







目录
GaussDB是华为自主创新研发的关系型数据库,基于华为在数据库领域20多年的战略投入,通过多维度的技术创新,在行业实践中构筑了高可用、高安全、高性能、高弹性、高智能的技术优势,在数据库替换场景中,具备易部署、易迁移的特性。作为国内当前唯一能够做到软硬协同、全栈自主的数据库,GaussDB已经在金融、政务、能源、交通等关键信息基础设施行业积累了丰富的实践经验,是企业数字化转型、核心数据上云、分布式改造的信赖之选。
从本期开始,Gauss松鼠会将陆续推出GaussDB技术解读系列文章,带您了解GaussDB的架构及关键技术原理。本篇将从GaussDB 关键架构目标、GaussDB分布式架构、数据计算路由层(Coordinator)关键技术方案等三方面对GaussDB架构进行介绍。
1 GaussDB 关键架构目标
GaussDB在架构设计上,采用组件化原则,分为GaussDB Kernel内核和GaussDB Kernel OM两部分。在产品形态上,提供面向云数据库服务GaussDB(for openGauss)的分布式安装包和集中式安装包,提供面向本地化安装的小型化安装包。
根据华为云提供的调查报告,当前全球数据库市场增长超预期,云是数据库增长最重要驱动力。得益于云数据库的迅猛发展,AWS市场份额超越IBM,成为数据库市场空间第三位,聚焦公有云、混合云构筑具备竞争力的可商用分布式数据库版本,数据库已成为公有云Top收入来源,同时通过数据库服务能够更大地提升公有云服务粘性。GaussDB Kernel面向云服务提供GaussDB产品,主要客户包含金融(银行、证券、保险)行业、政府(政务云、财政等)和大企业客户。结合产品可信要求定义及可信实施策略分析的内容,以及业界数据库厂商前沿动态,GaussDB Kernel在云服务场景中的架构目标按照一下几个维度来展开:
-
高性能:建立基于x86平台与鲲鹏平台的绝对性能领先,鲲鹏平台相对x86平台保证50%性能优势,达到单机170万tpmC,分布式全局强一致32节点1500万tpmC,承载用户关键业务负载;具备性能韧性能力,5倍压力下性能不抖动、十倍压力下系统不崩溃,同时具备抗过载逃生能力;具备大并发、低时延能力,单节点支持1万并发、单集群支持10万级并发访问请求,ms至秒级事务处理时延,支撑政企客户核心业务负载。
-
云原生:通过GTM-Lite技术轻量化处理全局读一致性点与写一致性点,集群扩展性达到256节点,未来通过全球时钟技术演进,在跨Region全局一致性下去除单点瓶颈;面向业务陡增等业务场景,构建基于哈希聚簇的存储结构和弹性扩容方案,实现秒级存储节点扩缩容和业务无感的计算节点弹性伸缩;构建分布式备机只读技术,只读性能提升100%以上。
-
高可用:AZ内主备高可用,1主多备,RPO=0、RTO<10s;同城跨AZ高可用,RPO=0、RTO<60s;跨Region容灾,RPO<10s、RTO<5min;提供备份恢复、PITR、闪回、ALT等企业级高可用特性;构建基于Paxos协议的多副本高可用和并行逻辑复制技术,实现RPO=0的同城双集群高可用容灾和基于流式复制的多地多中心容灾,保证机房级、区域级、城市级故障下的数据库高可用。
-
高安全:继承可信实施策略中安全可信需求,从安全,韧性,隐私等维度构筑安全可信能力,结合业界安全技术前沿发展,设计全密态数据库和防篡改数据库,保证用户敏感数据免于泄露和篡改;构建数据库安全自治管控方法,识别和拦截攻击者的异常行为;构建从接入、访问控制、加密到审计全方位纵深防御的安全防护体系。
-
高智能:面向云化场景故障运维诉求,基于AI技术,提供端到端自治运维管理能力,全面提升数据库产品服务可靠性和可用性;构筑自学习数据库内核,尤其是智能优化器,解决数据库内优化执行过程中计划不准、无法自适应等难题;结合业界前沿技术,构建库内AI引擎,基于SQL-like简易语法,提供数据库内置的机器学习训练和推理能力,为用户提供普惠AI;提供向量数据库能力,支撑盘古大模型、NAIE-NetGPT和GTS领域知识库等场景,提高大模型的预测效率。
GaussDB Kernel提供的本地化版本的架构目标包括:
-
高性能:支撑业务1千并发能力,性能达1000+ TPS;
-
高可用:提供多种部署形态的能力:一主一备、一主多备等;
-
高安全:支持数据库备份加密、网络连接安全管理及传输加密;支持三权分立,即数据库管理员、安全管理员、审计管理员权限职责分离;支持访问控制;
-
高智能:提供丰富高效的DFx运维监测手段,后续朝向基于AI的自治运维调优方向发展,降低BCM相关产品或解决方案的运维成本,提升易用性;
-
小型化:数据库安装包大小<25MB,且数据库刚启动后的底噪内存<250MB。
2 GaussDB分布式架构
2.1 GaussDB 分布式关键技术架构
-
Coordinator: 负责接收SQL请求,路由分发请求到对应的数据节点。同时维护系统元数据(路由分片信息,表定义)。
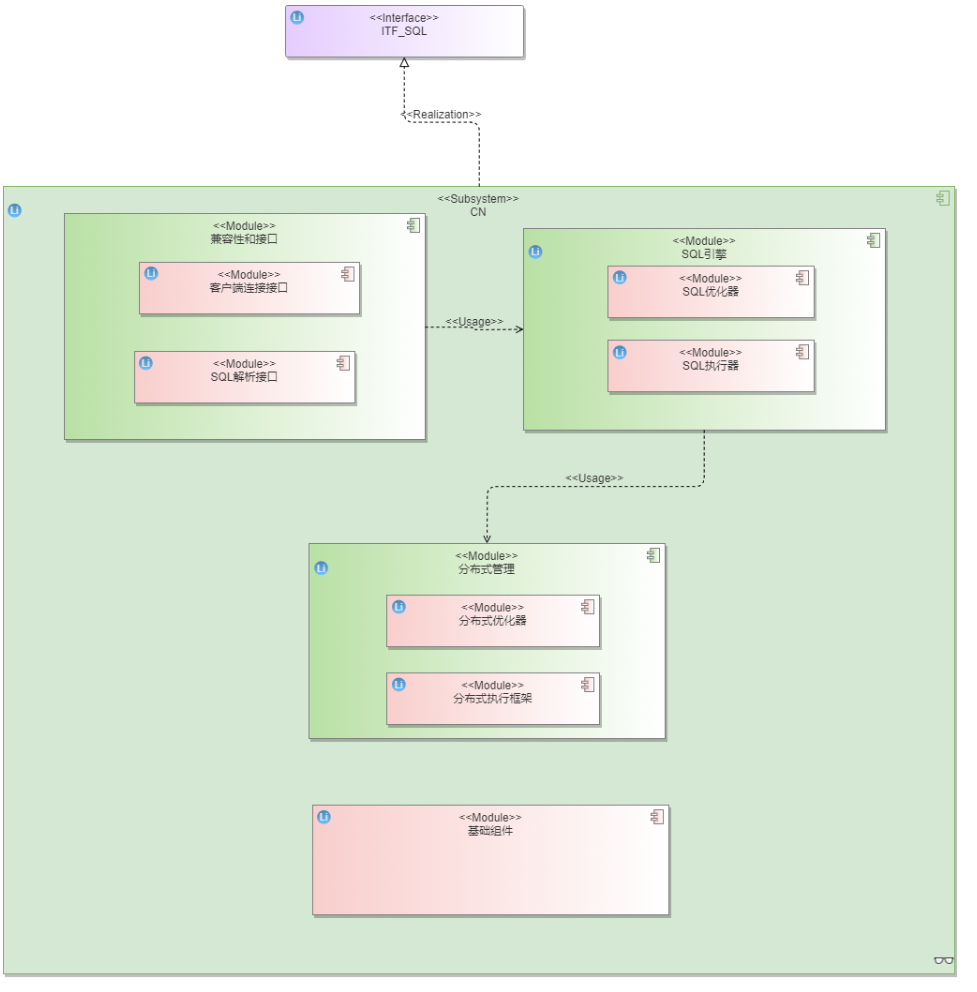
图1 Coordinator逻辑模型
-
Datanode: 数据节点存储分片数据。副本复制采用Quorum/Paxos协议。
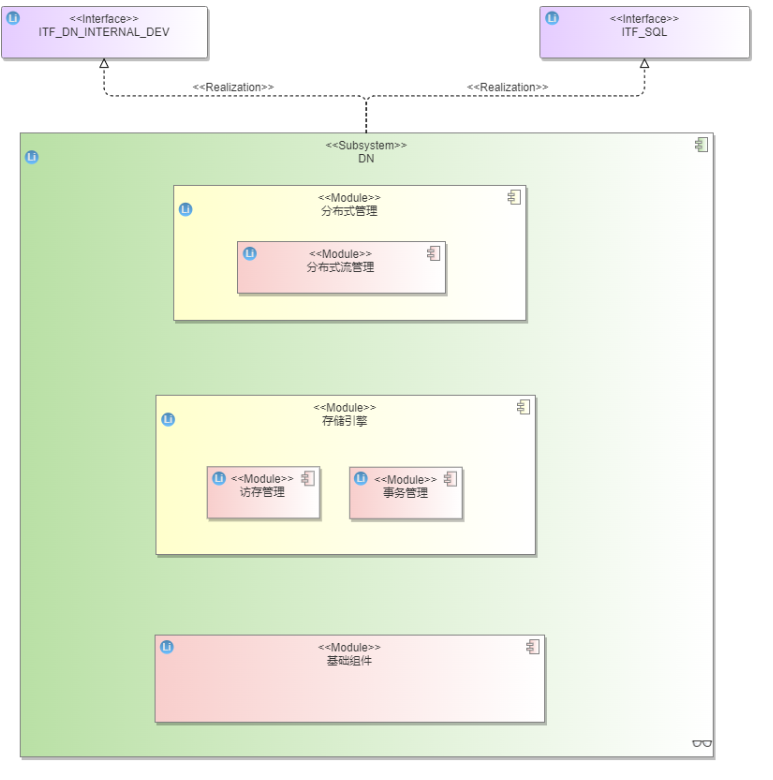
图2 DN逻辑模型
-
SECURITY: 安全子系统,主要包含了Kerberos认证,登录认证,安全审计,角色管理与访问控制,安全通信,透明数据加密,防篡改账本,全密态数据,数据脱敏等功能。

图3 安全逻辑模型
-
GTM: 全局事务管理器, 负责产生CSN号,提供全局统一快照。

图4 GTM逻辑模型
-
CM: 集群管理系统, 主要包括 CM Agent, CM Server和分布式配置中心。

图5 CM逻辑模型
-
OM运维子系统,主要包括了安装,卸载,启动,停止数据库,备份恢复,升级,扩容数据库,打补丁,节点替换, 巡检功能,故障定位定界,参数管理,初始化工具及本地客户端工具。

图6 OM逻辑模型
-
AI子系统,主要自治运维管理系统,如索引推荐、慢SQL诊断、分布键推荐;库内AI引擎;智能优化器,如智能基数估计和计划自适应选择。

图7 AI逻辑模型
-
驱动子系统,包括支持JDBC、ODBC、Python、GO等主流数据库驱动接口,适用于Java/C/C++/python/go 应用程序开发者。对于高级开发者而言,亦可采用libpq动态库接口和ecpg接口的方式,对数据库进行接入访问。

图8 驱动逻辑模型
关键模块2层逻辑模型:
存储引擎模块:

图9
SQL引擎:

图10
兼容性和接口模块:

图11
基础组件:

图12
分布式管理:
图13
3 数据计算路由层(Coordinator)关键技术方案
GaussDB Kernel V5版本的Catalog还是本地存储, 所以还需要考虑catalog的持久化问题.未来演进元数据解耦,Coordinator 无状态, 就不需要考虑Catalog持久化问题了。但是跨节点场景下的事务提交在Coordinator上还是要持久化的。

图14 Coordinator模块图
路由信息:每个表数据共分16384个hash bucket来存储,每个DN对应存储若干个hash bucket的数据。SQL优化器模块会根据Query的条件自动剪枝DN。
Pooler连接池:维护和每个DN连接的socket信息,缓存建立的连接。
3.1 分布式优化器
优化器的查询重写基础依赖于关系代数的等价变换。等价变换关系如下图所示:

图15 关系代数的等价变换
基于规则的查询重写,基本规则如下。
-
常量化简:如 SELECT * FROM t1 WHERE c1=1+1; 等价于SELECT * FROM t1 WHERE c1=2;
-
消除DISTINCT:CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT); SELECT DISTINCT(c1) FROM t1; SELECT c1 FROM t1;
-
IN谓词展开:SELECT * FROM t1 WHERE c1 IN (10,20,30); 等价于SELECT * FROM t1 WHERE c1=10 or c1=20 OR c1=30;
-
视图展开:CREATE VIEW v1 AS (SELECT * FROM t1,t2 WHERE t1.c1=t2.c2); SELECT * FROM v1; 等价于 SELECT * FROM t1,t2 WHERE t1.c1=t2.c2;
-
条件下移:t1 join t2 on … and t1.b=5 等价于 (t1 where t1.b=5) join t2
-
条件传递闭包:a=b and a=3 -> b=3
-
消除子链接:如 select * from t1 where exists(select 1 from t2 where t1.a=t2.a); 等级于 select * from t1 (semi join) (select a from t2) t2 where t1.a=t2.a;
…
查询重写规则较多,在此不一一列举。
在基于代价的查询优化技术上,主要关注三个关键问题。分别是:结果集行数估算、执行代价估算以及路径搜索。其核心目标是,为多个物理执行的代价进行评分,最后选择出一个最优的计划,输出到执行器。
行数估算方面,通过analyze手段,收集基表的统计信息,统计信息包括:各个数据表的规模、行数以及页面数等。在表中,也会统计各个列的信息,包括distinct值(该列不相同的值的个数),空值的比例,MCV(most common value,用于记录数据倾斜情况)以及直方图(用于记录数据分布情况),根据基表统计信息,估算过滤、join的中间结果统计信息。未来将基于AI进行多维度统计信息收集,收集更准确的行数信息,以辅助更优的计划选择。
执行代价估算方面,根据数据量估算不同算子的执行代价,各个执行算子的代价之和即为执行计划的总代价。算子的代价,主要包含几个方面:CPU代价、IO代价、网络代价(分布式多分片场景)等。未来需要根据物理环境的不同,调整不同算子的执行代价比例,同时通过AI技术构建更精准的代价模型。
表1 代价估算算子种类
| 算子分类 | 作用 | 主要算子 |
|---|---|---|
| 表扫描算子 | 从存储层扫描数据 | Seqscan, Indexscan |
| 连接算子 | 进行两表连接 | Hashjoin, MergeJoin, Nestloop |
| 聚集算子 | 进行聚集操作 | Hashagg, Groupagg |
| 网络传输算子 | 网络上传输数据 | Stream(redistribute, broadcast) |
| 排序算子 | 进行排序算子 | Sort |
路径搜索方面,GaussDB Kernel V5采用自底向上的路径搜索算法,对于单表访问路径,一般有两种:
-
全表扫描:对表中的数据逐个访问。
-
索引扫描:借助索引来访问表中的数据,通常需要结合谓词一起使用。
优化器首先根据表的数据量、过滤条件、和可用的索引结合代价模型来估算各种不同扫描路径的代价。例如:给定表定义CREATE TABLE t1(c1 int); 如果表中数据为1,2,3…100000000连续的整型值并且在c1列上有B+树索引,那么对于SELECT * FROM t1 WHERE c1=1; 来说,只要读取1个索引页面和1个表页面就可以获取到数据。然而对于全表扫描,需要读取1亿条数据才能获取同样的结果。在这种情况下索引扫描的路径胜出。
索引扫描并不是在所有情况下都优于全表扫描,它们的优劣取决于过滤条件能够过滤掉多少数据,通常数据库管理系统会采用B+树来建立索引,如果在选择率比较高的情况下,B+树索引会带来大量的随机I/O,这会降低索引扫描算子的访问效率。比如SELECT * FROM t1 WHERE c1>0;这条语句,索引扫描需要访问索引中的全部数据和表中的全部数据,并且带来巨量的随机I/O,而全表扫描只需要顺序的访问表中的全部数据,因此在这种情况下,全表扫描的代价更低。
多表路径生成的难点主要在于如何枚举所有的表连接顺序(Join Reorder)和连接算法(Join Algorithm)。假设有两个表t1和t2做JOIN操作,根据关系代数中的交换律原则,可以枚举的连接顺序有t1 × t2和t2 × t1两种,JOIN的物理连接算子有Hash Join、Nested Loop Join、Merge Join三种类型。这样一来,可供选择的路径有6种之多。这个数量随着表的增多会呈指数级增长,因此高效的搜索算法显得至关重要。GaussDB Kernel 通常采用自底向上的路径搜索方法,首先生成了每个表的扫描路径,这些扫描路径在执行计划的最底层(第一层),在第二层开始考虑两表连接的最优路径,即枚举计算出每两表连接的可能性,在第三层考虑三表连接的最优路径,即枚举计算出三表连接的可能性,直到最顶层为止生成全局最优的执行计划。假设有4个表做JOIN操作,它们的连接路径生成过程如下:
-
单表最优路径:依次生成{1},{2},{3},{4}单表的最优路径。
-
二表最优路径:依次生成{1 2},{1 3},{1 4},{2 3},{2 4},{3 4}的最优路径。
-
三表最优路径:依次生成{1 2 3},{1 2 4},{2 3 4},{1 3 4}的最优路径。
-
四表最优路径:生成{1 2 3 4}的最优路径即为最终路径。
多表路径问题核心为Join Order,这是NP(Nondeterministic Polynomially,非确定性多项式)类问题,在多个关系连接中找出最优路径,比较常用的算法是基于代价的动态规划算法,随着关联表个数的增多,会发生表搜索空间膨胀的问题,进而影响优化器路径选择的效率,可以采用基于代价的遗传算法等随机搜索算法来解决。
另外为了防止搜索空间过大,可以采用下列三种剪枝策略:
-
尽可能先考虑有连接条件的路径,尽量推迟笛卡尔积。
-
在搜索的过程中基于代价估算对执行路径采用LowBound剪枝,放弃一些代价较高的执行路径。
-
保留具有特殊物理属性的执行路径,例如有些执行路径的结果具有有序性的特点,这些执行路径可能在后序的优化过程中避免再次排序。
分布式执行计划生成方面,相关关键技术流程如图所示:
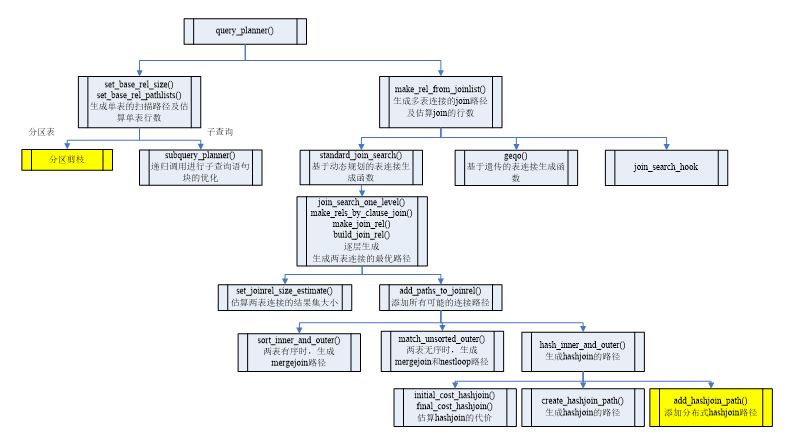
图16 分布式执行计划生成
3.2 分布式执行框架
GaussDB Kernel V5 执行框架位于SQL优化器与存储引擎之间,负责根据优化器输出的执行计划,执行数据存取以及相关的计算操作,将相关结果返回到客户端。其目标是,更好地利用各个节点的计算资源,更快地完成执行任务,并返回结果。
-
单节点执行引擎:GaussDB Kernel V5 支持行存表的行执行引擎,以及列存表向量化执行引擎,提供Adaptor算子(RowAdapter,VectorAdapter)支持行列存储的自适应切换。对于行执行引擎来说,经过逐层的算子处理,一次处理一个元组,直到再无元组为止,详细过程不在此处赘述。对于列执行引擎来说,一次处理一个batch,尽量读取更多的数据,减少IO的次数,提供高CPU的利用效率,流水线执行过程中,调用次数尽量少。

图17 行列存执行引擎自动切换
-
执行引擎主要算子:执行引擎提供算子种类如下。

图18 执行引擎主要算子
执行算子主要功能详细列表如下。
扫描算子(Scan Plan Node):扫描节点负责从底层数据来源抽取数据,数据来源可能是来自文件系统,也可能来自网络(分布式查询)。一般而言扫描节点都位于执行树的叶子节点,作为执行数的数据输入来源,典型代表SeqScan、IndexScan、SubQueryScan。
表2 扫描算子
| 算子类型 | 含义 |
|---|---|
| Seqscan | 顺序扫描行存储引擎 |
| CstoreScan | 扫描列存储引擎 |
| DfsScan | 顺序扫描HDFS存储引擎 |
| Stream | 扫描网络算子(分布式数据库特有) |
| BitmapHeapScan BitmapIndexScan | 利用bitmap获取元组 |
| TidScan | 通过Tid获取元组 |
| SubQueryScan | 子查询扫描 |
| ValueScan | 扫描Value列表 |
| CteScan | 扫描CommTableExpr |
| WorkTableScan | 扫描中间结果集 |
| FunctionScan | 函数扫描 |
| IndexScan | 索引扫描 |
| IndexOnlyScan | 直接从索引返回元组 |
| ForgeinScan | 外部表扫描 |
| StreamScan | 网络数据扫描 |
控制算子(Control Plan Node):控制算子一般不映射代数运算符,是为了执行器完成一些特殊的流程引入的算子,例如Limit、RecursiveUnion、Union
表3 控制算子
| 算子类型 | 含义 |
|---|---|
| Result | 顺序扫描行存储引擎 |
| ModifyTable | INSERT/UPDATE/DELETE操作的算子 |
| Append | 多个关系集合的追加操作 |
| MergeAppend | 多个有序关系集合的追加操作 |
| BitmapAnd | 顺序扫描HDFS存储引擎 |
| BitmapOr | 扫描网络算子(分布式数据库特有) |
| RecursiveUnion | 利用bitmap获取元组 |
物化算子(Materialize Plan Node):物化算子一般指算法要求,在做算子逻辑处理的时候,要求把下层的数据进行缓存处理,因为对于下层算子返回的数据量不可提前预知,因此需要在算法上考虑数据无法全部放置到内存的情况,例如Agg、Sort
表4 物化算子
| 算子类型 | 含义 |
|---|---|
| Materialize | 物化 |
| Sort | 对下层数据进行排序 |
| Group | 对下层已经排序的数据进行分组 |
| Agg | 对下层数据进行分组(无序) |
| Unique | 对下层数据进行去重操作 |
| Hash | 对下层数据进行缓存,存储到一个hash表里 |
| SetOp | 对下层数据进行缓存,用于处理intersect等集合操作 |
| WindowAgg | 窗口函数 |
| Limit | 处理limit子句 |
连接算子(Join Plan Node):这类算子是为了应对数据库中最常见的关联操作,Join表关联。
表5 连接算子
| 算子类型 | 含义 |
|---|---|
| Nestloop | 对下层两股数据流实现循环嵌套连接操作 |
| MergeJoin | 对下层两股排序数据流实现归并连接操作 |
| HashJoin | 对下层两股数据流实现哈希连接操作 |
-
线程池模型
每个组件 CN, DN, GTM, CMS 都是独立进程模型, 每个进程内部采用线程池模型。

图19 线程池模型
-
ThreadPoolControler:线程池总控,负责线程池的初始化和资源管理
-
ThreadSessionControler :会话生命周期管理
-
ThreadPoolGroup:线程组,可以定义灵活的线程数量和帮核策略
-
ThreadPoolListener: 监听线程,负责事件的分发和管理
-
ThreadPoolWorker: 工作线程
设计关键要点:
-
线程池根据CPU的core分成多个thread group
-
每个thread group里有一个listen thread和多个worker thread
-
listern thread负责监听一批活动连接,同时分配任务给worker thread
-
worker thread以事务维度接受任务派发来执行
本篇中,GaussDB架构从GaussDB 关键架构目标、GaussDB分布式架构、数据计算路由层(Coordinator)关键技术方案等三方面展开了介绍,下篇文章将从数据持久化存取层(DataNode)关键技术方案、全局事务管理层(GTM)关键技术方案、集群管理层(CM)关键技术方案等方面介绍GaussDB架构,敬请期待!
欢迎小伙伴们交流~
















 3165
3165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











