







【北上广深杭等大厂面试|高频AI算法题】机器学习篇…本篇介绍为什么L2正则化可以有效防止过拟合?附代码
【北上广深杭等大厂面试|高频AI算法题】机器学习篇…本篇介绍为什么L2正则化可以有效防止过拟合?附代码
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/gaoxiaoxiao1209/article/details/145551502
为什么 L2 正则化可以有效防止过拟合?
- L2 正则化(Ridge 回归)是一种常见的正则化技术,主要通过对模型参数的平方进行惩罚来限制模型的复杂度,从而有效防止过拟合。
- 在机器学习中,过拟合指的是模型在训练数据上表现得很好,但在未见过的测试数据上表现差,这通常是因为模型在训练过程中学到了数据中的噪声或不必要的复杂性。
L2 正则化的作用
L2 正则化通过对损失函数添加一个正则项来限制模型的复杂度。这个正则项是模型参数的平方和,它的数学形式为:
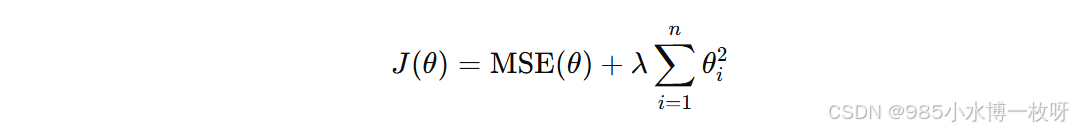
其中:
- MSE 是均方误差(Mean Squared Error)损失函数,表示模型在训练数据上的预测误差。
- λ λ λ 是正则化强度超参数,控制着正则项的影响程度。
- θ i θ_i θi 是模型的参数(如线性回归的权重)。
通过引入 θ i 2 θ^2_i θi2 项,L2 正则化限制了参数的值,尤其是较大的参数值。这种限制可以让模型避免过于复杂的拟合,从而有效减小过拟合的风险。
L2 正则化防止过拟合的机制
- 惩罚大参数值:L2 正则化的核心作用是惩罚大的权重系数。L2 正则项( θ i 2 θ^2_i θi2 )的存在使得模型会更倾向于选择较小的权重,尤其是避免某些特征的权重过大。过大的权重可能意味着模型在训练数据上的过拟合,学到了数据中的噪声。因此,L2 正则化通过鼓励权重的小值来减小模型的复杂度,进而提高泛化能力。
- 平滑模型的权重:L2 正则化不仅限制了单个参数的大小,它通过将所有的权重缩小到较小的值,使得模型的参数更加平滑(即在多个特征上分配较小的权重)。这有助于避免模型依赖某个特定特征,并减少过拟合的可能性。
- 防止多重共线性:L2 正则化能够有效缓解多重共线性问题(即特征之间高度相关)。在没有正则化时,相关的特征可能导致模型参数估计不稳定,从而影响模型的泛化能力。L2 正则化通过压缩相关特征的权重,使得它们的影响力趋于平衡,从而减少过拟合。
- 平衡训练误差与模型复杂度:L2 正则化通过平衡训练误差和模型复杂度,使得模型在训练数据上不会过于拟合。正则化项对模型复杂度的惩罚,使得模型更加“简单”,从而有更好的泛化能力。
代码示例:L2 正则化防止过拟合
我们通过一个简单的线性回归例子来演示 L2 正则化如何防止过拟合。我们使用 Python 和 scikit-learn 库来实现 L2 正则化(Ridge 回归)。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 生成一个带噪声的线性数据集
np.random.seed(42)
X = np.random.rand(100, 1) * 10
y = 2 * X + 3 + np.random.randn(100, 1) * 2 # y = 2x + 3 + noise
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练没有正则化的线性回归模型
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
# 创建并训练使用 L2 正则化的 Ridge 回归模型
ridge_reg = Ridge(alpha=1.0) # alpha 是正则化强度,相当于 lambda
ridge_reg.fit(X_train, y_train)
# 预测
y_pred_lin = lin_reg.predict(X_test)
y_pred_ridge = ridge_reg.predict(X_test)
# 计算误差
mse_lin = mean_squared_error(y_test, y_pred_lin)
mse_ridge = mean_squared_error(y_test, y_pred_ridge)
# 输出结果
print(f"Linear Regression MSE: {mse_lin:.2f}")
print(f"Ridge Regression MSE: {mse_ridge:.2f}")
# 可视化结果
plt.scatter(X, y, color='blue', label='Data')
plt.plot(X, lin_reg.predict(X), color='red', label='Linear Regression (No Regularization)')
plt.plot(X, ridge_reg.predict(X), color='green', label='Ridge Regression (L2 Regularization)')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Effect of L2 Regularization')
plt.show()
代码解释:
- 生成数据:我们首先创建了一个线性关系的数据集,并加入了一些噪声。目标函数是 y = 2 x + 3 + n o i s e y=2x+3+noise y=2x+3+noise。
- 分割数据:我们将数据集分为训练集和测试集。
- 训练模型:我们使用 LinearRegression 训练了一个没有正则化的线性回归模型(即普通的最小二乘法),然后使用 Ridge 训练了一个带有 L2 正则化的 Ridge 回归模型。
- 预测和评估:我们计算了这两个模型在测试集上的均方误差(MSE),并进行比较。
- 可视化:我们可视化了训练数据和两个模型的拟合结果。
结果分析:
- 没有正则化(线性回归):在没有正则化的情况下,模型可能会对训练数据进行过拟合,导致在测试集上的误差较大。
- 带有正则化(Ridge 回归):L2 正则化通过惩罚大权重,减小了模型的复杂度,通常能减少过拟合,使得测试集的误差相对较小。
结论
- L2 正则化通过缩小模型的权重参数(尤其是较大的权重),避免了模型过于依赖某些特征,从而有效地减小了过拟合的风险。它通过引入正则项,平衡了训练误差和模型复杂度,有助于提高模型的泛化能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











