







【AI大模型学习路线】第一阶段之大模型开发基础——第二章(大模型的训练与应用)大模型发展史?大模型预训练、微调到应用的过程?
【AI大模型学习路线】第一阶段之大模型开发基础——第二章(大模型的训练与应用)大模型发展史?大模型预训练、微调到应用的过程?
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://fighting.blog.csdn.net/article/details/146691809
🧠 一、大模型发展历史全景(简明年表)
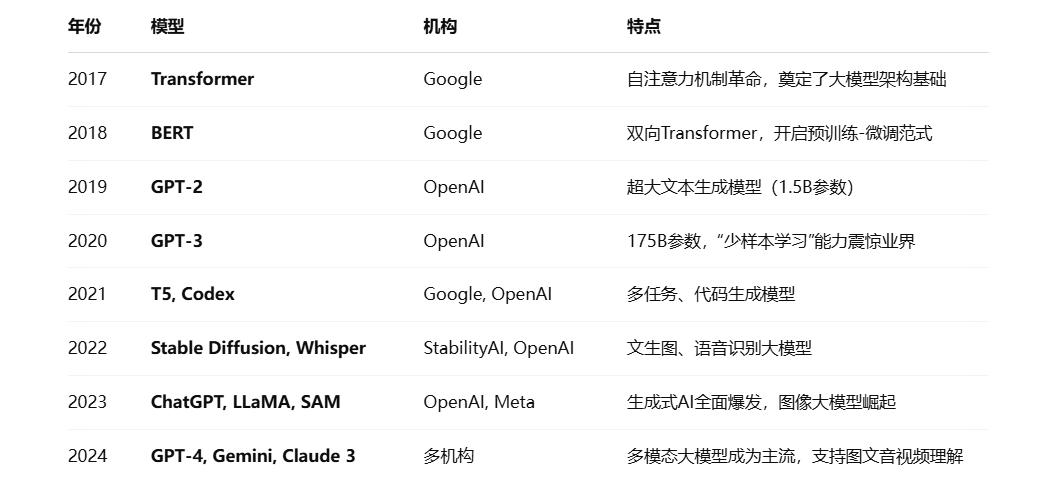
🧩 二、大模型完整开发流程
包括三个关键阶段:
1️⃣ 大模型预训练(Pretraining)
目的:学习海量数据中的通用表示能力(语言、图像、知识等)
方式:
- 自监督学习(Masked Language Modeling、Causal Language Modeling)
- 使用数百GB到TB级别数据训练(如 CommonCrawl)
常用代码框架:transformers, accelerate, torch.distributed
# 示例:从头预训练语言模型(以GPT为例)
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
# 预训练数据准备(伪代码)
inputs = tokenizer("Hello, I am learning...", return_tensors="pt")
labels = inputs["input_ids"]
# 自监督损失训练
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
- 预训练阶段通常只由大型机构完成,如 OpenAI、Google、Meta、阿里、百度等。
2️⃣ 微调(Fine-tuning)
目的:让大模型适配特定任务,如问答、分类、摘要、翻译、遥感分割等。
技术点:
- 全参数微调(fine-tuning):对所有模型参数进行训练
- 参数高效微调(PEFT):如 LoRA、Prefix-Tuning,仅调整小部分参数
🌟 示例:使用LoRA对大模型微调(huggingface + peft)
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskType
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
# 配置LoRA微调参数
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.1,
bias="none"
)
# 添加LoRA adapter层
model = get_peft_model(model, config)
model.print_trainable_parameters()
- 该方法可将原本需要几百G显存的训练变成单卡可完成的微调任务。
3️⃣ 应用部署(Inference & Serving)
目的:将训练好的大模型部署为可用服务(如API、Web界面、插件)
✅ 常用部署方式

示例:用 Gradio 部署大模型
import gradio as gr
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
def respond(prompt):
result = generator(prompt, max_new_tokens=50)
return result[0]["generated_text"]
gr.Interface(fn=respond, inputs="text", outputs="text").launch()
🚀 三、大模型应用场景
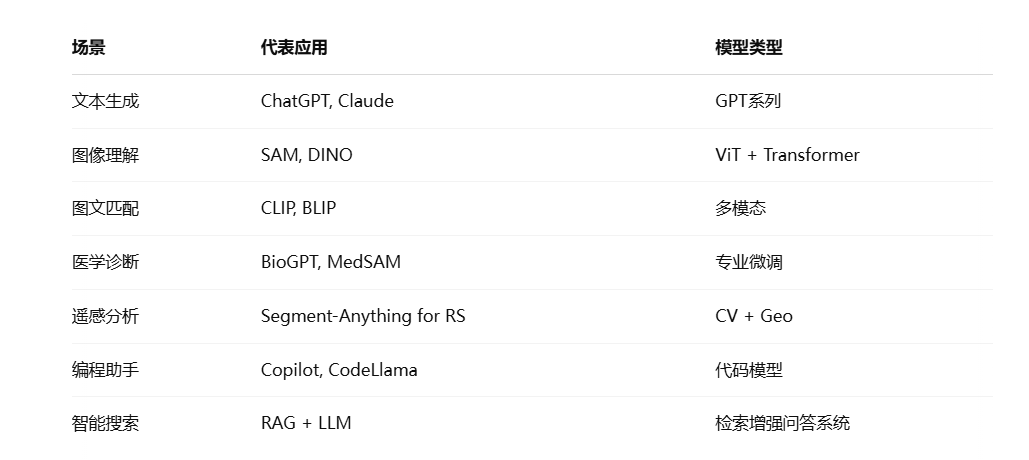
✅ 总结:大模型开发三步法




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











