







简介
透明防火墙(Transparent Firewall)又称桥接模式防火墙(Bridge Firewall)。简单来说,就是在网桥设备上加入防火墙功能。透明防火墙具有部署能力强、隐蔽性好、安全性高的优点。
br_netfilter架构
-
{Ip,Ip6,Arp}tables can filter bridged IPv4/IPv6/ARP packets, even when encapsulated in an 802.1Q VLAN or PPPoE header. This enables the functionality of a stateful transparent firewall.
-
All filtering, logging and NAT features of the 3 tools can therefore
be used on bridged frames. Combined with ebtables, the bridge-nf code
therefore makes Linux a very powerful transparent firewall. -
This enables, f.e., the creation of a transparent masquerading
machine (i.e. all local hosts think they are directly connected to
the Internet). -
Letting {ip,ip6,arp}tables see bridged traffic can be disabled or
enabled using the appropriate proc entries, located in
/proc/sys/net/bridge/:bridge-nf-call-arptables bridge-nf-call-iptables bridge-nf-call-ip6tables -
Also, letting the aforementioned firewall tools see bridged 802.1Q
VLAN and PPPoE encapsulated packets can be disabled or enabled with a
proc entry in the same directory:bridge-nf-filter-vlan-tagged bridge-nf-filter-pppoe-tagged These proc entries are just regular files. Writing '1' to the file (echo 1 > file) enables the specific functionality, while writing a '0' to the file disables it.
linux iptables/netfilter通过和linux bridge功能联动,以实现透明防火墙功能。
具体地,netfilter在Bridge层的执行使用了IP的Netfilter钩子。
在linux2.6内核中,启用/proc/sys/net/bridge/bridge-nf-call-iptables。
下图展示了透明防火墙下,netfilter的报文传送流程:
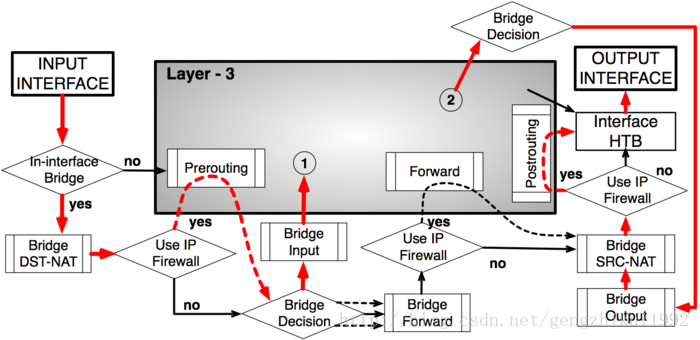
br_netfilter代码流程
br_netfilter_init注册了一些HOOK
ret = nf_register_hooks(br_nf_ops, ARRAY_SIZE(br_nf_ops));
static struct nf_hook_ops br_nf_ops[] __read_mostly = {
{
.hook = br_nf_pre_routing,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_PRE_ROUTING,
.priority = NF_BR_PRI_BRNF,
},
{
.hook = br_nf_local_in,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_LOCAL_IN,
.priority = NF_BR_PRI_BRNF,
},
{
.hook = br_nf_forward_ip,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_FORWARD,
.priority = NF_BR_PRI_BRNF - 1,
},
{
.hook = br_nf_forward_arp,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_FORWARD,
.priority = NF_BR_PRI_BRNF,
},
{
.hook = br_nf_post_routing,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_POST_ROUTING,
.priority = NF_BR_PRI_LAST,
},
{
.hook = ip_sabotage_in,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_FIRST,
},
{
.hook = ip_sabotage_in,
.owner = THIS_MODULE,
.pf = PF_INET6,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP6_PRI_FIRST,
},
};
.hook = br_nf_forward_ip, 对应br_nf_forward_ip函数
/* This is the 'purely bridged' case. For IP, we pass the packet to
* netfilter with indev and outdev set to the bridge device,
* but we are still able to filter on the 'real' indev/outdev
* because of the physdev module. For ARP, indev and outdev are the
* bridge ports. */
static unsigned int br_nf_forward_ip(unsigned int hook, struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
struct nf_bridge_info *nf_bridge;
struct net_device *parent;
u_int8_t pf;
if (LDSEC_DBG_BRIDGE_ON)
LDSEC_PRINT_FUNC("br_nf_forward_ip");
if (!skb->nf_bridge)
return NF_ACCEPT;
/* Need exclusive nf_bridge_info since we might have multiple
* different physoutdevs. */
if (!nf_bridge_unshare(skb))
return NF_DROP;
parent = bridge_parent(out);
if (!parent)
return NF_DROP;
if (skb->protocol == htons(ETH_P_IP) || IS_VLAN_IP(skb) ||
IS_PPPOE_IP(skb))
pf = PF_INET;
else if (skb->protocol == htons(ETH_P_IPV6) || IS_VLAN_IPV6(skb) ||
IS_PPPOE_IPV6(skb))
pf = PF_INET6;
else
return NF_ACCEPT;
nf_bridge_pull_encap_header(skb);
nf_bridge = skb->nf_bridge;
if (skb->pkt_type == PACKET_OTHERHOST) {
skb->pkt_type = PACKET_HOST;
nf_bridge->mask |= BRNF_PKT_TYPE;
}
/* The physdev module checks on this */
nf_bridge->mask |= BRNF_BRIDGED;
nf_bridge->physoutdev = skb->dev;
if (pf == PF_INET)
skb->protocol = htons(ETH_P_IP);
else
skb->protocol = htons(ETH_P_IPV6);
NF_HOOK(pf, NF_INET_FORWARD, skb, bridge_parent(in), parent,
br_nf_forward_finish);
return NF_STOLEN;
}
br_nf_forward_ip最终调用ip层的NF_INET_FORWARD钩子
NF_HOOK(pf, NF_INET_FORWARD, skb, bridge_parent(in), parent,
br_nf_forward_finish);
参考:
http://blog.csdn.net/dog250/article/details/7314927
http://ebtables.netfilter.org/documentation/bridge-nf.html
http://ebtables.netfilter.org/misc/brnf-faq.html
http://ebtables.netfilter.org/br_fw_ia/br_fw_ia.html
https://www.linuxjournal.com/article/8172

















 3588
3588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









