









在遇到哈希冲突时,有以下几种方法可以采用:线性探测法(开放地址法)、链式寻址法(链式散列)、再hash、公共区域等方法[1]。
在Java中,HashMap采用了链式散列,也就是链式寻址法。通常的说,就是数组+链表。数组的每个元素结构如下:
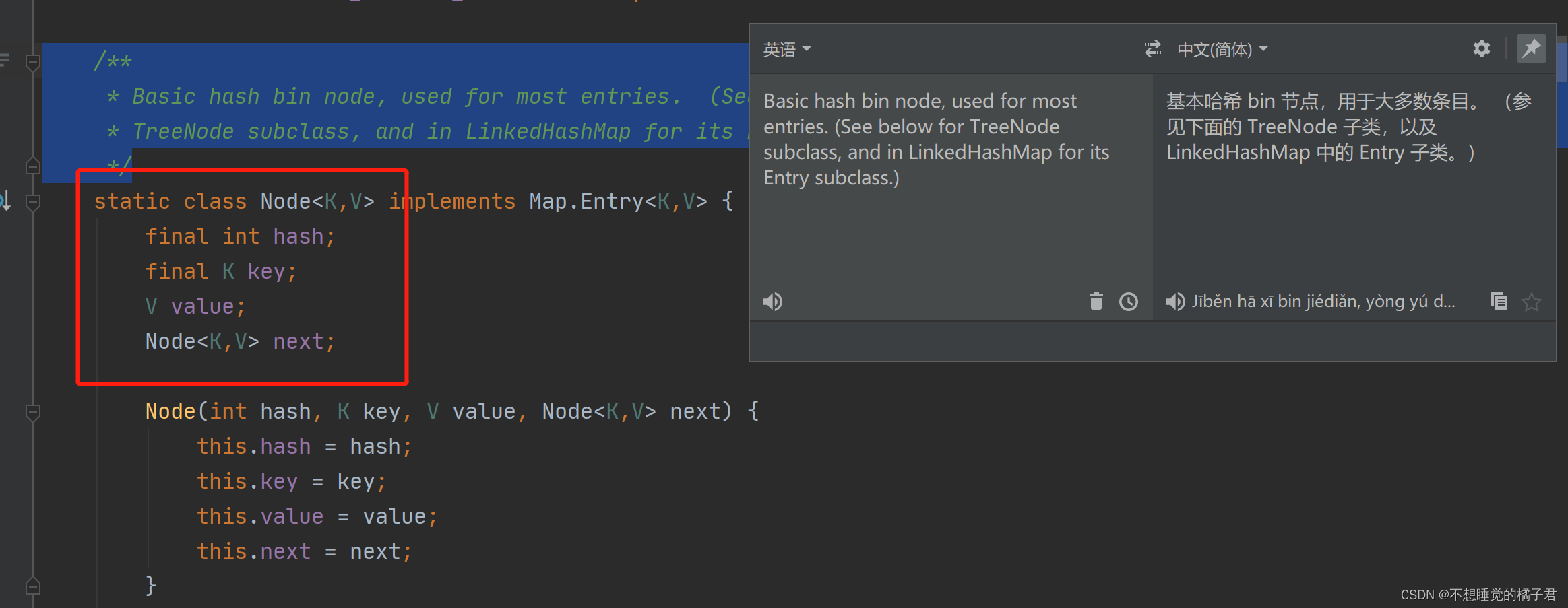
当遇到哈希冲突[2]时,会将节点放在数组这个节点所代表的链表的最后。
基本上网上的文章都在说Java的HashMap在遇到哈希冲突时是这么解决的哈希冲突,但是很少有说在get的时候,怎么判断的这个链表里哪个节点是这个key对应的节点。
查看了源码以后,发现在get方法是这样的。

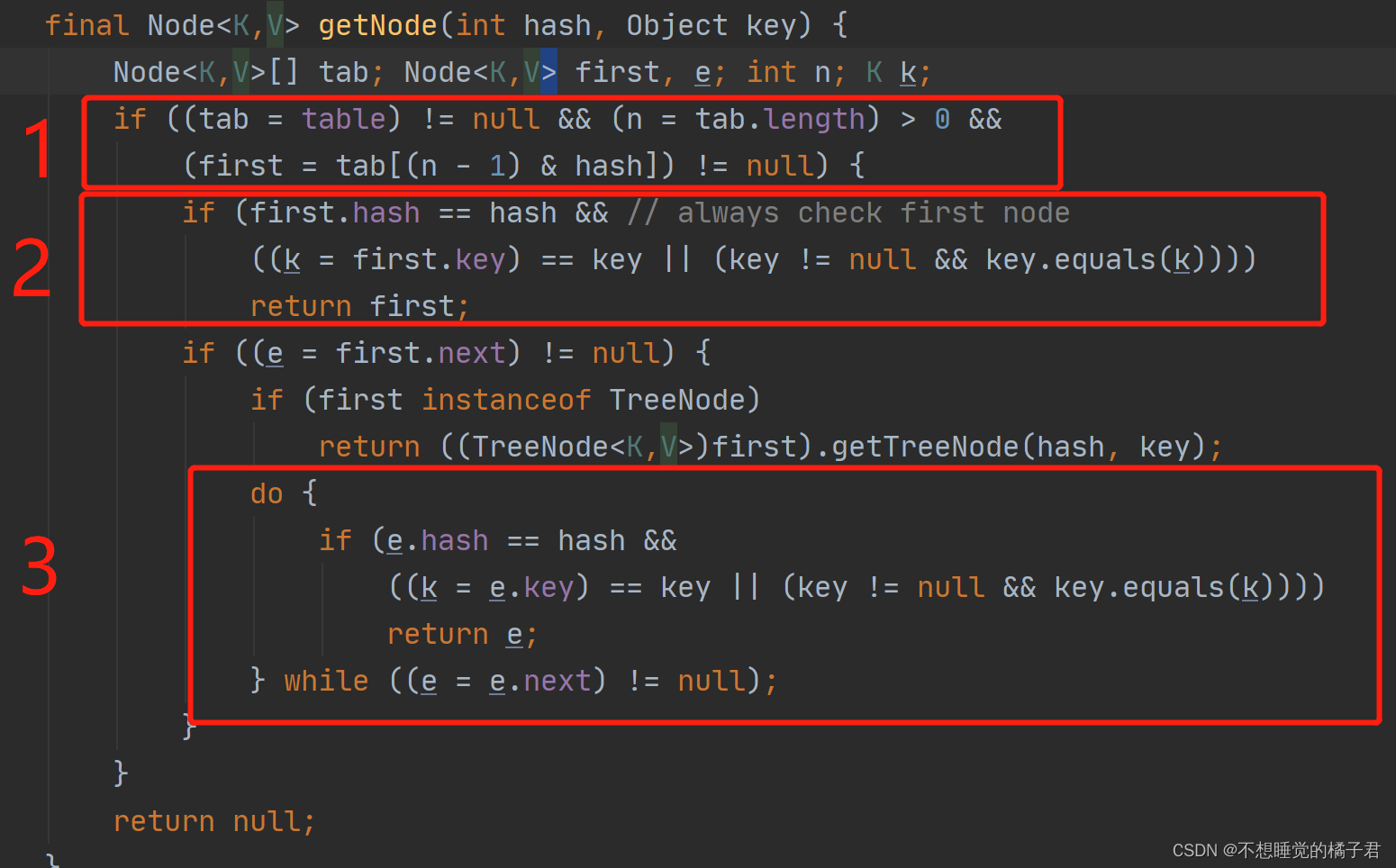
如上图所示,个人理解,1里的if判断是判断这个hashmap是否是一个有效的非null的map,并定位到链表所在的头节点,也就是将链表所在的头节点的引用赋值给first;
2里的if是在通过hash值和key来判断这个头节点是否是这个头节点是否是这个key对应的节点。
到了3,就说明头节点并不是它想要的节点,会通过Node的next寻找下一个节点,不停的向下寻找节点,不断的通过比较hash和key来判断是否是想要的节点,直到返回value或者返回null为止。
个人浅见,可能会有谬误,欢迎大神指正!
参考文献:
[1],HashMap如何解决哈希冲突?
[2],什么是哈希冲突?哈希冲突怎么解决?















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









