






paper:link
代码:https://github.com/OlaWod/FreeVC
demo: https://olawod.github.io/FreeVC-demo
体验网址:FreeVC - a Hugging Face Space by kevinwang676

注:ChatGLM生成的慢,可以直接编辑文本生成声音,只体验声音的部分
 csdn不好上传音频文件,亲测声音克隆出来的声音在自然度上已经很不错了,内容保持的很好,音色还有改进的空间,相对于SV2TTS算法已经有太明显的进步了。
csdn不好上传音频文件,亲测声音克隆出来的声音在自然度上已经很不错了,内容保持的很好,音色还有改进的空间,相对于SV2TTS算法已经有太明显的进步了。
Abstruct
VoiceConversion(VC)可以实现提取源声音的内容和目标声音的音色,然后重建具有目标音色声音和源声音内容。然而,当前的算法存在的问题是,要么会提取脏信息,要么需要大量的标注数据。VC模型和声码器模型(vocoder)之间的不匹配会降低重建的质量。在这篇论文里,作者采用了VITS端到端的高质量波形重建,并且提出了一种不需要文本标注的干净的信息提取方案,作者通过对WavLM特征施加一个information bottleneck的方式分离声音的内容信息,并且提出了一个spectrogram-resize(频谱图Resize)的数据增强方法,提高提取声音内容信息纯度的方法。实验证明,本文提出的方法优于最新使用标注数据训练的VC模型,并且有很强的鲁棒性。
1.Introduction
VoiceConversion(VC)是一种在保证语言内容不变的情况下,修改源语音到目标风格的一种技术,比如说话人识别,韵律,情绪等等。这篇文章聚焦在一个样本(one-shot)的前提下的说话人声音转换,只使用目标speaker的一条语音。
典型的one-shot方法是分别分离源语音和目标语音的中的内容信息和speaker信息,然后利用这些信息重构声音。因此,转换的结果依赖,1:VC模型分离信息的能力;2:VC模型重建的能力。
根据VC系统分离内容信息的方法,可以将现有的VC方法分为:text-base和text-free两类。主流的text-base的方法,一般采用自动的语音识别(automatic speech recognition ASR)提取语音后验概率(PPG)作为特征表达,一些研究人员还决心利用文本到语音(TTS)模型中的共享语言知识,但是这类方法需要大量的标注数据,训练ASR和TTS模型。数据标注成本高昂,标注的准确性和粒度(例如音素级别和字形级别)会影响模型性能。为了避免这些问题,text-free的方法如information bottleneck,vector quantization,instance normalization等,但是text-free的方法性能弱于text-base的方法。可以解释为这些方法提取的content information容易包含speaker information。
很多VC系统采用two-stage的重建流程。1.VC 模型把源语音的声学特征转换到目标speaker的声音;2.声码器把VC的特征转换为声音的波形。但是,两阶段的模型往往是分开训练的,VC模型预测的声学特征跟声码器模型的分布并不一致,这种特征的不匹配,会降低重建声音波形的质量。VITS是一个一阶段的模型,能干TTS和VC两个任务,通过conditional variational autoencoder(CVAE) 的潜在变量连接两个模型,降低两阶段模型特征不匹配的问题。通过对抗训练,进一步提高重建波形的质量。但是VITS是一个text-base的模型,无法实现many-to-many问题的模型是一个局限。
在本文中,我们提出了一个text-free 的one-shot Free-VC方法,使用了VITS优秀的重建能力,但是使用了无text标注的分离content information学习的方式。
最近自监督学习SSL在语音下游任务(语音识别,语音验证,语音转换)的成功表明SSL特征的潜力强于传统的声学特征(比如mel频谱)。作者使用了WavLM提取SSL特征,并且引入了一个bottleneck提取器,从SSL特征中提取内容信息。作者还提出了基于spectrogram-resize (SR) 的数据增强方法,打乱speaker information并且不改变content information,增强了模型分离两种信息的能力。为了实现one-shot的能力,作者使用speaker-encoder提取speaker information。代码和demo都是公开的。
2.Methods
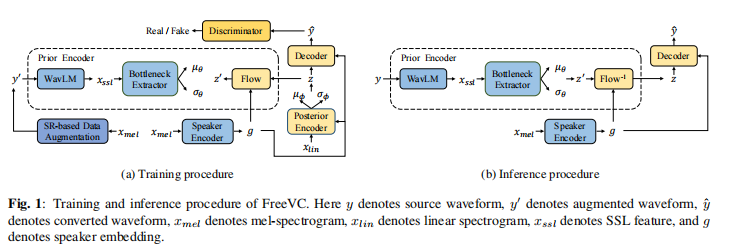
如fig1所示,FreeVC的backbone继承的VITS(用GAN的训练方式增强CAVE);与VITS不同的是,prior encoder使用原始的波形作为输入,替代了文本标注,并且结构也不同。用speaker-encoder是为了实现one-shot的能力。另外,FreeVC使用了不同的训练策略和推理程序。
2.1 模型架构
FreeVC 包含 a prior encoder, a posterior encoder, a decoder, a discriminator and a speaker encoder, 其中posterior encoder, decoder and discriminator跟 VITS相同. 主要介绍 prior encoder和 speaker encoder
2.1.1 prior encoder

prior encoder 包含WavLM模型, bottleneck extractor 和 normalizing flow. 其中WavLM模型和 bottleneck extractor 负责提取内容信息(以高斯分布的形式)。其中WavLM模型的输入是原始的声音波形,提取1024维的SSL特征(包含content信息和speaker信息)。为了去掉不需要的speaker信息,这1024维的特征输入到Bottleneck提取器,转换成d-维的特征,d远远小于1024,这个大的维度gap形成信息bottleneck,强迫低维的特征表达丢弃内容无关的信息(噪声和speaker信息);接下来,这个d维的隐式表达被投影到成2d维的隐式表达,分成d维的均值和d维的均方差。归一化Flow是为了增加先验分布的复杂度,根据VITS,Flow是有多个耦合仿射层组成的,并且用雅可比形式保存体积为1.
2.1.2 Speaker Encoder
作者使用了两种speaker encoder:预训练的encoder和非预训练的encoder,预训练的speaker encoder是在有大量speaker的数据集上训练的speaker识别模型。预训练的speaker encoder大量使用,并且广泛认为比非预训练的效果好。非预训练的speaker encoder跟其他的模型一起从头训练。作者使用了简单的LSTM-base的架构,作者相信,如果提取的content信息足够clean,speaker encoder会学会建模丢失的speaker information。
2.2 训练策略
2.2.1 SR-based Data Augmentation

太窄的Bottleneck会丢失内容信息,太宽的Bottleneck包含无关的speaker information,相对于仔细的调参,作者使用SR-base的数据增强打乱speaker information帮助模型提取干净的content information。不像其他的工作那样使用复杂的信号处理知识削弱speaker information,作者的方法易于实现。
作者的SR-base 数据增强包含三步:
1.提取声音信号的mel谱
2.对mel谱进行垂直方向的SR增强,生成修改后的mel谱
3.使用声码器对修改后的mel谱进行声音信号的重建、
mel谱可以看做水平轴是时间,垂直轴是各频率分量的值。垂直SR增强先对mel谱使用三线性差值进行比例为r的缩放,然后pad或者cut保证shape与之前相同。如果r小于1,则pad顶端的高频部分,padding的值为最高的频率分量和高斯噪声的和,从而产生音调更低、共振峰距离更近的语音。反正,cut掉顶部频率最高的mel谱,从而产生具有更高音高和更远共振峰距离的语音。通过增强后的数据,模型能更好的学习每个r共享的不变的content信息。另外,对于垂直SR增强,一样可以使用水平SR增强生成时间尺度上修改的声音波形。
2.2.2 Training Loss
训练loss分为CAVE相关的loss和GAN相关的loss。CAVE相关的重建loss,是目标和预测mel谱的L1距离;KLloss是先验分布和后验分布的KL差异
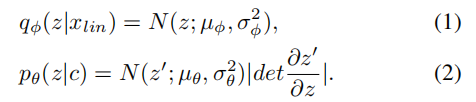
条件变量c是指包含的目标和预测中的content信息比值,通过最小化KL loss可以减少特征不匹配的问题。GAN相关的loss包括生成损失和判别损失,以及特征不匹配损失,最终的损失如下:
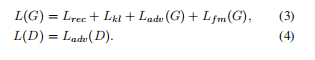
2.3 Inference Procedure
VITS通过后验encoder 提取content信息,在推理中使用先验encoder归一化;与不同的是,FreeVC使用WavNet和Bottleneck在先验encoder阶段提取contect信息(推理和训练相同),这样提取的content表达不会受源speaker embedding的影响。
3.Experiments
3.1Experimental Setups
作者使用VCTK的语料训练,用VCTK和LibriTTS测试。音频都是使用16khz,d维为192,对于SR增强,r从0.85-1.15;使用HiFI-GAN v1的声码器,作者的模型在3090上训练900k步,batchsize是64,最大分段的长度是128帧。
主要跟VQMIVC,BENG-PPG-VC,YourTTS对比,并且作者提出了三个版本:
FreeVC-s:未使用预训练的speaker-encoder
FreeVC : 预训练的speaker-encoder
FreeVC(w/o SR): 预训练的speaker-encoder,但是没有用SR增强
3.2 Evaluation Metrics
作者构建了主客观两个评价指标。主观评价是邀请了15个人,按照五分制,对自然性(MOS)和相似度(SMOS)进行评价。
对于客观评价,使用 ASR模型测试Word error rate (WER)和 character error rate (CER) . F0-PCC(Pearson correlation coeffificient)作为测试指标
3.3 结果分析
3.3.1 Speech Naturalness and Speaker Similarity自然性和相似度
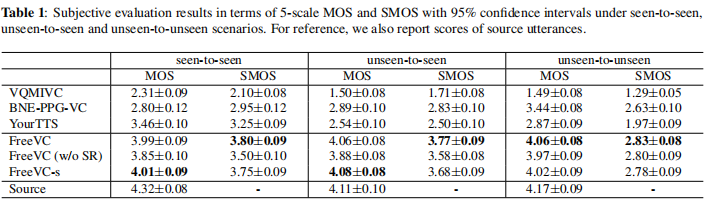
结果可以看出,提出的方法胜过了其他的baseline模型。
并且作者观察发现当录音质量差或者发音不清时,其他模型的表现会受到严重影响,但是FreeVc几乎不受影响,证明了提出模型的鲁棒性。
FreeVC(w/o SR)的效果最差,说明SR-base的数据增强确实有助于提取干净的content信息。
FreeVC-s和FreeVC各有优劣,说明预训练speak-encoder并不是关键因素
FreeVC在unseen-to-unseen的表现,说明大量speaker数据集上训练的模型在unseen的数据上有更强的泛化性。
3.3.2 Speech Intelligence and F0 Variation Consistency
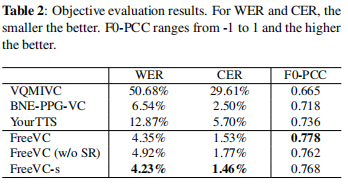
低的WER和CER证明作者提出的方法能有效的保留源语音的语义内容,高的F0证明FreeCV与源语音有更高的一致性,并且能有效的保留源语音韵律。另外,SR-base的数据增强对语义和F0均有提升。
4.Conclusion
作者提出了FreeVC,是一个text-free one-shotVC系统,采用了VITS的高质量声音重构框架,使用BottleNeck从WavNet提取的特征中提取Content信息。另外作者提出了基于SR的数据增强技术,提高了模型分解speaker信息和content信息的能力,实验证明了提出方法的先进行。
5.在线体验测评结果
体验网址:FreeVC - a Hugging Face Space by kevinwang676
近期会调研对比近两年其他的声音克隆工作,立此贴为证!
小白新入语音领域,有不对支持请多多指出。

















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









