







 本文是365天深度学习训练营的一篇学习记录,主要介绍了利用TensorFlow进行GPU设置,数据预处理,构建卷积神经网络模型进行明星图像识别的步骤。在训练过程中,作者发现模型存在过拟合问题,并计划进行参数调整优化。
本文是365天深度学习训练营的一篇学习记录,主要介绍了利用TensorFlow进行GPU设置,数据预处理,构建卷积神经网络模型进行明星图像识别的步骤。在训练过程中,作者发现模型存在过拟合问题,并计划进行参数调整优化。
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/xLjALoOD8HPZcH563En8bQ) 中的学习记录博客**
>- ** 参考文章:365天深度学习训练营-第5周:运动鞋品牌识别(训练营内部成员可读)**
>- **🍖 原作者:[K同学啊](https://mp.weixin.qq.com/s/xLjALoOD8HPZcH563En8bQ)**
1.实验准备
设置GPU:
import tensorflow as tf
gpus=tf.config.list_physical_devices("GPU")
if gpus:
gpus0=gpus[0]
tf.config.experimental.set_memory_growth(gpu0,True)
tf.config.set_visible_devices([gpus0],"GPUS")设置数据路径
data_dir="./48-data/48-data/"
data_dir=pathlib.Path(data_dir)
image_count=len(list(data_dir.glob('*/*.jpg')))
print("图片总数:",image_count)数据探索
roses=list(data_dir.glob('Jennifer Lawrence/*.jpg'))
PIL.Image.open(str(roses[0]))
设置训练参数
batch_size=32
img_height=224
img_width=224
#加载训练集到tensorflow中
train_ds=tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="training",
label_mode="categorical",
seed=123,
image_size=(img_height,img_width),
batch_size=batch_size
)
#加载验证集集到tensorflow中
val_ds=tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="validation",
label_mode="categorical",
seed=123,
image_size=(img_height,img_width),
batch_size=batch_size
)打印标签类别
class_names=train_ds.class_names
print(class_names)
['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
可视化视图
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
for images,labels in train_ds.take(1):
for i in range(20):
ax=plt.subplot(5,10,i+1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")检查输入数据形状
for image_batch,labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break打乱数据和设置加速
AUTOTUNE=tf.data.AUTOTUNE
train_ds=train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds=val_ds.cache().prefetch(buffer_size=AUTOTUNE)2.模型训练
设置模型
model=models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255,input_shape=(img_height,img_width,3)),
layers.Conv2D(16,(3,3),activation='relu',input_shape=(img_height,img_width,3)),
layers.AveragePooling2D((2,2)),
layers.Conv2D(32,(3,3),activation='relu'),
layers.AveragePooling2D((2,2)),
layers.Dropout(0.5),
layers.Conv2D(64,(3,3),activation='relu'),
layers.AveragePooling2D((2,2)),
layers.Dropout(0.5),
layers.Conv2D(64,(3,3),activation='relu'),
layers.Dropout(0.5),
layers.Flatten(),
layers.Dense(128,activation='relu'),
layers.Dense(len(class_names))
])
model.summary()设置训练参数
#设置训练参数
init_learing_rate=1e-4
lr_schedule=tf.keras.optimizers.schedules.ExponentialDecay(
init_learing_rate,
decay_rate=0.96,
decay_steps=60,
staircase=True
)
optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
#设置训练批次和模型停止训练等参数
from tensorflow.keras.callbacks import ModelCheckpoint,EarlyStopping
epochs=100
checkpointer=ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
earlystopper=EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1
)开始训练
history=model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer,earlystopper]) 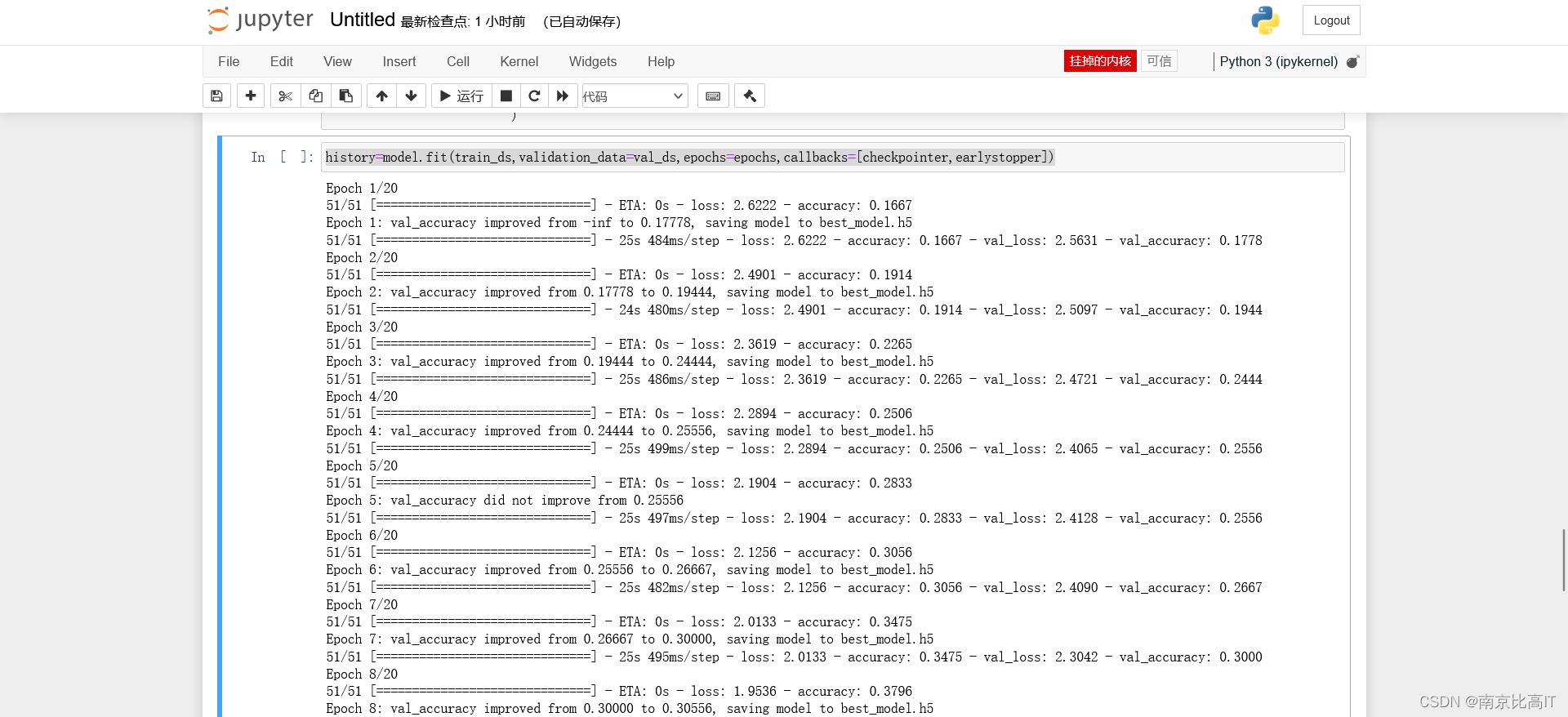
可视化训练结果
acc=history.history['accuracy']
val_acc=history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_accuracy']
epochs=range(len(loss))
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(epochs,acc,label='Training Accuracy')
plt.plot(epochs,val_acc,label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(1,2,3)
plt.plot(epochs,loss,label='Training Loss')
plt.plot(epochs,val_loss,label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show() 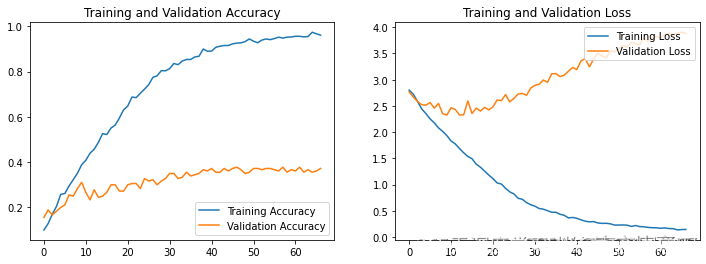
使用保存下来最好的模型进行预测
model.load_weight('best_model.h5')
from PIL import Image
import numpy as np
img=Image.open('./48-data/48-data/Jennifer Lawrence/003_963a3627.jpg')
image=tf.image.resize(img.[img_height,img_width])
img_array=tf.expend_dims(image,0)
predictions=model.predict(img_array)
print("预测结果为: ",class_names[np.argmax(predictions)]) ![]()
3.实验总结
通过本周的明星识别,深度学习是有趣的,但是我的实验还是有不足,也欢迎大家进行指正,我的模型出现了过拟合的现象,这是因为我没有进行参数调整,我回去寻找原因调整相关的参数,加油!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











