







【AI大模型学习路线】第二阶段之RAG基础与架构——第七章(【项目实战】基于RAG的PDF文档助手)产品介绍与核心功能?
【AI大模型学习路线】第二阶段之RAG基础与架构——第七章(【项目实战】基于RAG的PDF文档助手)产品介绍与核心功能?
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://fighting.blog.csdn.net/article/details/147360609
前言
以下是基于 RAG(检索增强生成)构建的“PDF 文档助手”演示产品的简洁产品概述及核心功能分解。我们首先总结其价值主张,然后列出关键特性并展示每个特性如何映射到 RAG 模块,最后简要展示一个最小化的 Python 代码片段来说明端到端流程。
概览
该 PDF 文档助手定位于帮助用户快速理解、提问并生成基于任意 PDF 文档的定制化报告。其核心价值在于:
- 动态知识注入:实时将 PDF 内容检索并注入 LLM,上下文永不过时。
- 高准确度问答:RAG 检索降低 hallucination,用户可获得精准引用和段落定位。
- 自动化报告生成:一键生成摘要、目录、关键洞见和可视化,显著提升文档处理效率。
产品介绍
用户界面
- 上传与管理:支持单文档/批量上传 PDF,自动提取元数据(标题、作者、页数)。
- 交互式查询:在侧边栏直接输入自然语言问题,系统即时返回答案并高亮对应 PDF 段落。
- 报告导出:将问答记录、摘要与图表一键导出为新的 PDF 或 Word 文档。
技术架构
1. 文档处理流水线
- PDF 文本抽取 → 分段(chunking) → 向量化入库(Indexing)
2. RAG 引擎
- Query Encoder → 向量检索(Retriever) → 上下文增强(Augmentation) → 生成(Generator)
3. 前端展示
- React/Vue 应用负责文件管理、问答界面与报告导出。
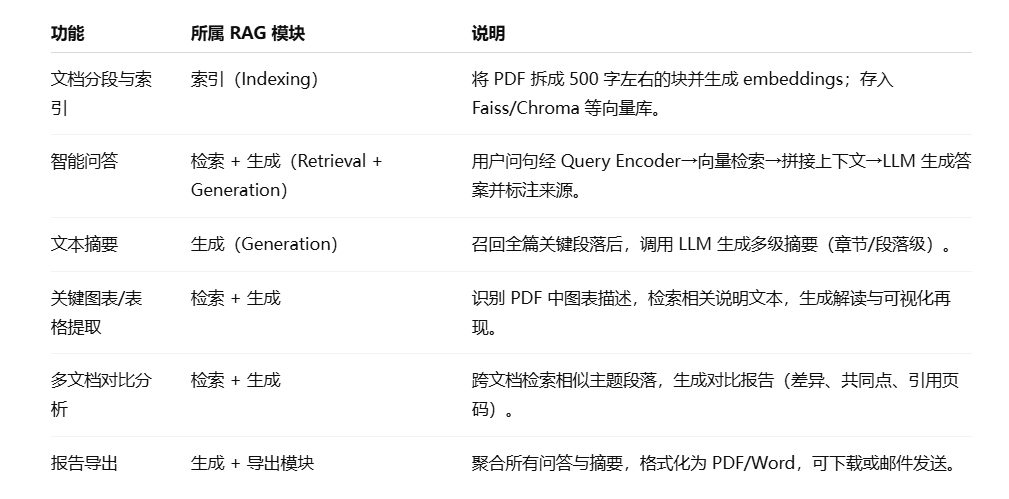
核心功能
Python 核心流程示例
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
from pdfminer.high_level import extract_text
import faiss, json
# 1. 文档加载与分段
text = extract_text("document.pdf")
chunks = [text[i:i+500] for i in range(0, len(text), 500)]
# 2. 向量化 & 索引
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", passages_path=None)
# 假设 retriever.add_documents 接口可批量添加
retriever.add_documents(chunks)
# 3. 问答函数
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-base")
def answer_question(query, top_k=5):
inputs = tokenizer(query, return_tensors="pt")
generated = model.generate(input_ids=inputs.input_ids, n_docs=top_k)
return tokenizer.batch_decode(generated, skip_special_tokens=True)[0]
print(answer_question("本报告的主要结论是什么?"))
- 分段与索引:将 PDF 文本切为固定块并载入 RAG 检索库(Indexing)。
- 检索与生成:
model.generate内部完成 Query Encoding、ANN 检索、上下文增强与文本生成(Retrieval + Generation)。
通过上述产品概览、功能列表及 Python 示例,可见基于 RAG 的 PDF 文档助手如何模块化地将检索与生成结合,为用户在海量文档中提供精准、高效、可审计的智能问答与报告服务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











