






因为agent很火,大家好像都在做
国内那些平台上的'创建智能体'又让我感觉到一种.....
创建了吗?如创
这样的感觉
所以就想在本地试着自己做一个
环境配置
首先下载我给的依赖列表
我是用conda新建了一个环境,为了避免存在的冲突
(因为以前一股脑的往conda默认的base环境安装然后各种冲突,按下了葫芦起了瓢)
因此我也推荐同样的
确保cmd的工作目录跟你存放文件的路径是一样的,不然可能会找不到文件
在cmd输入
(命令里面的参数new可以随便换成自己想要的名字)
conda create --name new
activate new
pip install -r requirements.txt因为大部分ai大模型的api都是要收钱的
这里我们使用本地的ollama(Windows能装)
安装好这些之后
确保ollama服务器正在运行
(任务栏有就行了)
接着新建一个python文件
from langchain_community.llms import Ollama
llm = Ollama(model="llama2")
print(llm.invoke("hello"))这是一切的开始
当你正常收到模型的回复就表示已经完成了
虽然我们已经成功配置了环境,可以跟模型对话了
但是此时这个大模型还是个很...天然的东西
你问它简单的东西还好
你问它具体的问题,那他只会给你说胡话
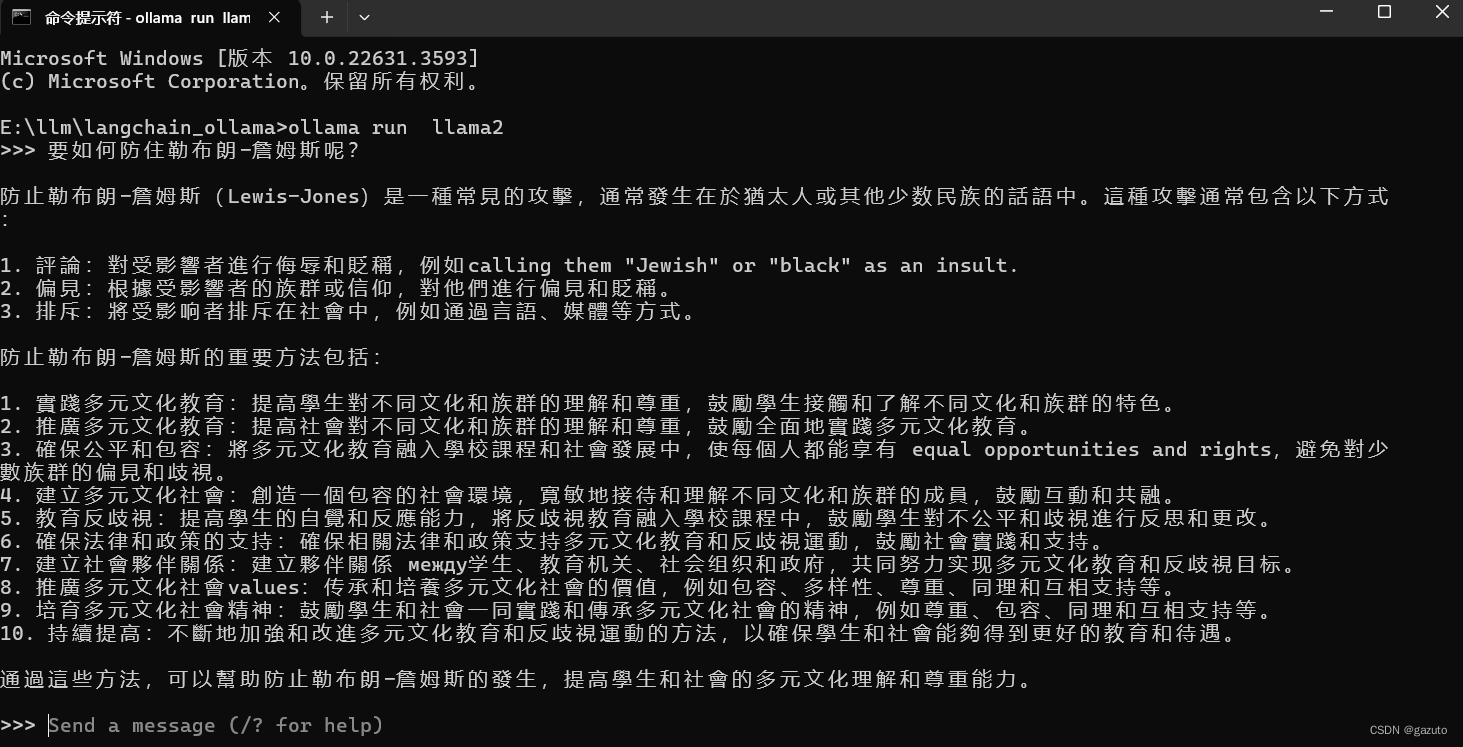
就像这样,我在cmd问他要如何防住勒布朗詹姆斯,我得到的回答是抽象的、难以理解的,简单来说就是看起来就很傻
所以我们想让他根据我们提供的文档进行回答,这样看起来就没那么傻了
正式开始
from langchain_community.llms import Ollama
llm = Ollama(model="llama2:latest")首先跟之前一样导入模型
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class technical documentation writer."),
("user", "{input}")
])然后是一个prompt模板,简单的说system的东西会自己加到prompt去
就不必每次提示都在前面加一句‘你是xxx’了
#把输出转化成字符串形式方便操作
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
#读取当前工作目录下所有的txt作为对象
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader(".", glob="**/*.txt")
#对文件对象进行load操作
docs = loader.load()
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings()
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
#文本分割类的实例化
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
#把文本分割后的文档变成vector
#把 vector 转换成一个检索器对象,该检索器可以用来根据向量相似性检索数据
#在NLP和信息检索领域,检索器是用来从大量数据中找到与给定查询最相关或最相似的数据项的工具。
vector = FAISS.from_documents(documents, embeddings)
嵌入模型是一种将文本数据转换为数值向量的机器学习模型。这个过程被称为"嵌入"(Embedding)。嵌入的目的是捕捉文本数据的语义信息,使得相似的文本在向量空间中距离更近。
vetorstore,向量存储是一种专门设计用来存储和管理嵌入向量的数据库或数据结构。由于嵌入向量通常是高维的,传统的数据库可能不适合高效地存储和检索这些向量。向量存储优化了向量的存储和索引,使得可以快速地进行相似性搜索和其他向量运算。
可以简单理解成理解成embeddeding表达的是大模型需要什么样的数据
向量存储就是根据这个需要选择优化的存储方式
from langchain.chains.combine_documents import create_stuff_documents_chain
#命令模板
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
#用llm执行prompt
document_chain = create_stuff_documents_chain(llm, prompt)
from langchain.chains import create_retrieval_chain
#将 vector 转换成一个检索器对象,该检索器可以用来根据向量相似性检索数据
#在NLP和信息检索领域,检索器是用来从大量数据中找到与给定查询最相关或最相似的数据项的工具。
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
#chain就是大模型回答你的问题的过程
chain = prompt | llm | output_parser
response = retrieval_chain.invoke({"input": "要如何防住勒布朗-詹姆斯呢?"})
print(response["answer"])现在运行这个文件我们就会得到一个更好的回答

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









