







 本文介绍了一种结合PaddleOCR文字识别与ToolGood.Words敏感词检测的方法,通过识别图片中的文字内容并检测其中可能存在的敏感词汇,最终用红框标记含有敏感词的区域。
本文介绍了一种结合PaddleOCR文字识别与ToolGood.Words敏感词检测的方法,通过识别图片中的文字内容并检测其中可能存在的敏感词汇,最终用红框标记含有敏感词的区域。
《测试.net开源敏感词检测库ToolGood.Words》介绍了基于ToolGood.Words实现敏感词检测的基本用法,而之前学习过使用PaddleOCR测试图片文字识别,于是想结合这两者实现基本的从图片中检测敏感词并用红框标识的功能。
代码实现逻辑比较简单:
第一步先调用PaddleOCR进行图片文字识别并记录识别出的文字区域,PaddleOcrAll类的识别结果返回类型PaddleOcrResultRegion的集合,其中记录有识别出的文字内容及位置信息,为后续敏感词检测做输入;
第二步逐区域检测敏感词,如果存在敏感词则记录其所属区域,最后用红框将所有含敏感词的文字区域标识出来。
程序的主要代码如下所示:
//记录检测的敏感词及其关联的图片区域
private class MatchedRegion
{
public PaddleOcrResultRegion Region;
public WordsSearchResult Result;
}
//图片文字识别
OCRModel model = KnownOCRModel.PPOcrV2;
model.EnsureAll();
byte[] sampleImageData;
using(MemoryStream ms = new MemoryStream())
{
picSrcImage.Image.Save(ms, System.Drawing.Imaging.ImageFormat.Jpeg);
sampleImageData = ms.ToArray();
}
using (PaddleOcrAll all = new PaddleOcrAll(model.RootDirectory, model.KeyPath)
{
AllowRotateDetection = true, // 允许识别有角度的文字
Enable180Classification = false, // 允许识别旋转角度大于90度的文字
})
using (Mat src = Cv2.ImDecode(sampleImageData, ImreadModes.Color))
{
PaddleOcrResult result = all.Run(src);
using(Graphics g =Graphics.FromImage(picSrcImage.Image))
{
Pen pThick = new Pen(Brushes.LightBlue, 5);
foreach (PaddleOcrResultRegion region in result.Regions)
{
Point2f[] ps = region.Rect.Points();
int i = 0;
for (; i < ps.Length - 1; i++)
{
g.DrawLine(pThick, ps[i].X, ps[i].Y, ps[i + 1].X, ps[i + 1].Y);
}
g.DrawLine(pThick, ps[i].X, ps[i].Y, ps[0].X, ps[0].Y);
m_regions.Add(region);
}
pThick.Dispose();
}
picSrcImage.Invalidate();
}
//逐区域检测敏感词
WordsSearch ws = new WordsSearch();
ws.SetKeywords(txtResearchWord.Text.Split(';', ';'));
foreach (PaddleOcrResultRegion region in m_regions)
{
List<WordsSearchResult> results = ws.FindAll(region.Text);
foreach(WordsSearchResult result in results)
{
MatchedRegion mr = new MatchedRegion();
mr.Result = result;
mr.Region = region;
m_matchedRegions.Add(mr);
}
}
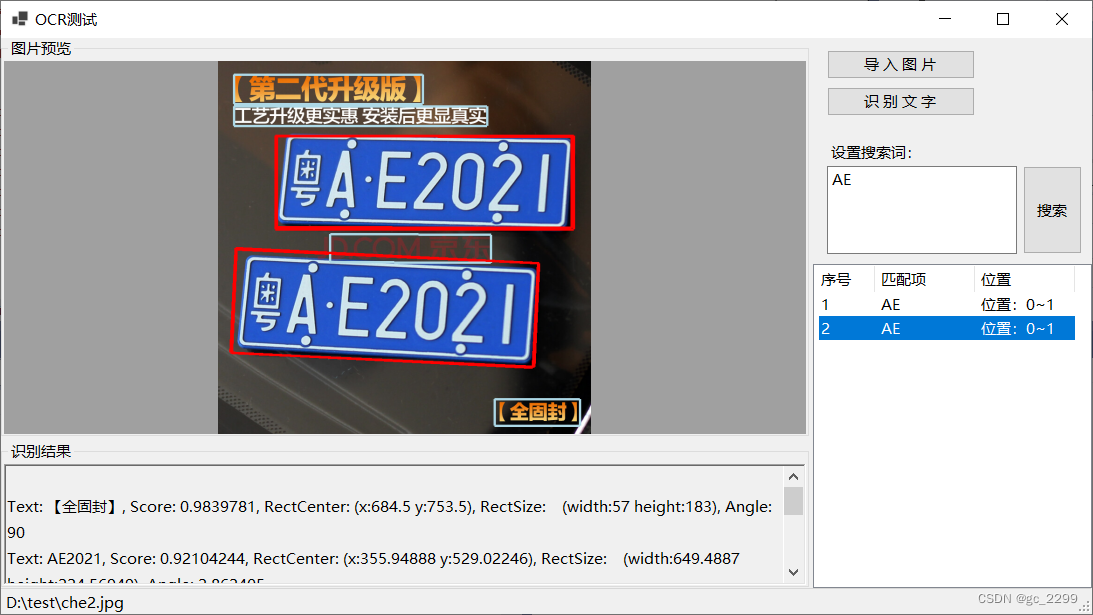
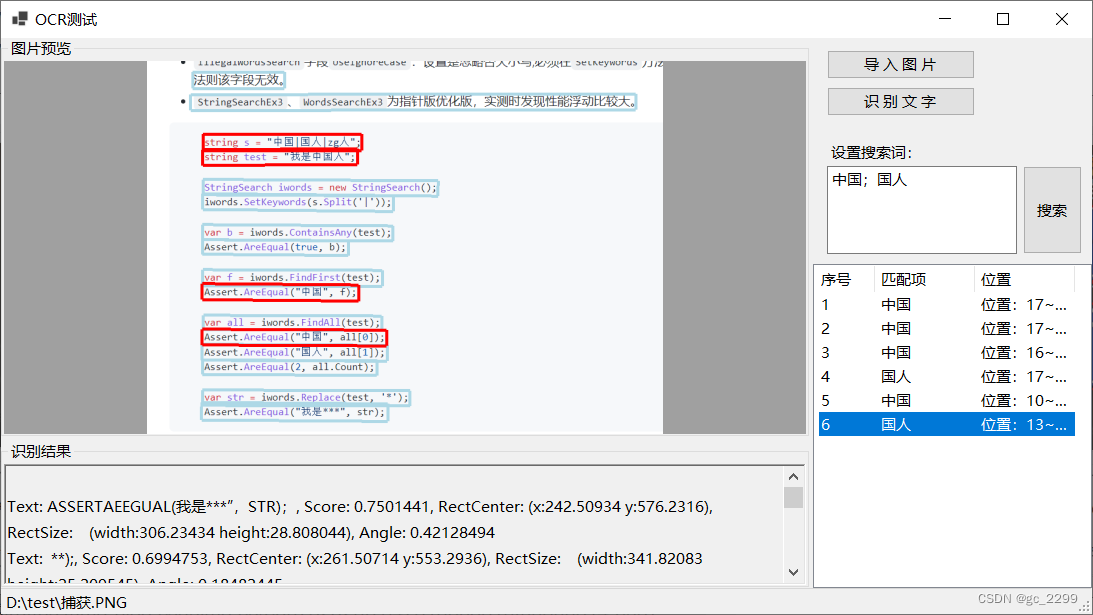
使用车牌截图及文本截图进行测试,效果如下所示,此时程序的关键变成了图片文字识别的准确率,如果准确率不高,则后续的敏感词检测也无从谈起。
参考文献:
[1]

















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









