







概述
朴素贝叶斯(Naive Bayes)法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,
(1)首先基于特征条件独立假设学习输入输出的联合概率分布。
(2)然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
基本方法

朴素贝叶斯法通过训练数据集学习联合概率分布P(X, Y)。
- 先验概率分布(公式1)
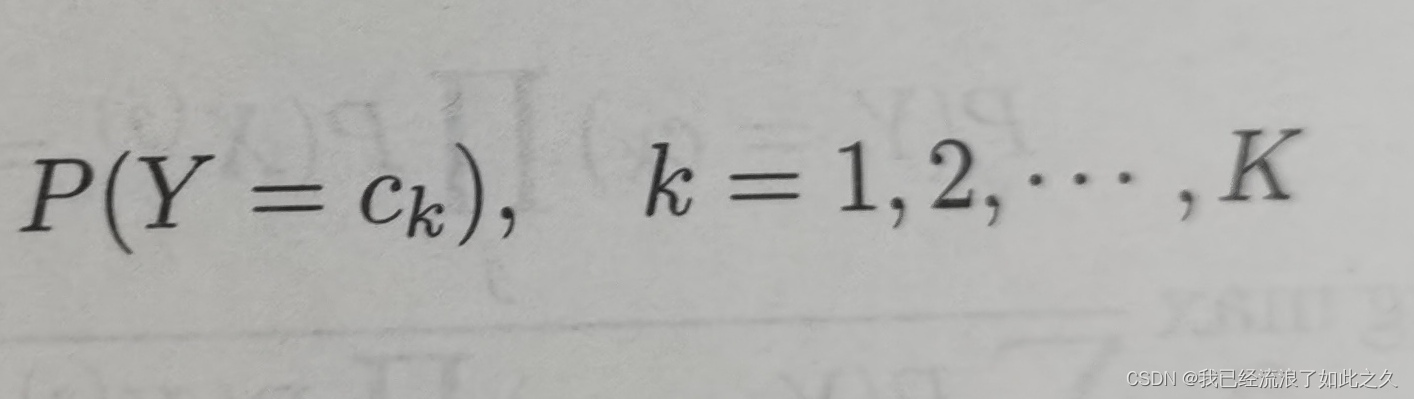
- 条件概率分布(公式2)
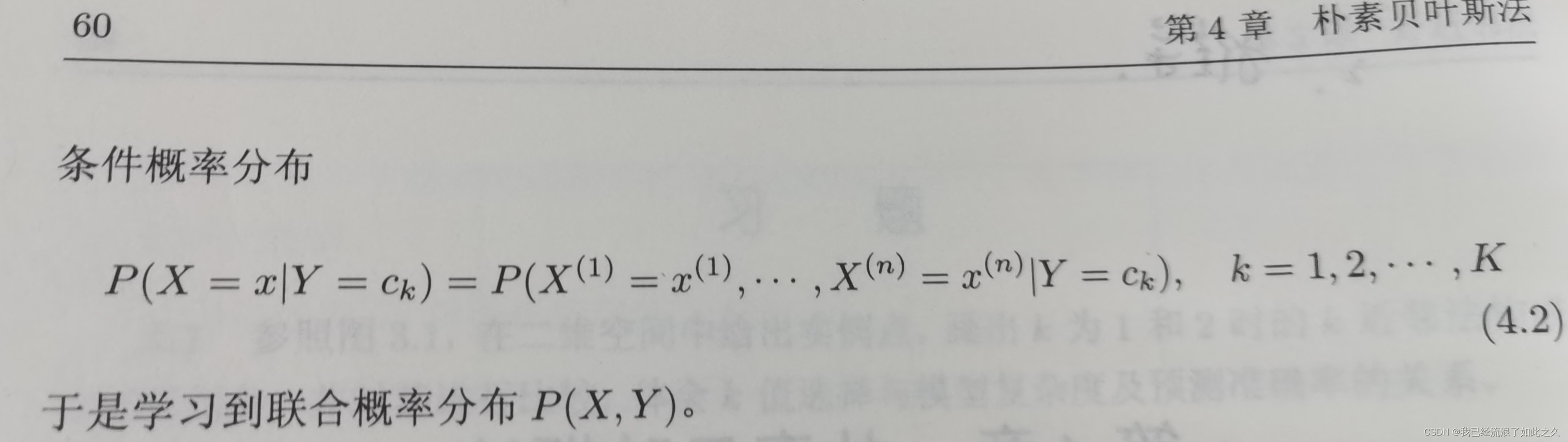
- 朴素贝叶斯法对条件概率分布作了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯法也由此得名。具体地,条件独立性假设是(公式3)
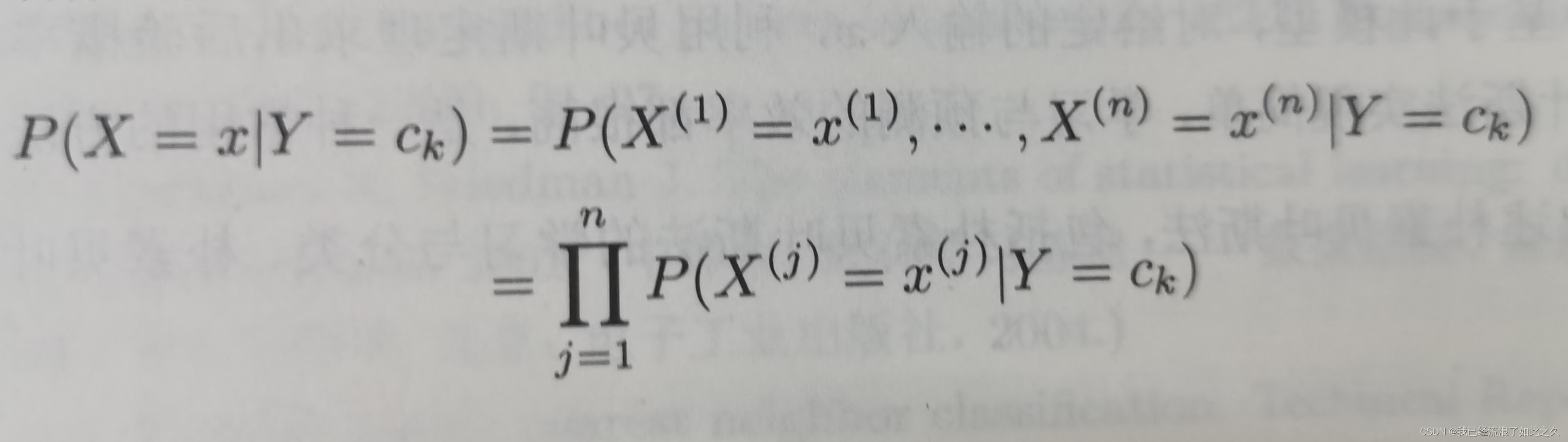
朴素贝叶斯法实际上学习到生成数据的机制,故属于生成模型。条件独立性假设等于是说用于分类的特征在类确定的条件下都是条件独立的。这一假设使得朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
朴素贝叶斯法分类时,对给定的输入x,通过学习到的模型计算后验概率分布,将后验概率最大的类作为x的类输出。
- 后验概率分布(公式4)
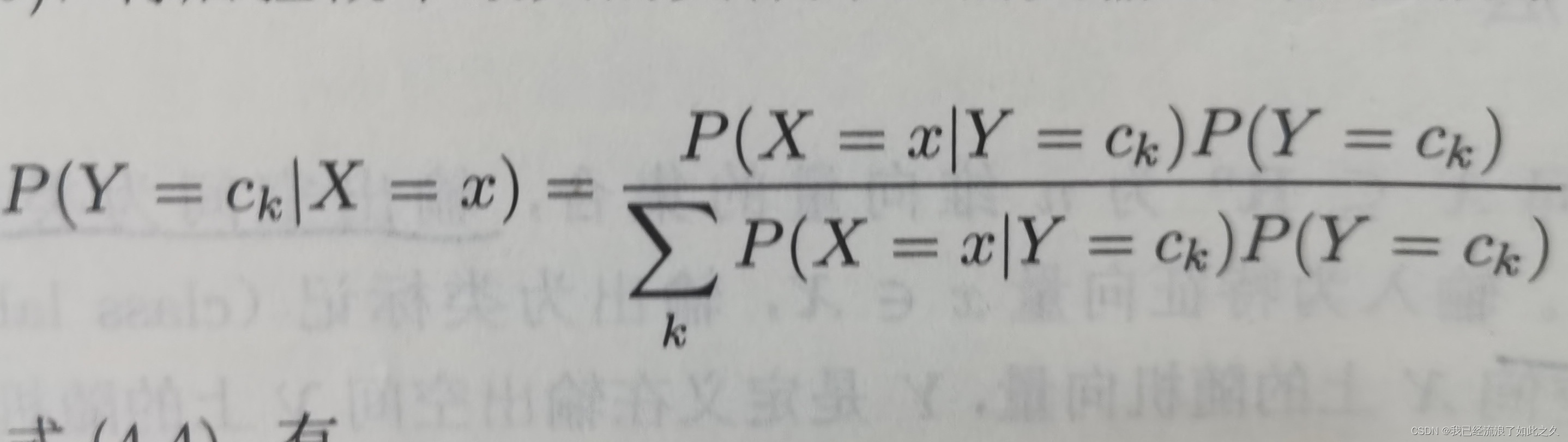
- 朴素贝叶斯法分类的基本公式(公式5 == 公式3 + 公式4)
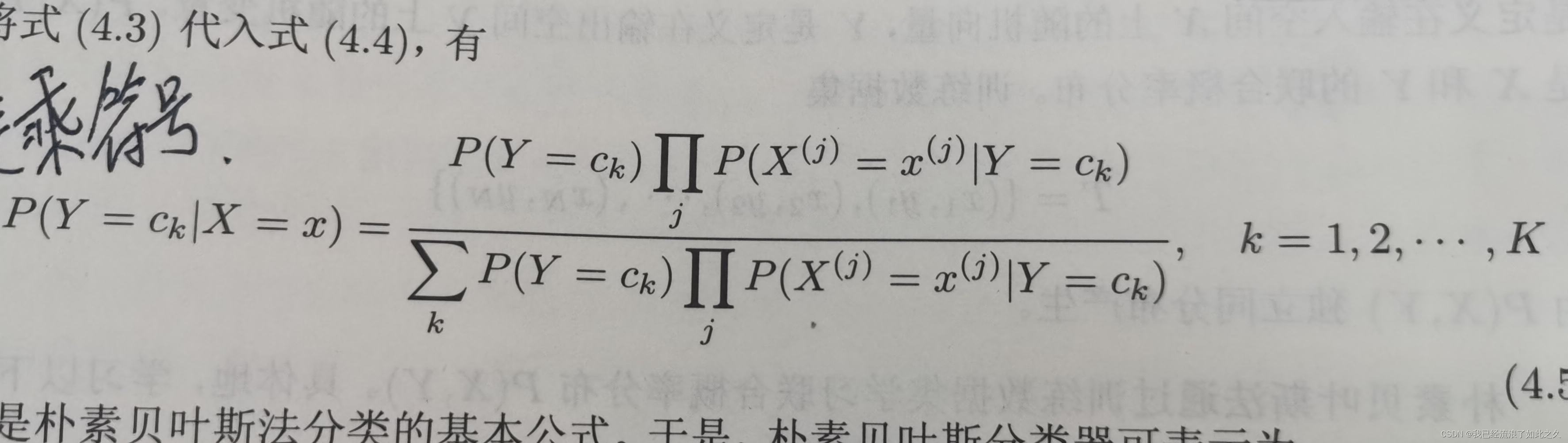
- 朴素贝叶斯分类器(公式6)
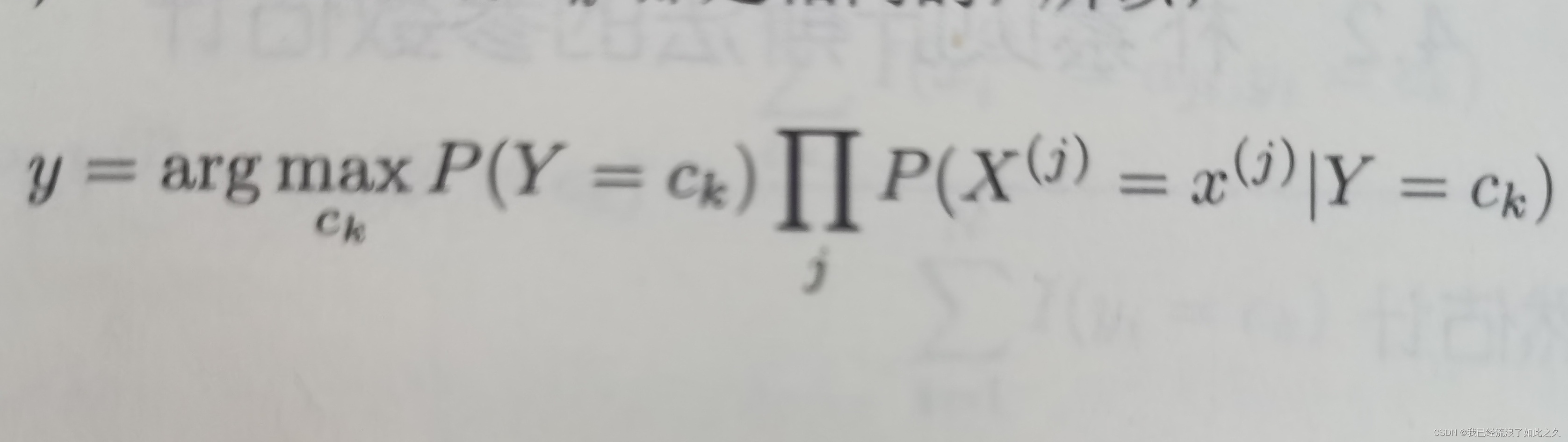
argmax(f(x))是使得f(x)取得最大值所对应的变量点x(或x的集合)
后验概率最大化

朴素贝叶斯的参数估计
极大似然估计

朴素贝叶斯算法(Naive Bayes Algorithm)


贝叶斯估计

代码实现
# 朴素贝叶斯算法 贝叶斯估计, λ=1 K=2, S=3; λ=1 拉普拉斯平滑
import pandas as pd
import numpy as np
class NaiveBayes(object):
def __init__(self):
self.ld = 1 # 即λ=1
self.K = 2
self.S = 3
def classify(self, trainData, labels, features):
labels = list(labels) # 转换为list类型
# 求先验概率
P_y = {}
for label in labels:
P_y[label] = (labels.count(label) + self.ld) / float(len(labels) + self.K * self.ld)
# 求条件概率
P = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # y在labels中的所有下标
y_count = labels.count(y) # y在labels中出现的次数
for j in range(len(features)):
pkey = str(features[j]) + '|' + str(y)
x_index = [i for i, x in enumerate(trainData[:, j]) if x == features[j]] # x在trainData[:,j]中的所有下标
xy_count = len(set(x_index) & set(y_index)) # x y同时出现的次数
P[pkey] = (xy_count + self.ld) / float(y_count + self.S * self.ld) # 条件概率
# features所属类
F = {}
for y in P_y.keys():
F[y] = P_y[y]
for x in features:
F[y] = F[y] * P[str(x) + '|' + str(y)]
features_y = max(F, key=F.get) # 后验概率最大值对应的类别
return features_y
if __name__ == '__main__':
nb = NaiveBayes()
# 数据处理
trainSet = pd.read_csv('naivebayes_data.csv')
trainSetNP = np.array(trainSet) # 由dataframe类型转换为数组类型
trainData = trainSetNP[:, 0:trainSetNP.shape[1] - 1] # 训练数据x1,x2
labels = trainSetNP[:, trainSetNP.shape[1] - 1] # 训练数据所对应的所属类型Y
# x1,x2
features = [3, 'M']
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print(f'{features}属于{result}')
运行结果

参考资料
《统计学习方法》-----李航著















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









