







1 概述
在了解Redis中的list数据结构之前,先来回顾和学习一下单向链表和双向链表,以便更好的学习和理解Redis中List的底层数据结构Redis链表。
1.1 单向链表
数组是需要开辟一块连续的内存来存储元素的,这个特点既有优点也有缺点:优点是可以根据下标来访问元素,时间复杂度为O(1);缺点是为了保证在内存中的连续性,插入和删除操作变得非常低效,并且只要数组一声明就会占用整块连续的内存空间。数组声明过大会导致浪费内存,过小可能不够用,当数组的空间不足时需要对其扩容,申请一个更大空间的数组,把原数组的元素复制过去。
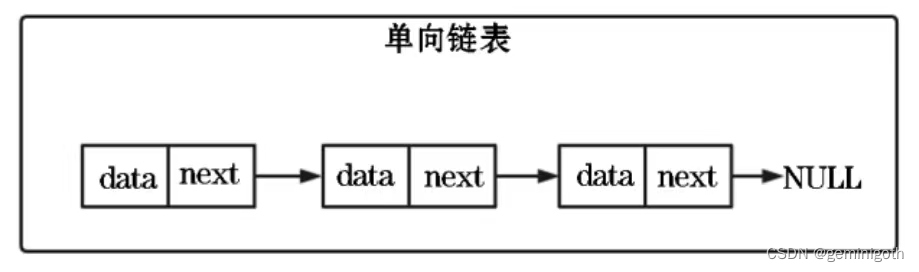
链表不需要连续的内存空间,可以通过指针将一组零散的内存连接起来。其优点在于本身没有大小限制,天然支持扩容,插入和删除操作高效,时间复杂度为O(1),缺点是需要额外的空间来存储指针。单向链表结构如下:
单向链表进行节点的插入和删除操作,如图所示:
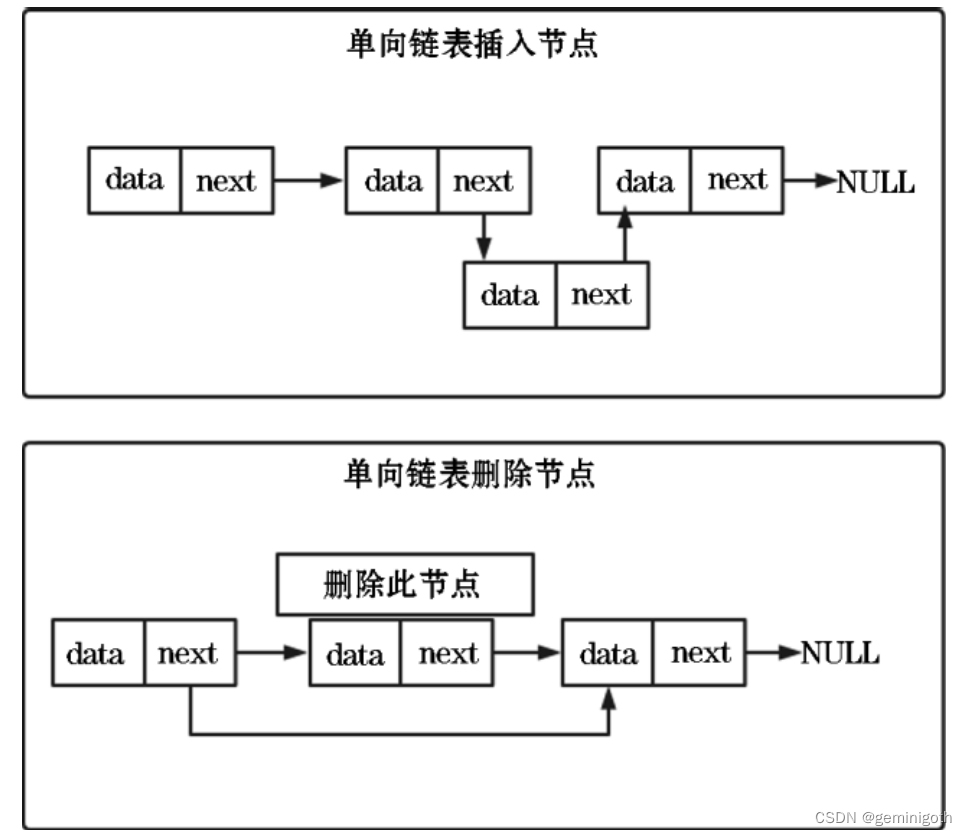
单向链表中每个节点除了包含数据之外,还需要一个指针,即后继指针(存储链表下一个节点地址),所以需要额外的空间来存储后继结点的地址。单向链表中有两个特殊的节点:头结点和尾节点。其中,头结点用来记录链表的起始地址,尾结点的后继指针不是指向像一个节点,而是指向一个空地址(表示这个链表的最后一个节点)。与数组一样,单向链表也支持数据的查找、插入和删除,其中插入和删除操作只需要开率相邻节点指针的变化,因此时间复杂度为O(1)。不过,想要随机访问单向链表的地n个元素,就没有数组那么高效了,因为链表中的数据不是连续存储的,所以不能像数组那样,根据首地址和下标通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针逐个节点地依次遍历,知道找到相应的节点,时间复杂度为O(N)。
1.2 双向链表
双向链表的结构如下图:
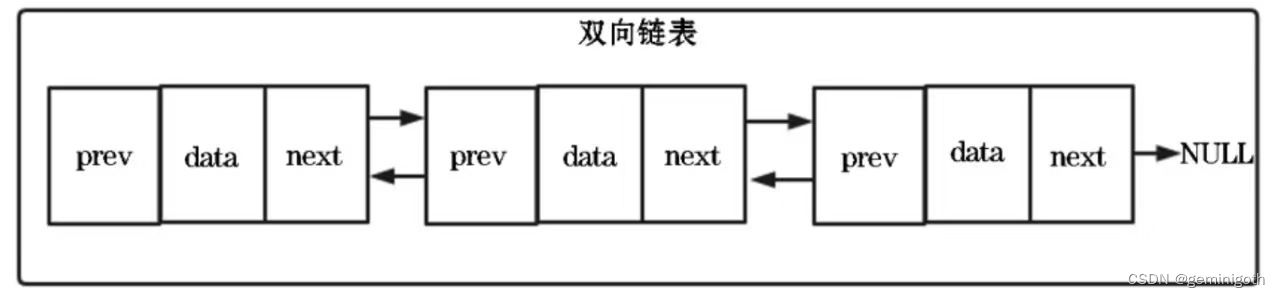
双向链表和单向链表不同的是多了一个前驱指针。双向链表需要额外的两个空间来存储后继结点和前驱节点的地址,占用的空间比单向链表多,优点在于支持双向遍历,体现在以下两个方面:
1、有序链表中查找某个元素,单向链表只有后继指针,因此只能从前往后遍历查找,时间复杂度为O(N);双向链表可以双向遍历,进行二分法查找,时间复杂度为O(log2n)。
2、删除给定指针指向的节点更快捷。要删除节点就必须知道其前驱节点和后继节点,单向链表想要知道其前驱节点就只能从头遍历,而双向链表保存了其前驱节点的地址,所以查找速度更快。
1.3 Redis链表
首先了解一下Redis链表的结果示意图:

定义ListNode节点结构类型的源码如下:
typedef struct listNode {
//前驱节点
struct listNode *prev;
//后继节点
struct listNode *next;
void *value;
} listNode;typedef struct list {
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr, void *key);
//链表所包含的节点数量
unsigned long len;
} list;Redis链表结构的主要特性如下:
1、双向五环:链表节点带有前驱、后继指针获取某个节点的前驱和后继节点的时间复杂度为O(1),表头节点的前驱指针和表尾节点的后继指针都指向NULL,对链表的访问以null为终点。
2、长度计数器:通过List结构的len属性获取节点数量的时间复杂度为O(1)。
1.4 快速列表
实际上QuickList(快速列表)是ZipList和LinkedList的结合体,它将LinkedList按段切分,每一段使用ZipList紧凑存储来节省空间,多个ZipList之间使用双向指针串接起来。QuickList在Redis 3.2版本引入。在引入QuickList之前,Redis采用压缩链表以及双向链表作为List的底层视线。当元素个数比较少并且元素长度比较小时,Redis采用ZipList作为底层存储结构。当任意一个条件不满足时,Redis采用链表作为底层存储结构。这么做的主要原因是:当元素长度较小时,使用ZipList虽然可以节省空间,但储存空间是连续的;当元素个数比较多时,修改元素时必须重新分配存储空间,会影响Redis的执行效率,所以采用双向链表。
链表的附加空间相对较高,prev和next指针就要占16字节,而且每个字节的内存都是单独分配的,会加剧内存的碎片化,影响内存管理的效率。对于内存数据库来说,实在是难以接受,所以Redis 3.2开始对列表数据结构进行了改进,使用QuickList数据结构。
QuickList数据结构示意图如下:
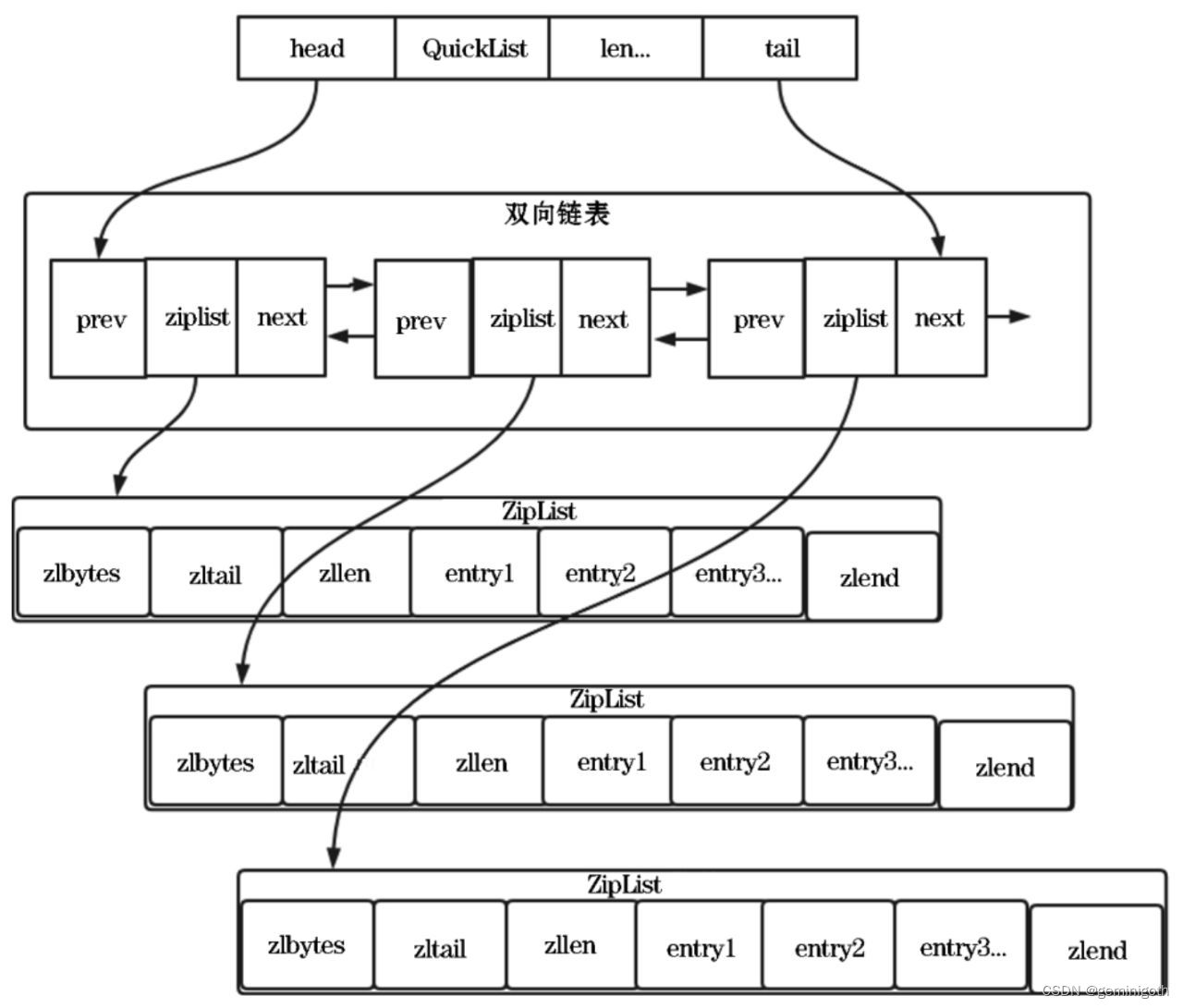
QuickListNode节点的源码如下:
typedef struct quicklistNode {
//上一个node节点
struct quicklistNode *prev;
//下一个node节点
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;prev:指向链表前一个节点的指针
next:指向链表后一个节点的指针
zl:数据指针。如果当前节点的数据没有压缩,那么它指向一个ZipList结构,否则,它指向一个quickList结构。
sz:表示zl指向的Ziplist的总大小。
count:表示ziplist里面包含的数据项个数。
encoding:一个预留字段,用来表明是在一个QuickList节点下直接存储数据还是使用Ziplist村塾数据,或者用其他数据结构存储数据。
container:一个预留字典,用来表明是在一个QuickList节点下直接存储数据还是使用ZipList存储数据,或者用其他数据结构来存储。
recompress:当我们使用index这样的命令来查看了某一项压缩的数据时,需要把该项数据暂时解压,设置recompress=1做一个标记,等有机会再把该项数据重新压缩。
当利用LZF算法对ZipList进行压缩时,quicklistNode节点指向的结构为quicklistLZF。
typedef struct quicklistLZF {
//表示压缩后所占用的字节数
unsigned int sz;
//一个柔性数组,存放压缩后的ZipList字节数组
char compressed[];
} quicklistLZF;
typedef struct quicklist {
//指向头结点的指针
quicklistNode *head;
//指向尾节点的指针
quicklistNode *tail;
//所有ZipList数据项的总项数
unsigned long count;
//quickList节点的个数
unsigned long len;
//16bit,用于设置ZipList的大小,存放list-max-ziplist-depth参数的值
int fill : QL_FILL_BITS;
//16bit,用于设置节点压缩的深度,存放list-compress-depth参数的值
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;1.4.1 插入元素
quickList 可以选择在头部或尾部进行插入,包含以下两种情况:
1、如果ZipList大小没有超过限制,那么新数据会被直接插入ZipList中。
2、如果ZipList超过限制,就需要新创建一个quicklistNode节点,对应的也会新创建一个ZipList,然后把这个新创建的节点插入quickList双向链表中。
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
assert(sz < UINT32_MAX); /* TODO: add support for quicklist nodes that are sds encoded (not zipped) */
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
//头部节点可以插入
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
//头部节点不能继续插入,需要新创建quickListNode
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
//新建的quicklistNode插入quicklist结构体中
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}除了push操作外,QuickList还提供了一种在任意位置插入的方法,流程如下:
1、当ZipList大小没有超过限制,直接插入ZipList中。
2、当ZipList大小超过了限制,但插入的位置位于ZipList两端,并且相邻的QuickList链表节点的ZipList大小没有超过限制,就转而插入相邻的QuickList链表节点的ZipList中。
3、当ZipList大小超过了限制,但插入的位置位于ZipList两端,并且相邻的QuickList链表节点的ZipList大小也超过限制,就需要新创建一个QuickList链表节点插入。
4、对于ZipList大小超过了限制的其他情况,如果数据插入在ZipList中间,就需要把当前ZipList分裂为两个节点,然后在其中一个节点上插入数据。
1.4.2 删除元素
QuickList提供了删除单个元素和删除一个区间内的所有元素两种删除方法。删除单个元素,我们可以使用quicklistDelEntry来实现,也可以通过quicklistPop将头部或尾部元素弹出。quicklistDelEntry函数调用底层quicklistDelIndex函数,该函数可以删除quicklistNode指向的ZipList中的某个元素,其中p指向ZipList中某个entry的起始位置。
//根据指定区间来删除元素
int quicklistDelRange(quicklist *quicklist, const long start,
const long count) {
if (count <= 0)
return 0;
unsigned long extent = count; /* range is inclusive of start position */
if (start >= 0 && extent > (quicklist->count - start)) {
/* if requesting delete more elements than exist, limit to list size. */
extent = quicklist->count - start;
} else if (start < 0 && extent > (unsigned long)(-start)) {
/* else, if at negative offset, limit max size to rest of list. */
extent = -start; /* c.f. LREM -29 29; just delete until end. */
}
quicklistEntry entry;
if (!quicklistIndex(quicklist, start, &entry))
return 0;
D("Quicklist delete request for start %ld, count %ld, extent: %ld", start,
count, extent);
quicklistNode *node = entry.node;
/* iterate over next nodes until everything is deleted. */
while (extent) {
//保存下一个quicklistNode,因为本节点会被删掉
quicklistNode *next = node->next;
unsigned long del;
int delete_entire_node = 0;
if (entry.offset == 0 && extent >= node->count) {
/* 需要删除整个quicklistNode */
delete_entire_node = 1;
del = node->count;
} else if (entry.offset >= 0 && extent >= node->count) {
/* 删除本节点剩余的所有元素 */
del = node->count - entry.offset;
} else if (entry.offset < 0) {
/* 代表从后向前,其他数字代表ZipList后面剩余的元素个数 */
del = -entry.offset;
/* If the positive offset is greater than the remaining extent,
* we only delete the remaining extent, not the entire offset.
*/
if (del > extent)
del = extent;
} else {
/* 删除本节点的元素*/
del = extent;
}
D("[%ld]: asking to del: %ld because offset: %d; (ENTIRE NODE: %d), "
"node count: %u",
extent, del, entry.offset, delete_entire_node, node->count);
if (delete_entire_node) {
__quicklistDelNode(quicklist, node);
} else {
quicklistDecompressNodeForUse(node);
node->zl = ziplistDeleteRange(node->zl, entry.offset, del);
quicklistNodeUpdateSz(node);
node->count -= del;
quicklist->count -= del;
quicklistDeleteIfEmpty(quicklist, node);
if (node)
quicklistRecompressOnly(quicklist, node);
}
extent -= del;
node = next;
entry.offset = 0;
}
return 1;
}QuickList在删除指定区间内的元素时,会先找到start所在的quicklistNode,计算删除的元素个数是否小于要删除的count个数,如果不满足删除个数,就会移动到下一个quicklistNode继续删除,直到删除到指定的元素个数完成为止。
1.4.3 修改元素
QuickList修改元素时按下标进行的,原理是先删除原有元素,之后插入新的元素。QuickList不适合直接改变原有的元素,主要是由于其内部是ZipList结构,在内存中是连续存储的,改变其中一个元素可能会影响后续元素。所以QuickList采用先删除后插入的方法。
int quicklistReplaceAtIndex(quicklist *quicklist, long index, void *data,
int sz) {
quicklistEntry entry;
if (likely(quicklistIndex(quicklist, index, &entry))) {
/* 先删除元素 */
entry.node->zl = ziplistDelete(entry.node->zl, &entry.zi);
//再新插入元素
entry.node->zl = ziplistInsert(entry.node->zl, entry.zi, data, sz);
quicklistNodeUpdateSz(entry.node);
quicklistCompress(quicklist, entry.node);
return 1;
} else {
return 0;
}
}1.4.4 查询元素
列表(List)的查询操作主要是通过下标进行的,根据下标直到链表中ZipList的节点,然后调用ziplistGet就能成功找到。
//idx为要查找元素的下标,把查找结果写入entry,0表示未找到,1表示找到
int quicklistIndex(const quicklist *quicklist, const long long idx,
quicklistEntry *entry) {
quicklistNode *n;
unsigned long long accum = 0;
unsigned long long index;
//当idx值为负时,代表从尾部到头部的偏移量,-1代表尾部元素
int forward = idx < 0 ? 0 : 1; /* < 0 -> reverse, 0+ -> forward */
//初始化entry index quicklistNode
initEntry(entry);
entry->quicklist = quicklist;
if (!forward) {
index = (-idx) - 1;
n = quicklist->tail;
} else {
index = idx;
n = quicklist->head;
}
if (index >= quicklist->count)
return 0;
//遍历quicklistNode节点,找到index对应的quicklistnode
while (likely(n)) {
if ((accum + n->count) > index) {
break;
} else {
D("Skipping over (%p) %u at accum %lld", (void *)n, n->count,
accum);
accum += n->count;
n = forward ? n->next : n->prev;
}
}
if (!n)
return 0;
D("Found node: %p at accum %llu, idx %llu, sub+ %llu, sub- %llu", (void *)n,
accum, index, index - accum, (-index) - 1 + accum);
//计算下标所在的ziplist的偏移量
entry->node = n;
if (forward) {
/* forward = normal head-to-tail offset. */
entry->offset = index - accum;
} else {
/* reverse = need negative offset for tail-to-head, so undo
* the result of the original if (index < 0) above. */
entry->offset = (-index) - 1 + accum;
}
//解压节点数据
quicklistDecompressNodeForUse(entry->node);
entry->zi = ziplistIndex(entry->node->zl, entry->offset);
//从ziplist获取元素
ziplistGet(entry->zi, &entry->value, &entry->sz, &entry->longval);
/* The caller will use our result, so we don't re-compress here.
* The caller can recompress or delete the node as needed. */
return 1;
}















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











