






一、背景
Masked Autoencoders(掩膜自编码器)在NLP领域大放异彩,它是去噪自编码器[1]的一种具体实现方式,然而其在视觉领域的研究进展却有所滞后。作者指出了视觉和NLP两个领域中掩膜自编码器的差异:
- 架构差异,这一点由于Vit的提出将差异进行了弥合。
- 信息密度不同,自然语言的语义复杂度相比图像更高一些,比如将一个句子的部分单词删除掉,补全缺失的单词似乎是一项非常复杂的语言理解任务,而图像存在较多的信息冗余,比如天空、草地、河流,掩盖部分图像可以从相邻区域进行复原。
- 视觉decoder还原masked块的像素,语义层次较低,NLP的decoder还原的是masked的词,后者拥有的语义信息更丰富,所以BERT中的decoder仅需一个MLP就可以搞定masked的词t复原。所以,就复原难度来说,视觉decoder的难度更大。
综上,以掩膜自编码器的形式构建了一种视觉领域的表征学习器,架构如下,由一个encoder和一个decoder构成。
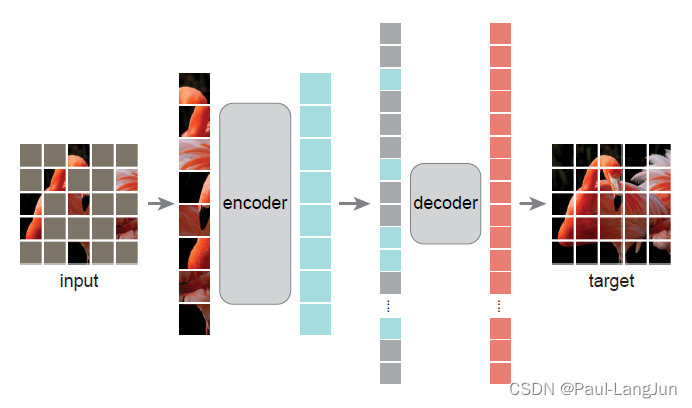
在训练时,将75%的图片块mask掉,送入encoder模块, 所以encoder模块的计算量会比较小,送入decoder的输入是encoder的输出加上mask的图片块,图片块的位置复原为原图位置,decoder输出复原后的图像。所以,我们可以得到一个基本的结论,在训练时MAE的计算量会大幅减少,因为encoder仅需要关注未被mask掉的25%的图像块即可。
在测试时,decoder部分被舍弃,将预训练后的encoder直接应用于完整的图片,得到的输出用于视觉任务。
二、Encoder
Encoder部分使用的是Vit,出彩点是采用了极高的mask比例,75%!有三点好处:第一是计算效率大幅提升,第二个是会促使模型完成高难度的自监督学习任务,得到更鲁棒的图像表征;第二是可以很容易在大模型上做应用,这也是论文题目上Scale出现的原因。
三、Decoder
由于采用了非对称结构设计,decoder可以和encoder解耦,作者采用了更浅而瘦的Vit网络,计算量是encoder部分的1/10,极大的减少了预训练时间。
四、消融实验
- 慎用颜色增强,据作者所述,实验结果有负向作用;
五、参考文献
- Extracting and composing robust features with denoising autoencoders


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









