代码实现
import numpy as np
import re
import jieba
import string
def createVocabList(dataSet):
vocabSet = set([])
for i in dataSet:
vocabSet = vocabSet | set(i)
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print(f'the word: {word} is not in my Vocabulary!')
return returnVec
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory) / float(numTrainDocs)
p0Num, p1Num = np.ones(numWords), np.ones(numWords)
p0Denom, p1Denom = 2.0, 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect, p0Vect = np.log(p1Num / p1Denom), np.log(p0Num / p1Denom)
return p0Vect, p1Vect, pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def textParse(bigString):
line = re.sub(r'[a-zA-Z.【】0-9、。,/!…~*\n]', ' ', bigString)
listOfTokens = jieba.cut(line, cut_all=False)
return [tok.lower() for tok in listOfTokens if len(tok) > 1]
def spam():
doc, classList, fullText = [], [], []
for txt in range(1, 11):
word = textParse(open('email/spam/%d.txt' % txt, 'r', encoding='gb2312', errors='ignore').read())
doc.append(word)
fullText.append(word)
classList.append(1)
word = textParse(open('email/ham/%d.txt' % txt, 'r', encoding='gb2312', errors='ignore').read())
doc.append(word)
fullText.append(word)
classList.append(0)
vocab = createVocabList(doc)
trainingSet, testSet = list(range(20)), []
for i in range(5):
randIndex = int(np.random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat, trainClasses = [], []
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocab, doc[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))
errorCount = 0
for docIndex in testSet:
wordVector = setOfWords2Vec(vocab, doc[docIndex])
count = classifyNB(wordVector, p0V, p1V, pSpam)
print(f'count: {count}')
print(f'classList: {classList[docIndex]}')
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print(f'docIndex: {docIndex}')
print(f'分类错误的测试集:{doc[docIndex]}')
print(f'错误率:{float(errorCount) / len(testSet) * 100}%')
if __name__ == '__main__':
spam()
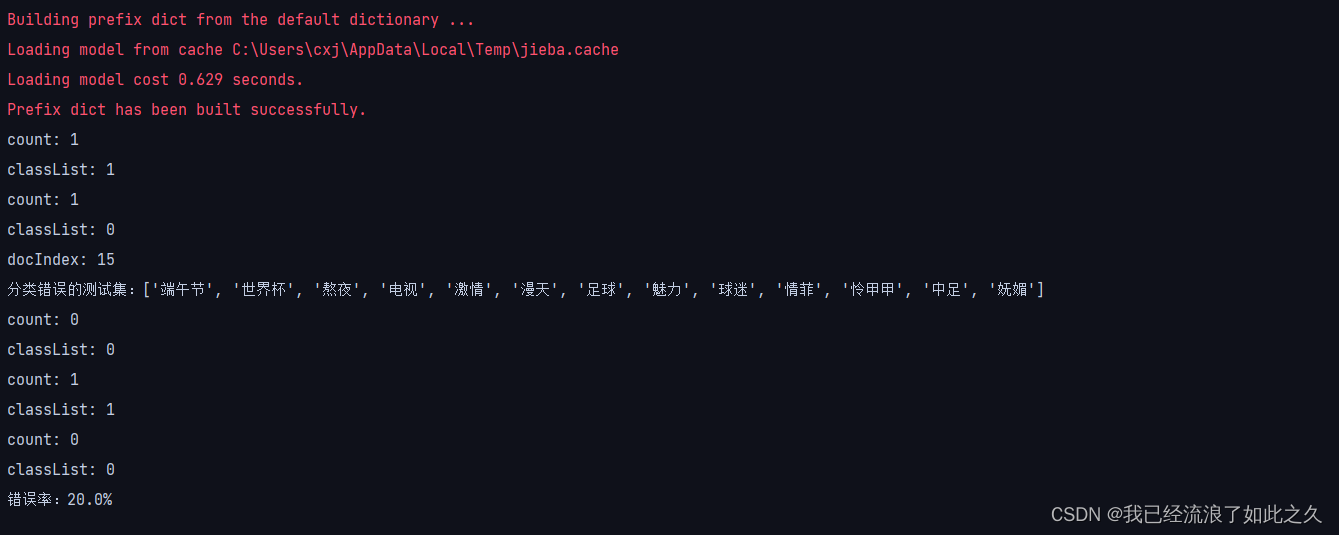
运行结果
参考链接
贝叶斯垃圾分类
基于朴素贝叶斯的垃圾邮件分类Python实现























 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









