







 本文介绍了图像分类的基本概念,包括图像分类的原理、问题和任务,并详细讲解了k近邻算法在图像分类中的应用,包括L1和L2距离计算,以及k-近邻分类的原理和超参数选取。通过实例展示了k近邻算法的优缺点和实际效果。
本文介绍了图像分类的基本概念,包括图像分类的原理、问题和任务,并详细讲解了k近邻算法在图像分类中的应用,包括L1和L2距离计算,以及k-近邻分类的原理和超参数选取。通过实例展示了k近邻算法的优缺点和实际效果。
这篇文章主要给不知道计算机视觉是啥的人介绍一下图像分类问题以及最近的最近邻算法。
目录
- 图像分类
1.1 图像分类的原理
1.2 面临的问题
1.3 图像分类任务 - 最近邻算法
- 代码实现
- L2距离
- 用k-近邻进行图片分类
5.1 k近邻分类原理
5.2 超参数的选取 - 小结一下最近邻和k近邻
1.图像分类
1.1 图像分类的原理
计算机视觉中的核心问题是给定一张图片的类别,新来一张图片,希望识别图片中物品的类别,比较受欢迎的计算机视觉方面的任务有物体检测,图像分割等。
举个小栗子
图像数据必须要被计算机识别,所以要把图片转化成矩阵,这时候就会有很多问题了。
在下面这张图片中,是使用了一个图片分类模型分类,然后输出这张图片属于那个类别的概率,一共有四个类别(cat,dog,hat,mug)。一张图片可以用可以用一个非常大的三维数组表示,表征的是像素,在下面这张图片中,转化为 数组就是248X400的,同时呢,图片是有颜色分别的,因此多出来了三个颜色通道,分别是红,绿,蓝(RGB),因此一张图片一般用248X400X3表示,后面的3代表颜色通道,一共有297600个数,每个数都是在0-255的范围内。我们的目的就是把这样成千上万维的数分类,输出一个是猫还是狗的类别标签。
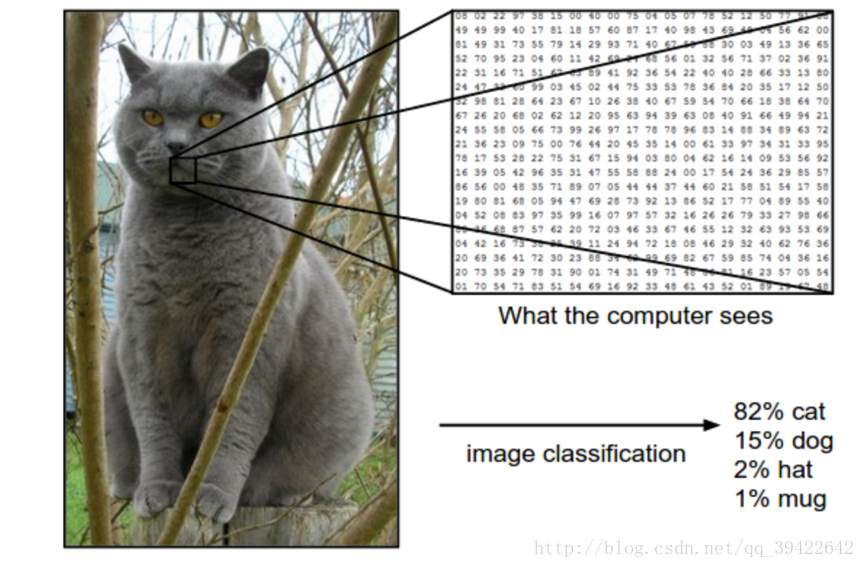
1.2 面临的问题

当照相的时候,摄像头换个角度,拍出来的图片不一样,但猫还是同一只猫,或者一些背景色的也会影响计算机识别。
还有像一些物体的形状不同,却是同以物体,计算机也很难识别。
或者是躲在草丛里的猫,这些图片人一眼就能识别,但计算机却很难识别。

还有很多问题,总之,计算机视觉还有很长一段路要走。哈哈
1.3 图像分类任务
图像分类简单来说就是输入一个表征一张图片的数组,然后输出这张图片所属的类别,总结来说可以分为一下三步:
输入:我们的输入是一个有N张图片组成的集合,每张图片都给了一个特定的类别标签,我们称这样的数据为训练集。
学习:我们的目的就是让模型学习这些图片大概是什么样子,然后记下来。我们称这一步为训练模型。
评估:这一步主要是看我们训练的模型到底好不好。主要内容就是利用上一步训练得来的模型预测一个模型没看过的数据集的标签,然后拿这些标签和真正的标签,我们希望预测出来的这些跟真正的标签尽可能一致。
2.最近邻算法
下来看一下图像分类中的常用算法—最近邻算法
最近邻算法在图像分类中非常简单粗暴,我们用斯坦福大学公布的数据,总共有6万张32X32X3的图片数据,有十个类别,每张图片都属于这十个类别中的一个,我们可以用5000张作为训练集,用1000万张作为测试集。用最近邻算出和该类别中最类似的图片。

用最近邻算出的结果如上右图,可以发现还是有很多分类错的。
最近邻算法的原理很简答,在训练的时候就是光记住每个类别的数据,然后预测的时候算一下测试集中的图片与训练集中的每一张图片的距离,然后看一下跟他距离最近的训练集中的图片的类别,这个类别就是我们要预测的类别。
那距离应该怎么计算呢?一般可以把这个32X32X3的数组展开,然后用距离计算公式计算两个向量之间的距离,L1距离可以表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









