









@(机器学习和人工智能)[机器学习, CNN]
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition
- History:
- 1960s:recognize & reconstruct
- object recognition is so hard
⇒
first we do object segmetation
- feature based segmetation:
- SVM, boosting: complex;overfit(data quailty is changing)
- 两个最经典的data set:
- PASCAL Visual Object Challenge(object detection benchmark )
- ImageNet Large Scale Visual Recognition Challenge
- CNN基本算法在1998年由LeCun等提出,2012年在ImgeNet上大显身手火了起来,再次火起来原因:电路集成规模越来越大,GPU的快速发展,data的质量和数量爆炸式增长。
- 学习CNN的预备知识:微积分,线性代数,CS229


Lecture 2 | Image Classification
- Data Driven Approach
- Collect a dataset of images and labels
- Use Machine Learining to train a classifier
- Evaluate the classifier on new images
k-Nearest Neighbors(kNN)
- 在最近的k个邻居中,哪一类个数最多,就归为哪一类
- hyperparameters: choices about the algorithm that we set rather than learn
how to set proper hyperparameters: split dataset into train, validation and test set
- train set(most data)
- validation set: envaluate
- test set: test once
- k-Nearest Neighbors on imgages never used

Linear Classification
- super important and help us build CNNs
- parametric approach: image(array of numbers)
→
f(x,W)
(score function)
→
10 numbers giving class scores
- x : input
W : weight or parameters-
b
: bias
假设有10类,则最终得到10行1列的列向量,其中每个数字代表了是该类的可能性,数字越大可能性越大。
- 举例说明,下面是对于一个给定的
W ,4个像素的image,分为3类的计算过程:
训练结果的可视化:
- Linear Classification可以理解为平面上的直线,各分类器将平面上的不同区域分为不同类别:
所以有一些线性不可分问题,一层线性分类器是解决不了的,因为在平面上无法用一条直线将两类分开,如异或,或下图中的例子。





Lecture 3 | Loss Functions and Optimization
- loss funciton: quantify how good/bad our current classifier is given a dataset
{(xi,yi)}Ni=1
, where
xi
is image and
yi
is (integer) label.
- L=1N∑iLi(f(xi,W),yi)
- Multiclass SVM loss:
si=f(xi,W)
Li=∑j≠yimax(0,si−sj+1)


若s都很小,约等于0,则loss等于类别数量减一,可以用来debug。
4. Loss等于0的W不只一个,比如2W。
5. 不应该关注training data上的performance,而关注testing data上的。
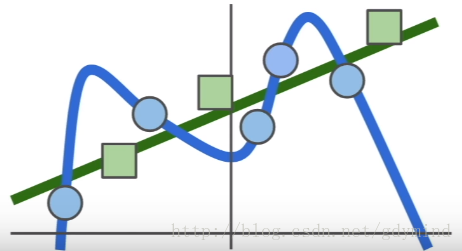

回归项使其倾向于选择一个更简单的
W
<script type="math/tex" id="MathJax-Element-393">W</script>。
6. 常见regularizaton:举例
















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









