







记录一下自己学习kafka的经验吧。站在小白新手的角度,从安装到使用,java代码实现。
一、关于消息队列的作用与选择。
消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。消息队列有很多选择:RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、Pulsar...
如何选择看个人,我借用网友一张图来简单对比:

如果想详细了解可以见网友的博文:消息队列对比_郝1.的博客-CSDN博客
我个人觉得用哪个都可以,对于新手来说这不是重点,选型是技术经理或架构师要做的事,我们是要先学会用,懂得举一反三就行。
信奉阿里系的同学,果断用RocketMQ吧,毕竟人家双十一秒杀都不在活下。
如果对性能有极致追求,或者在使用场景中需要到微秒级的,果断用RabbitMQ吧。 RabbitMQ基于 erlang 开发,性能极其好,达到微秒级。其他都是 毫秒级。
我这里选用kafka,原因很简单,Kafka在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准。
热度的话,自己搜一下对比就知道了,以下三个都是人气曝火的:


二、使用docker安装kafka.
kafka的服务需要用到zookeeper用来,用来解决一些诸如服务注册与发现、节点与集群等功能。所以,我们需要安装zookeeper的服务再安装kafka。
(有消息称,Kafka Raft是一种内部管理元数据的协议,将取代ZooKeeper)
(本文采用docker管理,所以需要先安装docker,参见SpringBoot入门学习笔记-19-docker部署jar包-CSDN博客的docker安装部分内容)
1、下载zookeeper镜像。
docker search zookeeper,选择合适的镜像。

执行下载 docker pull zookeeper

2、运行zookeeper 服务
docker run -itd --privileged=true --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper
上面是以后台的方式运行了一个zookeeper服务,只需要关注-p参数,将容器内的2181映射到宿主机的2181端口。

3、下载kafka.
查找kafka镜像 docker search kafka

docker pull bitnami/kafka

4、运行kafka,连接zookeeper
由于docker运行kafka,所以kafka连接的zookeeperip就是宿主机的ip。
docker运行命令:
docker run -itd --privileged=true --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.189.4:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.189.4:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime bitnami/kafka

运行后,通过docker ps -a查看是否两个服务都启动正常,相应的映射端口已经成功。
 5、通过kafka提供的脚本,创建主题,并发送消息进行测试是否成功。
5、通过kafka提供的脚本,创建主题,并发送消息进行测试是否成功。
1)进入kafka容器。docker exec -it kafka bash
2)进入kafka的bin目录 cd /opt/bitnami/kafka/bin

3)创建一个主题order-demo
./kafka-topics.sh --create --topic order-demo --bootstrap-server localhost:9092

多2个shell窗口,分别用来发送消息和接收消息。需要执行上面进入kafka完完全全器以及进入到其bin目录再执行操作。

6、测试生产消息
./kafka-console-producer.sh --topic order-demo --bootstrap-server localhost:9092
回车后,会进入发送消息界面,每条消息用回车确认发送。

7、测试接收消息
在另外两个窗口分别运行:
./kafka-console-consumer.sh --topic order-demo --bootstrap-server localhost:9092
注:上面是不读取历史消息的。下面的这个是读取历史消息的:
./kafka-console-consumer.sh --topic order-demo --from-beginning --bootstrap-server localhost:9092

这时,我们再在生产者中发送一个条消息,两个消费者都可以接收到了。

至此,我们简单的kafka测试就成功了,验证基本的服务是OK的。
三、kafka可视化工具
如果不想用命令查看,可以用可视化工具。但并不是必须的,看自己需要安装。
Offset Explorer (kafkatool.com) 这是官网,去下载并安装。
连接时配置如下:
host\port填服务器的外网IP即可。
chroot path这里默认是/,要改成/kafka。这个地方不改是连不上的。

四、springboot连接kafka
1、springboot集成kafka-cli。
去仓库搜索 kafka-clients,并添加相应的依赖:Maven Central: org.springframework.kafka:spring-kafka (sonatype.com)![]() https://central.sonatype.com/artifact/org.springframework.kafka/spring-kafka
https://central.sonatype.com/artifact/org.springframework.kafka/spring-kafka
maven:
<dependency>
<groupId>rg.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.11</version>
</dependency>
gradle:
implementation group: 'org.springframework.kafka', name: 'spring-kafka',version:'2.8.11'
添加并完成依赖包后,要记得更新并下载依赖包。
注意:springboot版本不同,对应的kafka版本也会不同。。我本地boot版本是2.7.13
2、添加配置到yaml文件
spring:
application:
name: bill-base
kafka:
bootstrap-servers: 192.168.189.4:9092
producer: # 生产者
bootstrap-servers: ${spring.kafka.bootstrap-servers}
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: 1 # 0、1 和 all 默认1,只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # 消费者
group-id: g1
enable-auto-commit: false # 不自提交消费偏移量
auto-offset-reset: earliest
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费分区的记录
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据(在消费者启动之后生成的记录)
# none:当各分区都存在已提交的offset时,从提交的offset开始消费;只要有一个分区不存在已提交的offset,则抛出异常
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
ack-mode: manual_immediate
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交(ENABLE_AUTO_COMMIT_CONFIG=false时生效,有以下几种:)
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE listner负责ack,每调用一次,就立即commit
missing-topics-fatal: false # consumer listener topics 不存在时,启动项目就会报错3、先普极一下kafka的基本概念
| 名称 | 解释 |
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
4、简单消息发送
(实际项目中一般会用工具类封装,这里仅用于测试演示用)
简单消息可以使用KafkaTemplate发送
package com.luo.comm.controller.demo;
import com.luo.comm.vo.Result;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
@RequestMapping("/demo/kafka")
public class KafkaController {
private static final Logger logger = LoggerFactory.getLogger("KafkaController");
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
/**
* 简单消息的发送,使用kafkaTemplate
* */
@GetMapping("/send")
public Result send(@RequestParam String msg) {
kafkaTemplate.send("order_demo", msg);
return Result.ok("OK");
}
}
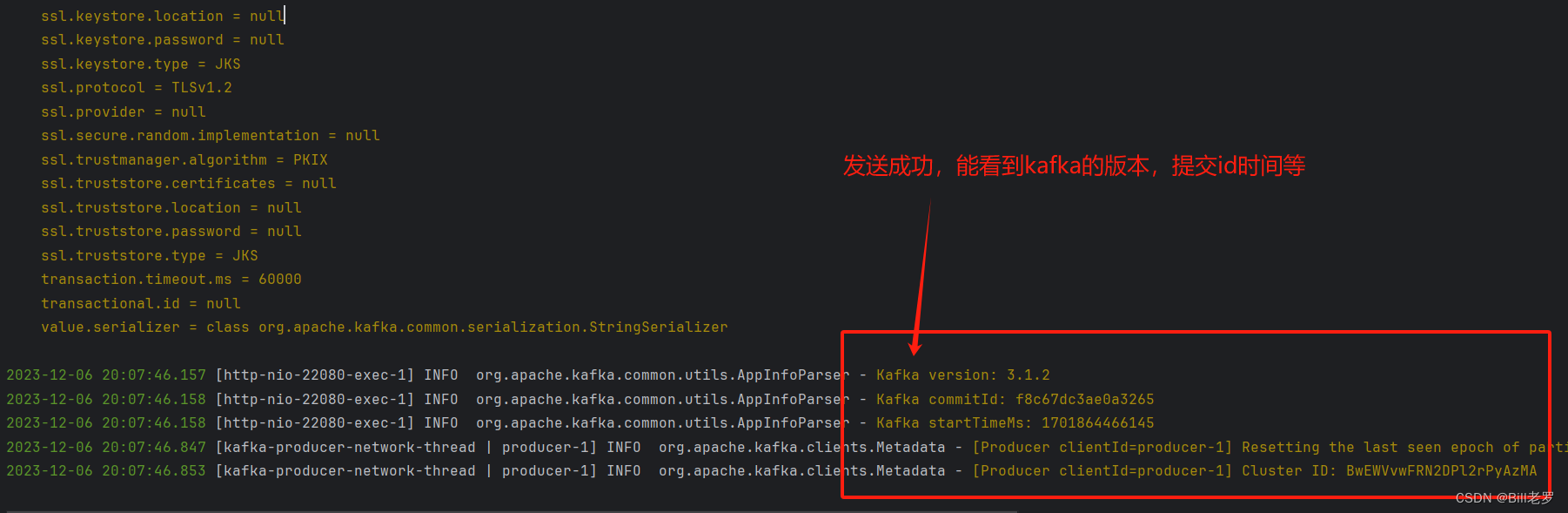
当我们访问/demo/kafka/send?msg=hello-java-kafka时,可以看到控制台会显示相关信息:

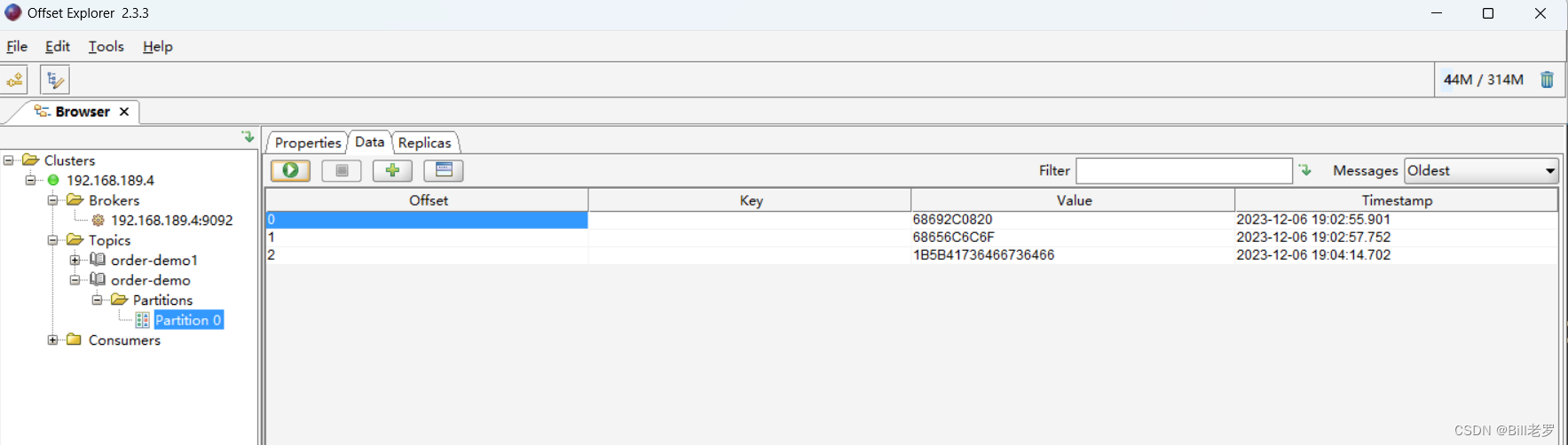
然后,我们在offset Explorer中可以查看消息的内容

注:如果Data显示的二进制数字,可以在主题中设定value格式为String,这样就可以正确显示了。
5、消费者测试类-接收消息
(实际项目中一般会用工具类封装,这里仅用于测试演示用)
通过@KafkaListener注解来使用监听。指定group和topics,当程序运行时,会自动运行,当有消息时会自动触发该方法。
package com.luo.comm.kafka;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class ListenOrderDemo {
private static final Logger logger = LoggerFactory.getLogger(ListenOrderDemo.class);
/**
* 简单消息的接收,使用KafkaListener监听
* */
@KafkaListener(id = "g1", topics = "order_demo")
public void listen(String input) {
logger.info("input value: {}" , input);
}
}

五、kafka中消息的消费
接上面的示例,我们会发现,不论我们重启多少次本软件,监听到的消息一直是这些所有的消息,随着消息的增加会变得很多。
kafka是通过 offset这个值来管理消费组消费进度的,所以我们需要提交这个offset(偏移量来告诉服务器我上次消费到哪里了)
原因是我们在配置文件中设置了spring.kafka.consumer.enable-auto-commit=false,这个不会自提交偏移量。
只需要在@KafkaListener监听方法的入参加入Acknowledgment 即可,执行到ack.acknowledge()代表提交了偏移量。
在下面的方法中,我们做了一个条件,如果发送的消息是ok,则提交一次偏移量。
package com.luo.comm.kafka;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.PartitionOffset;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
@Component
public class ListenOrderDemo {
private static final Logger logger = LoggerFactory.getLogger(ListenOrderDemo.class);
/**
* 简单消息的接收,使用KafkaListener监听
* */
@KafkaListener(id = "g1",topics = "order_demo")
public void listen(String input, Acknowledgment ack) {
logger.info("input value: {}" , input);
if ("ok".equals(input)) {
ack.acknowledge();
// 会提次offset到服务器
logger.info("ack");
}
}
}
当我们再次发送消息一次OK以后,我们会监听消息就会记录偏移量了。然后,不管后面再次启动多次本软件监听,都不会读取以前的数据了。
再没有新的offset提交以前,这些消息都会被认为未消费的,下次client还会继续读取这些消息。
我们可以到可视化工具查看,当前offset值是16,所以消费者下次读取会从这个值开始:



当然,也可以不用这么麻烦,直接设enable.auto.commit=true就可以自动提交了,每次收到消息就视为消费了。但是实际业务中一般需要处理业务逻辑,必须等处理完了才提交。
六、发送带key的消息
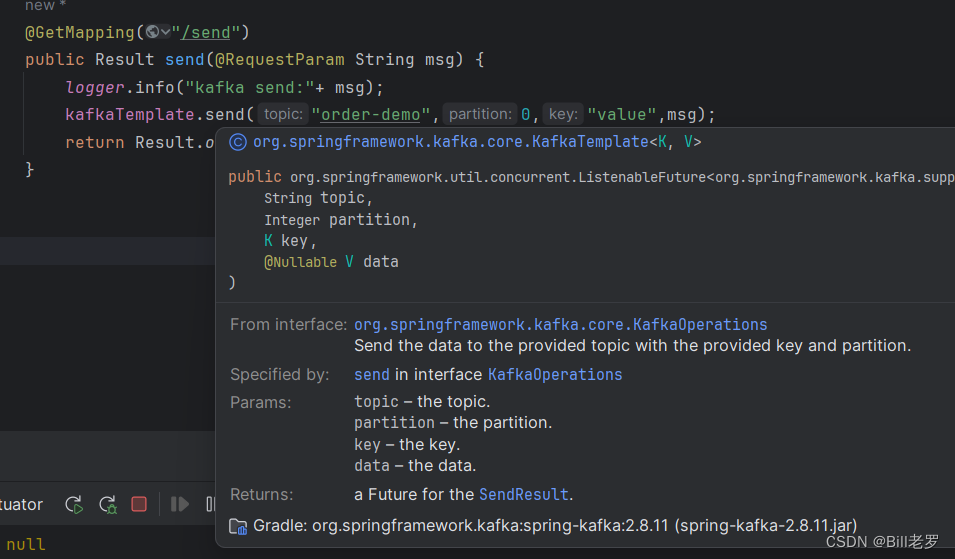
同一个主题,一般需要发送key:value才有意义。那么send方法使用如下:
kafkaTemplate.send("topic",partion,"key","msg");
topic – the topic. partition – the partition. key – the key. data – the data.

七、接收带key的消息
小改一下,通过ConsumerRecord<String,Object>来接收即可。
@KafkaListener(id = "g2",topics = "order-demo")
public void consumer(ConsumerRecord<String,Object> consumerRecord, Acknowledgment ack){
Optional<Object> kafkaMassage = Optional.ofNullable(consumerRecord.value());
Optional<Object> kafkaKey = Optional.ofNullable(consumerRecord.key());
if(kafkaMassage.isPresent()){
Object o = kafkaMassage.get();
Object k = kafkaKey.get();
System.out.println("接收到的key:"+k);
System.out.println("接收到的消息是:"+o);
}
}八、发送成功以后的回调
@GetMapping("/send")
public Result send(@RequestParam String msg) {
logger.info("kafka send:"+ msg);
kafkaTemplate.send("order-demo",0,"value",msg);
kafkaTemplate.send("order-demo",0,"value","ss")
.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onSuccess(SendResult<String, Object> result) {
System.out.println("msg OK." + result.toString());
}
@Override
public void onFailure(Throwable ex) {
System.out.println("msg send failed: " + ex.getMessage());
}
}
);
return Result.ok("OK");
}日志显示如下:

msg OK.SendResult [producerRecord=ProducerRecord(topic=order-demo, partition=0, headers=RecordHeaders(headers = [], isReadOnly = true), key=value, value=ss, timestamp=null), recordMetadata=order-demo-0@9]
通过断点查看,我们可以看到在recordMetadata中,带了offset,那么,我们这个ID如果需要的话后面可以使用。

这个和kafka服务器上是对得上的:

九、结束
本篇起到入门的作用,更高级的用法,后面再单独写吧。暂时先写到这吧。
在实际应用中,消息的发送和接收可能会有并发,需要用多线程进行处理。本文仅用作入门的演示使用。














 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









