







K-近邻(K-Nearest Neighbors, KNN)是一种很好理解的分类算法,简单说来就是从训练样本中找出K个与其最相近的样本,然后看这K个样本中哪个类别的样本多,则待判定的值就属于这个类别。
KNN算法的步骤
- 计算已知类别数据集中每个点与当前点的距离;
- 选取与当前点距离最小的K个点;
- 统计前K个点中每个类别的样本出现的频率;
- 返回前K个点出现频率最高的类别作为当前点的预测分类。
举例:如下图所示,已知两类不同的样本数据,分别用蓝色的正方形和红色三角形表示,而图正中间的那个绿色的圆是待分类的数据。
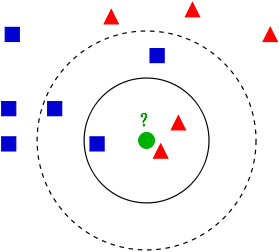
根据KNN算法可知:
- 如果K=3,判定绿色待分类点属于红色的三角形一类。
- 如果K=5,判定绿色待分类点属于蓝色的正方形一类。
可见,K值的选择会对K近邻的分类结果产生重大影响。
在应用中,K值一般取一个比较小的值,通常采用交叉验证法来选取最优的K值。
KNN的思想很好理解,也非常容易实现,同时分类结果较好,对异常值不敏感。但计算复杂度较高,不适于大数据的分类问题。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









