







【AI大模型学习路线】第二阶段之RAG基础与架构——第八章(文档切分常见算法)根据每个Sentence切分?
【AI大模型学习路线】第二阶段之RAG基础与架构——第八章(文档切分常见算法)根据每个Sentence切分?
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://fighting.blog.csdn.net/article/details/147360609
前言
在面向 RAG 的文档预处理管道中,基于“句子(Sentence)”进行切分(chunking)是最直观且广泛应用的策略:它先借助 NLP 的句子分割算法将全文拆为若干独立句子,再按照固定句数、滑动窗口或语义断点将若干句子组合成块,以兼顾检索粒度与上下文连续性。下面我们从原理、常见算法、Python 实现和未来趋势四个方面详述“按句子切分”方法。
原理与优势
- 句子完整性:直接以句子为最小单元可确保不破坏语义边界,避免模型接收到不完整的语义片段。
- 可控粒度:通过调整“每块包含句子数”或“滑动窗口步长”,可灵活控制每个 chunk 的长度,兼顾上下文范围与检索效率。
- 简单易实现:主流 NLP 库(NLTK、spaCy、Stanza)都提供高质量句子分割工具,开箱即用。
常见算法
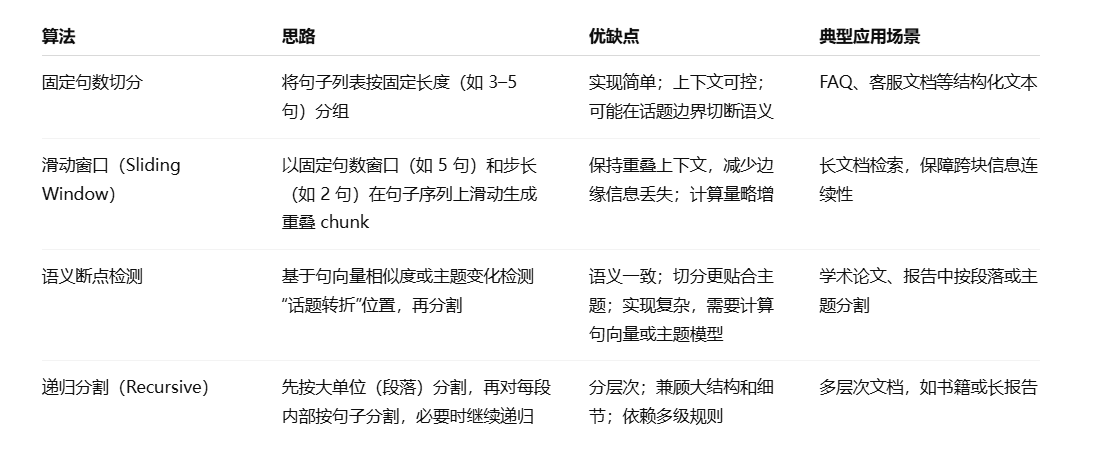
Python 端到端示例
以下示例展示三种基于句子的切分策略:
import nltk
from sentence_transformers import SentenceTransformer
import numpy as np
# 确保已下载 punkt
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
text = """人工智能(AI)大模型在自然语言处理领域取得了突破性进展。\
然而,仅依赖模型参数记忆的知识存在过时风险。RAG 通过检索外部文档,动态注入最新信息。\
基于句子的切分算法能有效保障检索粒度与上下文完整性,是 RAG 预处理的核心环节之一。"""
# 1. 句子分割
sentences = sent_tokenize(text) # :contentReference[oaicite:3]{index=3}
print("切分得到句子:", sentences)
# 2. 固定句数切分:每块 2 句
fixed_chunks = [ sentences[i:i+2] for i in range(0, len(sentences), 2) ]
print("固定句数切分(2句/块):", fixed_chunks)
# 3. 滑动窗口切分:窗口 2 句,步长 1 句
sliding_chunks = [ sentences[i:i+2] for i in range(0, len(sentences)-1, 1) ]
print("滑动窗口切分(窗口=2, 步长=1):", sliding_chunks)
# 4. 语义断点切分:基于句向量余弦相似度,分割相似度骤降处
model = SentenceTransformer('all-MiniLM-L6-v2') # :contentReference[oaicite:4]{index=4}
embs = model.encode(sentences)
sims = [ np.dot(embs[i], embs[i+1])/(np.linalg.norm(embs[i])*np.linalg.norm(embs[i+1]))
for i in range(len(embs)-1) ]
# 找到最低相似度位置作为断点
split_idx = np.argmin(sims) + 1
semantic_chunks = [ sentences[:split_idx], sentences[split_idx:] ]
print("语义断点切分:", semantic_chunks)
代码解析
- 句子分割:
nltk.sent_tokenize基于 Punkt 模型进行语言无关的句边界检测,准确率高。 - 固定句数切分:简单按索引分组,实现最低切分逻辑。
- 滑动窗口:通过可调窗口大小与步长,生成具有重叠的上下文块,减少信息丢失。
- 语义断点检测:利用 Sentence‑Transformers 生成句向量,计算相邻句相似度,选择最小相似度处作为主题转折点。
未来趋势
- 自适应混合切分:结合固定、滑动与语义方法,根据文档类型和实时反馈动态选择最优策略。
- 层次化分割与聚合:引入层次聚类或图分割(如 GRAPHSEG)算法,实现多粒度的块级与段落级协同检索。
- 端到端学习切分:通过带标签的下游任务(QA、摘要)联合微调,将切分规则内置于模型,形成“学习切分”能力。
以上内容系统地介绍了基于句子的文档切分算法及其在 RAG 预处理中的实践,并配以 Python 代码示例,帮助您在大模型项目中灵活应用与优化句子级切分策略。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











