







Machine Learning系列,转载自
http://blog.csdn.net/xuexiang0704/article/details/8934300
以下内容源自coursera上的machine learning,同时参考了Rachel-Zhang的博客(http://blog.csdn.net/abcjennifer)
在讲完了logisitc regression 和 linear regression的两种常用方法后,考虑到一些弊端,我们需要进一步了解其他的机器学习方法,
摘要:
(一)(二):是让我们了解神经网络的一些基本概念;
(三)(四)Neuronsand the Brain I & II:神经网络每一层的工作原理及运算公式.(本节最重要的部分)
(五)(六)Examplesand Intuitions I & II:神经网络怎样进行复杂逻辑运算,即complex hypothesis
(七)
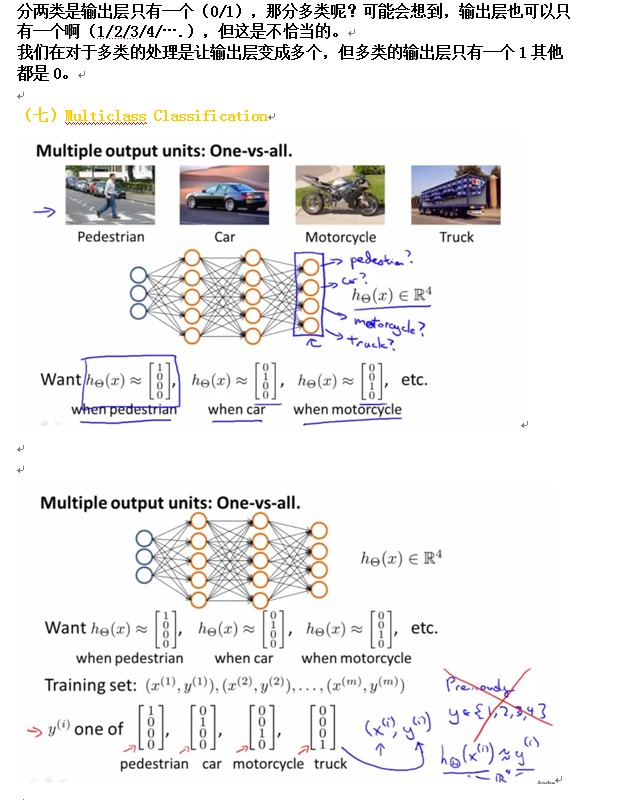
MulticlassClassification:
前面讲的都是针对二类的,多类的应该这么办?
正文:
***************************************************************************************************************************************
(一)Nonlinear hypothesis:
前面讲的linearregression和logistic regression都是针对特征数比较小的。但是,如果特征数比较大呢?如果还用上述两种方法就会显得力不从心,因为不仅运算得慢,还有可能overfitting。
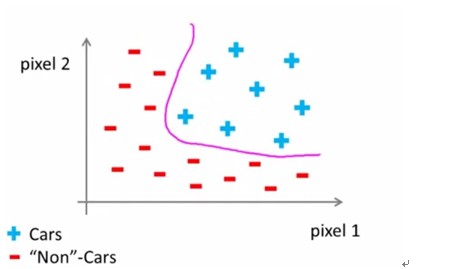
这张图片的boundarydecision是粉红色的曲线,如果用logistic regression就有很大可能造成overfitting。
总之,对于某些情况,前面讲的两种方法已经不适用于分类的。那用什么呢?先给出答案:神经网络
***************************************************************************************************************************************
该节讲了神经网络的起源发展衰退而今又兴起等等。又给了一些amazing的图片,应用等。有兴趣的同学,可以自己上网查查这些好玩的东西。
(因为没有实质性的内容,就是给一个概念,所以就没有截图了。)
***************************************************************************************************************************************
(三)Neuronsand the Brain I & (四)Neurons and the Brain II
这里不讲神经网络和我们人脑作用的相似之处。直接给出神经网络是如何做的。
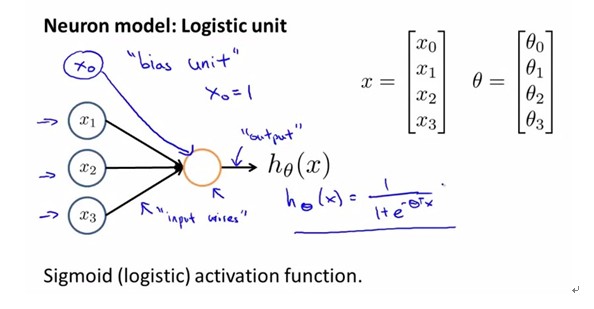
1. 给出一个最简单的logistic uint:
(这里只有两层,第一层就是x0,x1,x2,x3,称为输入层;第二层就是棕色的圈,称为输出层)
2.下面给出最基本的三层模型,并具体看看如何一层一层往下做的。
(注意下面的两幅图是神经网络刚开始比较重要的图,它们说明了具体的工作原理!要是没看懂的话,请务必一遍一遍看直到看懂!!)

我们先不讲公式是如何做的。先来了解上坐标,下坐标以及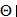
(1).首先记住,任何字母的上坐标就是代表着第几层!(如果是1代表输入层,2代表隐藏层等)。
(2).下坐标,代表着某一层的第几个。
(3).
讲完了三者的含义,就应该分析公式是如何推出来了。

先来解释上面提到的疑惑:为什么纵坐标从0开始?
这张图左上角的和上面左上角的那张图,实质上是一样的,只不过在每一层的最上面加了一个1,这就像logistic regression一样在每一个特征前面都加一个1一样的道理。其实这就是上面我说的为什么纵坐标从0开始.

***************************************************************************************************************************************
(五)Examplesand Intuitions I (六)Examples and Intuitions II
各位都知道或,与,非操作吧。
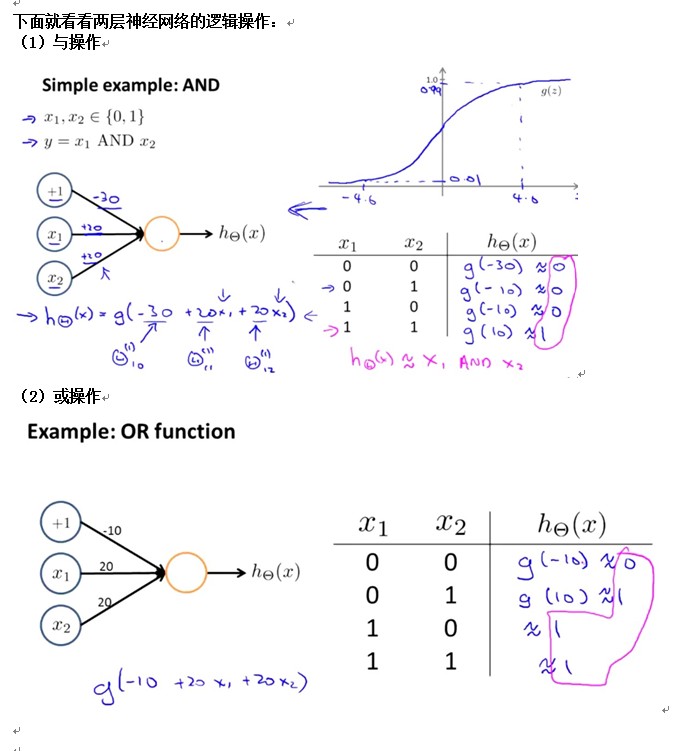
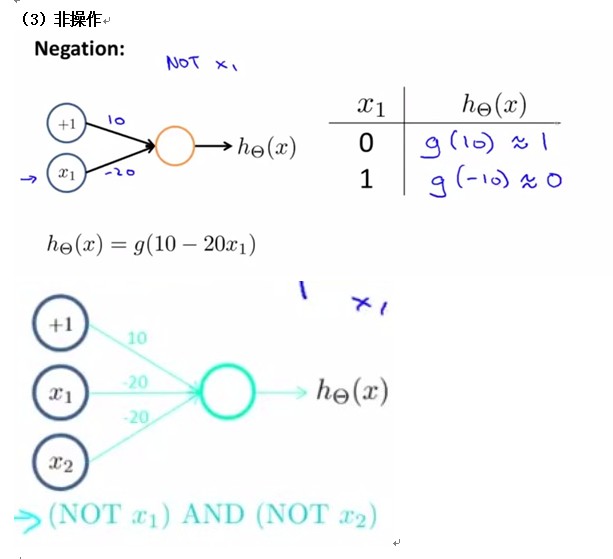
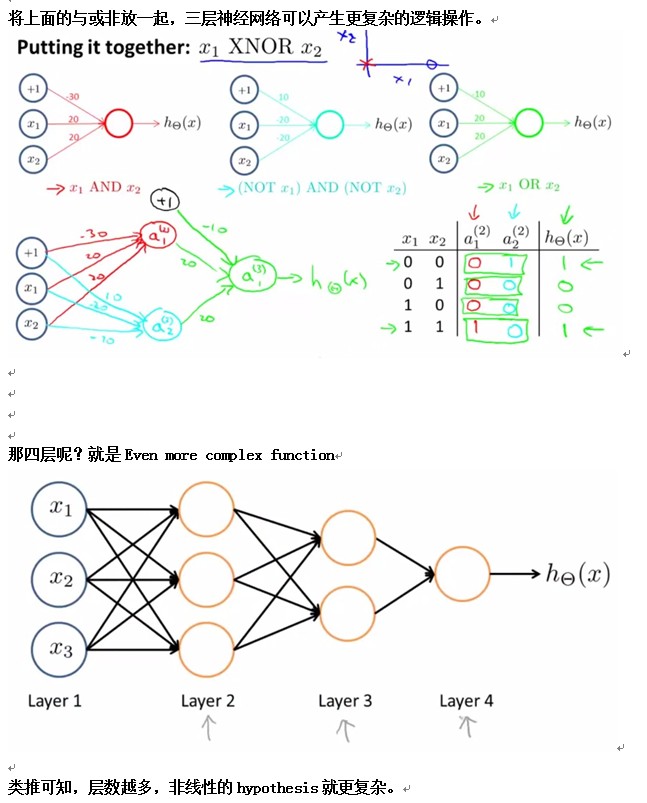
***************************************************************************************************************************************















 5379
5379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









