-write permissions are enabled. As another check, the server should look at the three times associated with the FIFO(the st_atime, st_mtime, and st_ctime fields of the stat structure) to verify that they are recent(no older than 15 or 30 seconds, E.g.). If a malicious client can create a FIFO with someone else as the owner and set the file’s permission bits to user-read and user-write only, then the system has other fundamental security problems.
- To use this technique with XSI IPC, recall that the ipc_perm structure associated with each message queue, semaphore, and shared memory segment identifies the creator of the IPC structure(the cuid and cgid fields). As with the example using FIFOs, the server should require the client to create the IPC structure and have the client set the access permissions to user-read and user-write only. The times associated with the IPC structure should also be verified by the server to be recent(since these IPC structures hang around until explicitly deleted).
- We’ll see in Section 17.3 that a far better way of doing this authentication is for the kernel to provide the effective user ID and effective group ID of the client. This is done by the socket subsystem when file descriptors are passed between processes.
15.12 Summary
- We’ve detailed numerous forms of interprocess communication: pipes, named pipes(FIFOs), the three forms of IPC commonly called XSI IPC(message queues, semaphores, and shared memory), and an alternative semaphore mechanism provided by POSIX.
- Semaphores are really a synchronization primitive, not true IPC, and are often used to synchronize access to a shared resource, such as a shared memory segment. With pipes, we looked at the implementation of the popen function, at coprocesses, and at the pitfalls that can be encountered with the standard I/O library’s buffering.
- After comparing the timing of message queues versus full-duplex pipes, and semaphores versus record locking, we can make the following recommendations: learn pipes and FIFOs, since these two basic techniques can still be used effectively in numerous applications. Avoid using message queues and semaphores in any new applications. Full-duplex pipes and record locking should be considered instead, as they are far simpler. Shared memory still has its use, although the same functionality can be provided through the use of the mmap function(Section 14.8).
- In the next chapter, we will look at network IPC, which can allow processes to communicate across machine boundaries.
Exercises(Redo)
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









