







1. 首先我对前面几个章节做了一个总体概述如下:
其实我们前面论述的那些函数,无非可以总结成两种模式:
1)
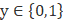 y
取
0
或者
1
,在这种情况下,最为自然的
0~1
之间的分布是伯努利分布,对于这种情况我们得到了逻辑回归;
y
取
0
或者
1
,在这种情况下,最为自然的
0~1
之间的分布是伯努利分布,对于这种情况我们得到了逻辑回归;
3) 若你忘记了Bernoulli分布,这里给您做个提醒,若已经熟练掌握请忽略,伯努利分布的概率分布是:
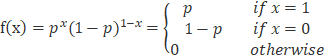
2. 假设我们有一组只能取0和1的数据,我们希望使用伯努利分布对其建模,变量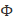
a) 对于伯努利分布: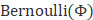
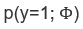
b) 同理我们考虑高斯分布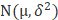
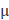
总结:以上两个分布其实是一类分布的特例,这类分布被称为指数族分布。相关资料引入如下:

c) 特别地,我们说一类概率分布,比如说改变
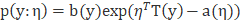
 被称为分布的自然参数;
被称为分布的自然参数;
d) 选定一种函数的形式,对于a,b和T我们固定了3个函数那么这个公式就定义了一个函数分布的集合,对于一组给定的a,b,T,当我们改变
我会得到不同的概率分布。
e) 接下来展示下伯努利分布和高斯分布都是指数族分布的特征,这意味着我们通过特定形式的a,b,T使这个公式变成伯努利或者高斯分布的形式,
当我们改变的值,我会得到均值不同的伯努利分布或者说当我改变 时,我会得到均值不同的高斯分布,对于给定的a,b,T,T(y)其实是一个概率分布。
f) 最后补充一点,在很多情况下T(y)=y,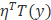
例子会是一个例外。
4.现在我将向你展示伯努利分布和高斯分布都是指数族分布的特例:
1) 对于Bernoulli分布而言,我们的推演过程如下:
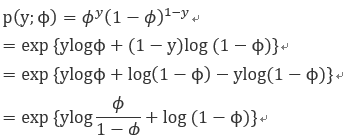
2)我们将结果类比指数族分布,则能得到这样的结论:
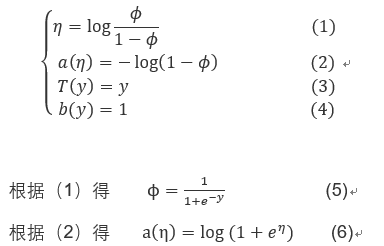
我们惊奇的发现式子(5)实际上就是我们在逻辑回归中使用的logisticsigmoid函数。
3) 对于高斯分布而言:
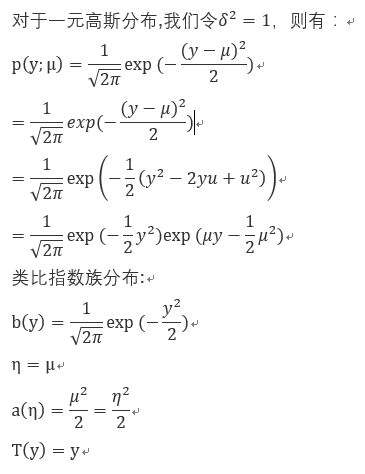
3)我们再举一个例子,证明多项式分布本质上也是指数族分布:
在这之前我们先补充一点额外的知识,那就是指示函数,这对于我们推导多项式分布是指数族分布的特例具有重要意义:
我们用1来表示指示函数,之后用大括号内表示函数的参数,若指示函数的参数是真的,则返回1;若指示函数的参数是假的,
则返回0,其表述形式如下:
1{true} = 1
1{false} = 0
因此有实例:
1{1=3} = 0
1{1+1=2} = 1
4) 设置多项式分布有k个参数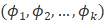
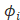
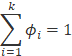
则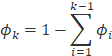
设置多项式分布有k个参数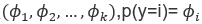
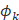
5)同时我们引入以下向量:
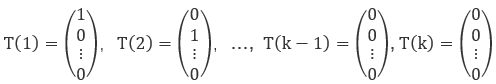
我们可以将上面的向量表示为: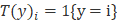
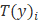
6) 有了指示函数,我们就可以将多项式分布用指示函数进行表示:

5. 广义线性回归算法(GLM):
1) 给定特征属性x和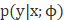
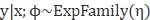
2) 预测对应指数族分布中T(y)的期望,即计算E(T(y)|x)
3)指数族分布中的 
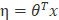
根据以上3个假设条件,我们将导出广义线性模型,并且得到非常漂亮的算法用来拟合模型。
对于第(3)个假定条件,如果
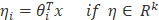
例如:对于任意给定的x和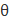
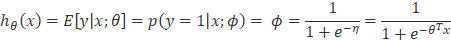
也就是说:当我们进行机器学习算法时,若随机变量只能取0,1两个值,然后你会选择伯努利分布对其进行建模。注意
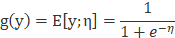

6. 多项分布使用广义线性回归的拟合过程:
我们假设机器学习中y可以取k个值(
邮件保存在正确的邮件目录中,如果你有10几个邮件目录,你希望你的算法能够将这些邮件分入到这些目录中;再例如,我们知
道病人生病或者没生病这是一个Bernoulli分布,但是如果你认为有可能患有k种病,希望你设计一个算法来帮助医生确定病人到底
得了那种病,当分类问题中的分类超过两种,此时你应该选择多项式分布进行建模:
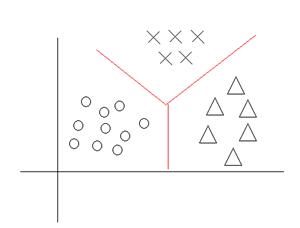
1. 现在我们开始利用广义线性回归对多项式分布进行拟合:
由(7)我们可以推出:

所以我们T(y)的数据期望为:
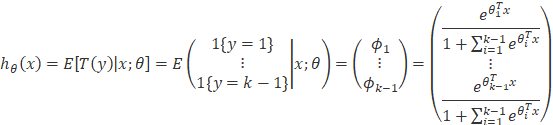
这就是softmax模型,有了上面的基础,我们就可以进行如下总结:
假设你有一个机器学习问题y可能属于k类中的1类,会选择多项分布作为指数分布,接下来要处理集合:

我们通过使用极大似然估计算法有:
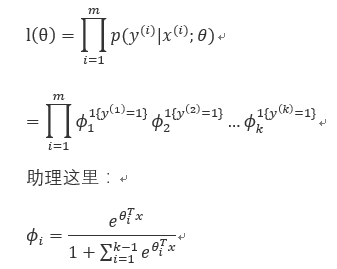
后面的计算比较简单,这里不做详细叙述,引入为主。















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









