







 本文深入探讨了Linux内核中的bio数据结构,它是块层(block layer)的基础,用于描述I/O请求的属性和状态。bio包含了设备端和内存端的信息,如起始扇区、长度、页地址、页内偏移等,并通过bio_end_io回调函数处理I/O完成。bio有多种类型,如read/write bio、flush bio和discard bio,分别用于读写、刷新设备缓存和释放存储空间。此外,文章还介绍了bio子系统的初始化过程,包括内存管理框架和内存池的创建。
本文深入探讨了Linux内核中的bio数据结构,它是块层(block layer)的基础,用于描述I/O请求的属性和状态。bio包含了设备端和内存端的信息,如起始扇区、长度、页地址、页内偏移等,并通过bio_end_io回调函数处理I/O完成。bio有多种类型,如read/write bio、flush bio和discard bio,分别用于读写、刷新设备缓存和释放存储空间。此外,文章还介绍了bio子系统的初始化过程,包括内存管理框架和内存池的创建。
介绍:
block layer在内核中起着承上(文件系统层)启下(设备驱动层)的作用,struct bio是block层的基本数据结构,可以理解成将bio输入block层,由block layer对其加工处理,然后再由block层输出给底层。与bio相关的代码涉及bio内存管理、提交、合并拆分、完成时的回调处理等内容,是内核中一个很小的子系统,该文对其中涉及的代码进行分析,作为笔记,以备查阅。
内核源码:linux-5.10.3
一、bio数据结构
bio是block层最基本的结构,用来描述io请求属性及状态。从内核数据结构角度看,读写请求依次经历bio(struct bio)、req(struct request)、cmd(struct scsi_cmnd)这些变化,最后cmd被提交给存储器件处理。bio描述的属性有很多,表1列举了bio描述的存储器件端、内存端属性。
| bio描述的io属性 | ||
| device存储器件端 | 内存端 | |
| 属性 | [起始sector,长度] | [page地址,页内偏移,长度] 注:linux支持scatter-gather io,会有1个或多个上面的属性单元,这样的属性单元在代码中用struct bio_vec表示,称作vector或bvec |
| 数据结构 相关成员 | bio->bi_iter->bi_sector bio->bi_iter->bi_size | bio->bi_io_vec->bv_page bio->bi_io_vec->bv_offset bio->bi_io_vec->bv_len |
表1 bio描述的器件、内存端属性
struct bio的定义见include/linux/blk_types.h:
| /* * main unit of I/O for the block layer and lower layers (ie drivers and * stacking drivers) */ struct bio { /* 若一个req中包含多个bio,这些bio通过bi_next组成单向链表,链表以NULL结尾。(bio merge导致一个req中存在多个bio,如果没有merge,一个bio对应一个req) */ struct bio *bi_next; /* request queue link */ /* bio待操作的存储设备(linux块设备代码用struct gendisk描述一个实际的disk)*/ struct gendisk *bi_disk; /* 高8位表示operation,范围0~255,代码中用REQ_OP_XX表示某个operation,如REQ_OP_READ。低24表示flag,每个bit对应一个flag,代码中用REQ_xx表示某个flag,如REQ_SYNC。*/ unsigned int bi_opf; /* bottom bits req flags, * top bits REQ_OP. Use * accessors. */ /* 高3位表示bio->bi_io_vec指向的内存空间是从哪个bvec pool中分配的(这块空间中存放了多个struct bio_vec),代码中一共定义了BVEC_POOL_NR(值为6)个bvec pool见数组 struct biovec_slab bvec_slabs[BVEC_POOL_NR] 。bio相关内存管理见后文“bio子系统内存管理框架总览”。 低13位表示bio的标记,值范围0~2^13,用BIO_XX表示,如BIO_CHAIN表示该bio是bio chain中的一个(bio拆分后或者md驱动中,多个bio形成bio chain)*/ unsigned short bi_flags; /* status, etc and bvec pool number */ /* io优先级,IOPRIO_CLASS_XX(其中XX为NONE、RT、BE、IDLE)。 并不是所有io调度器都会用到这个变量。 io调度器(如bfq)针对不同优先级io的行为是不一样的。 在bio merge或req merge时,不同的优先级的bio或req不允许merge。*/ unsigned short bi_ioprio; /* 描述bio待写数据的life time属性,代码中用WRITE_LIFE_XX表示(其中XX为NOT_SET、NONE、SHORT、MEDIUM、LONG、EXTREME)。按数据在存储设备上存在的时间长短排序,SHORT < MEDIUM < LONG < EXTREME。 这个字段暗示了数据块的更新频率,比如WRITE_LIFE_SHORT就暗示了数据块将很快被更新,更新频繁的数据称为热数据(hot),反之为冷数据(cold),f2fs还定义了介于二者之间的warm数据。 引入该字段的目的: flash设备以page为单位写,以block为单位擦除,一个block含32~256个page,并且由于flash电路特性,只能将1写成0,0擦除成1,所以当一个block中非全1时,需擦除后才能写入数据(即“写前擦除特性”)。如果一个block中冷热数据混存,热数据更新时,flash FTL需要将block中的有效页拷贝到其他空闲block中,然后写入数据,原来的block需要擦除后待用。在这过程中引入了写放大WAF(Write Amplification Factor)、器件寿命磨损两个问题。如果做到冷热数据分离,可减少冷数据的拷贝即擦除,避免上述两个问题的负面影响。(mark,flash特性待整理) 用法: kernel代码中f2fs、nvme用到了这个属性(这两个模块都与flash相关的)。 1)fcntl通过F_SET_RW_HINT设置inode->i_write_hint,对这个文件的写操作,会将该标记传给bio->bi_write_hint。(可选,用户主动设置)。 2)f2fs根据自身文件系统的特点,对自己定义的结构NODE、DATA分成了HOT、WARM、COLD三种类型,举例来说COLD_DATA对应WRITE_LIFE_EXTREME,在文件系统层做冷热数据分离。 3)nvme1.3支持Multi-Stream Write,FTL根据WRITE_LIFE_XX将相同life lime的数据写入相同的block中,做到冷热数据分离。*/ unsigned short bi_write_hint; /* bio的执行结果,BLK_STS_XX(其中XX为OK、NOTSUPP、TIMEOOUT……等多个状态,定义在include/linux/blk_types.h中)*/ blk_status_t bi_status; /* 一个存储器件逻辑上被划分成多个分区,bi_partno表示分区号 */ u8 bi_partno; /* bio chain特性用到__bi_remaining。 何时形成 bio chain?两个场景:
__bi_remaining用途: 代表bio chain中还有几个bio没有处理完,默认值为1。对某一个bio每split产生一个新的bio,__bi_remaining加1。chain类型的bio的回调函数为bio_chain_endio,bio_chain_endio-->bio_endio-->bio_remaining_done将__bi_remaining减1后判断__bi_remaining是否为0,不为0说明bio并没有处理完(目前只是完成了chain中一个bio),bio_endio直接返回,只有当__bi_remaining为0了,bio_endio才会正在地执行。*/ atomic_t __bi_remaining; /*bi_iter指示bio的处理进度(存储器件端起始sector、还剩多少个字节需要读写;内存端当前操作的vector是哪个、当前vector中已经完成了多少个字节),参考图1 */ struct bvec_iter bi_iter; /* bio完成时的回调函数,不同驱动、不同文件系统、不同类型的io的回调处理函数是不一样的。参考后文“bio完成时的处理流程”*/ bio_end_io_t *bi_end_io; /* 各功能模块的私有指针,用于实现特殊功能。用途很多,列举部分:
为什么需要bio_dirty_list? 解决direct io读完成时,bio->bi_end_io无法设置PG_dirty问题。详述如下: direct io完成时执行bio->bi_end_io回调,对应函数为blkdev_bio_end_io,这个回调函数处于软中断上下文,所以不能睡眠。这就带来一个问题:读操作完成时,bio->bi_io_vec->bv_page中填入了刚读入的数据,所以需要设置PG_dirty标记。linux按lock_page--set_page_dirty---unlock_page设置PG_dirty,这里lock_page会睡眠,所以不能用在blkdev_bio_end_io函数中。为了解决该问题,引入bio_dirty_list解决上面的问题。 如何解决? 1)direct io提交读bio之前,设置bio->bi_io_vec->bv_page的PG_dirty标记,然后提交bio,流程见blkdev_direct_IO --> __blkdev_direct_IO: dio->should_dirty = is_read && iter_is_iovec(iter); | bio_set_pages_dirty(bio); | | | set_page_dirty_lock | | | lock_page--set_page_dirty---unlock_page | submit_bio(bio); 2)bio完成时,bio->bi_end_io(即blkdev_bio_end_io) -->bio_check_pages_dirty检查bio->bi_io_vec->bv_page是否有PG_dirty标记。按照预期,前一步已经设置PG_dirty,此处应该有这个标记,但是lock_page--set_page_dirty---unlock_page设置完后释放了锁,所以很可能又有人改变了page的状态,若此时检查没有PG_dirty,则通过bio->bi_private将这些bio添加到bio_dirty_list,并将bio_dirty_work添加到系统共享工作队列system_wq(流程见blkdev_bio_end_io --> bio_check_pages_dirty函数,这里没有lock,所以可以在软中断上下文执行)。 3)system_wq执行bio_dirty_work,调用bio_dirty_fn函数,对bio_dirty_list涉及的page设置PG_dirty。*/ void *bi_private; #ifdef CONFIG_BLK_CGROUP /* * Represents the association of the css and request_queue for the bio. * If a bio goes direct to device, it will not have a blkg as it will * not have a request_queue associated with it. The reference is put * on release of the bio. */ struct blkcg_gq *bi_blkg; struct bio_issue bi_issue; #ifdef CONFIG_BLK_CGROUP_IOCOST u64 bi_iocost_cost; #endif #endif #ifdef CONFIG_BLK_INLINE_ENCRYPTION struct bio_crypt_ctx *bi_crypt_context; #endif union { #if defined(CONFIG_BLK_DEV_INTEGRITY) /* 用于实现end-to-end数据完整性校验功能。T10委员会定义了T10 Protection Information Model(简称PIM),只规定了host adapter 和storage device之间数据完整性校验规范。为了做到end-to-end,bi_integrity中存放校验数据,实现系统调用到I/O controller之间数据完整性校验,该机制称作Data Integrity Extensions(简称DIX)。linux用DIX+PIM的方式就实现了end-to-end数据校验 */ struct bio_integrity_payload *bi_integrity; /* data integrity */ #endif }; /* bio中当前vector(简称bvec)数量,不能大于bio->bi_max_vecs。bio->bi_io_vec[bio->bi_vcnt] 得到的vector是空闲可用的。read、write系统调对应的bio只有一个vector。readv、writev支持scatter-gather io,会有多个vector。通过bio_add_hw_page、__bio_add_page往bio添加一个内存端属性时,bi_vcnt加1 */ unsigned short bi_vcnt; /* how many bio_vec's */ /* * Everything starting with bi_max_vecs will be preserved by bio_reset() */ /* bio中vector最大值,分配bio时设置,见bio_alloc_bioset、bio_init函数 */ unsigned short bi_max_vecs; /* max bvl_vecs we can hold */ /* bio的引用计数,__bi_cnt大于0,bio_put不会释放bio内存。 用法: bio_get(bio); submit_bio(rw, bio); if (bio->bi_flags ...) do_something bio_put(bio); 如果没有bio_get,在执行bio->bi_flags时,bio可能已经完成并被释放,再引用bio指针就会出异常。*/ atomic_t __bi_cnt; /* pin count */ /*bio中的vector(简称bvec)数量小于等于BIO_INLINE_VECS(值为4)时,bio->bi_io_vec指向bio内嵌的bio->bi_inline_vecs,否则指向按需分配的vector地址。不管是bio->bi_inline_vecs还是按需分配的vector,这些vector在虚拟地址上是连续的,本质上就是一个元素为struct bio_vec的数组,bio->bi_io_vec指向数组第一个元素,将地址(bio->bi_io_vec)加1即可得到下一个元素(bvec) */ struct bio_vec *bi_io_vec; /* the actual vec list */ /* bio结构体在内核中会频繁的申请、释放,为了提升性能、避免内存碎片,内核用slab 管理bio内存,slab中存放相同大小的object(object就是struct bio),这些objcect就构成了内存池。需要bio时,从内存池申请,释放时返回给内存池。bi_pool就指向某个内存池。 内核各个模块在使用bio时,会在stuct bio前、后填充一些自己的数据,即各个模块需要的bio的大小是不同的,所以我们在代码中会看到fs_bio_set、blkdev_dio_pool、iomap_ioend_bioset、f2fs_bioset、btrfs_bioset等这些bio内存池。*/ struct bio_set *bi_pool; /* * We can inline a number of vecs at the end of the bio, to avoid * double allocations for a small number of bio_vecs. This member * MUST obviously be kept at the very end of the bio. */ /* bio内嵌了BIO_INLINE_VECS(值为4)个vector(struct bio_vec)。若bio需要的vector数量小于等于BIO_INLINE_VECS,那么直接用这里预定义的bi_inline_vecs,否则按需申请连续的vector */ struct bio_vec bi_inline_vecs[]; }; |
struct bio遵循“需求与执行”分离的原则。bio->bi_io_vec描述“需求”(即io会涉及到哪些vector),bio>bi_iter描述执行情况(即bio的处理进度,当前在处理哪个vector、当前vector中已经完成了多少个字节)。
bio主要成员关系如下:
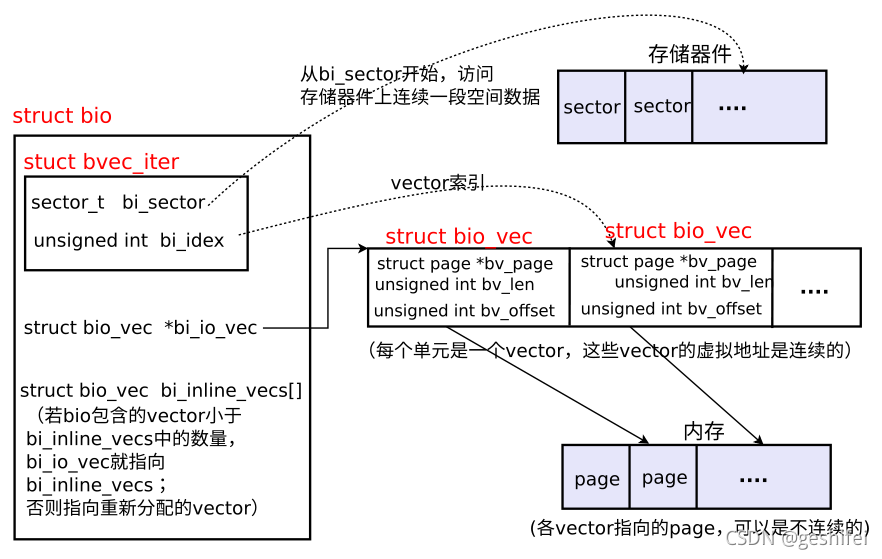
图1 struct bio主要成员间的关系
二、bio的用途
bio中不仅包含有本次io所需的所有信息,还包含有io执行过程中的状态,根据bio中的信息,系统就可以完成指定的io操作。执行io操作时,需先构造一个struct bio,填充bio中成员信息,然后通过submit_bio提交给block层处理即可。以用户读写数据为例,图2展示了内核各模块涉及的数据结构。
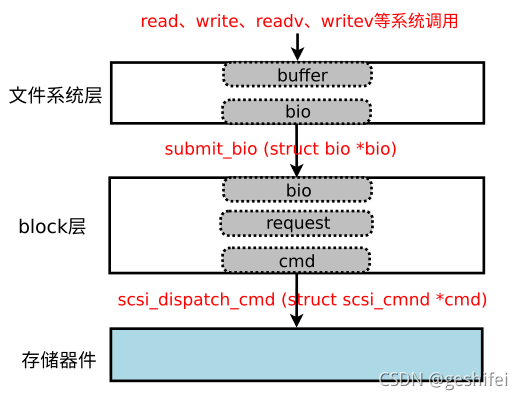
图2 读写流程中各模块涉及的数据结构
三、bio的类型
io请求可能是read/write io、flush io、discard io等这些类型(不一一列举)。
1. read/write bio
read、write、readv、writev系统调用产生的bio就属于读写bio。
文件系统接收到用户的读写请求后(不考虑page cache,需要访问存储设备。),根据系统调用参数,计算出存储器件上需要访问的空间[起始sector,长度]、内存中需要访问的空间[page地址,页内偏移,长度],并设置REQ_OP_READ或REQ_OP_WRITE标记,然后根据这些信息封装出一个bio,通过submit_bio提交给block。
2. flush bio
若bio->bi_opf 含有REQ_PREFLUSH标记位,这个bio就属于flush bio。
flush bio存在的意义?
与存储器件的write cache有关,器件引入write cache是为了提高写性能。另外,存储器件write cache中的写请求被re-order执行写入存储介质中,以便达到最大写吞吐量。具体原因细分两点:
- 往存储器件写数据时,数据写入器件的write cache中就返回“io成功了”,但实际上数据并没有写入介质中,如果此时掉电,数据就丢失了。通过flush可以将write cache中的数据及时地写入介质中。
- 实现write barriers功能,避免write cache的re-order特性打乱io的执行顺序,确保io安照提交顺序被执行。以ext4的journal为例,一个transaction将medata或data变化写入journal数据块中(journal是存储器件的一段空间)后,才能写提交块(提交块用于表示transaction已经被完整写入存储设备)。为了确保执行顺序,就需要提交flush bio,见图3。(mark,ext4 journal待整理)
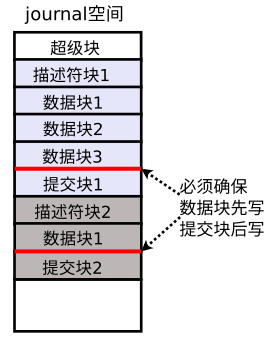
图3 flush bio使用场景例子
如何构造flush bio?
- 通过blkdev_issue_flush发送一个仅仅用于刷器件write cache的bio。
- 通过设置bio的bi_opf的标记位,设置REQ_PREFLUSH。
3. discard bio
若bio->bi_opf 含有REQ_OP_DISCARD或REQ_OP_SECURE_ERASE标记位,这个bio就属于discard bio。
discard bio存在的意义?
删除文件时,文件系统只是在内部做了标记,记录文件占用的数据块已经无效,可以被再利用了。对于存储设备来说,它并不知情,依然认为这些数据块有效的,只有当文件系统要求覆盖写这些数据块时,存储设备才知道数据中的数据是无效的。如果存储设备上存在大量这样的数据块,会导致写性能下降(flash设备以page为单位写、以block为单位擦除,一个block含32~256个page,如果一个block被写过,再次写入数据,需要先擦除以前的数据。大量的含有部分有效数据的block会导致free block减少,无法找到空闲的free block的话,就需要合并多个block有效数据,进而释放出可用的block)。
文件系统通过discard告诉flash哪些数据块已经无效了,这样flash FW中的gc就可以及时地做垃圾回收,保证有充足的free block可用。
如何构造discard bio?
- 通过blkdev_issue_discard发送discard bio。
四、bio子系统初始化
-
初始化入口函数
bio子系统的初始化从subsys_initcall(init_bio)开始,subsys_initcal是一个宏,见include/linux/init.h,这条语句的作用是将init_bio函数地址链接在.initcall4.init段。内核启动时会按顺序执行init段中的函数,调用链见下:
start_kernel
--> xx_init初始化函数
--> arch_call_rest_init
--> rest_init
--> kernel_thread(kernel_init, NULL, CLONE_FS)
--> kernel_init
--> kernel_init_freeable
--> do_basic_setup
--> do_initcalls
do_initcalls遍历init段中的函数指针,依次执行,所以当找到init_bio地址后,就开始执行init_bio函数。
2. bio子系统内存管理框架总览
init_bio主要工作是为bio子系统搭建一个内存管理框架,为频繁申请、释放的struct bio、struct bio_vec数据结构建立内存池,总览图见下。
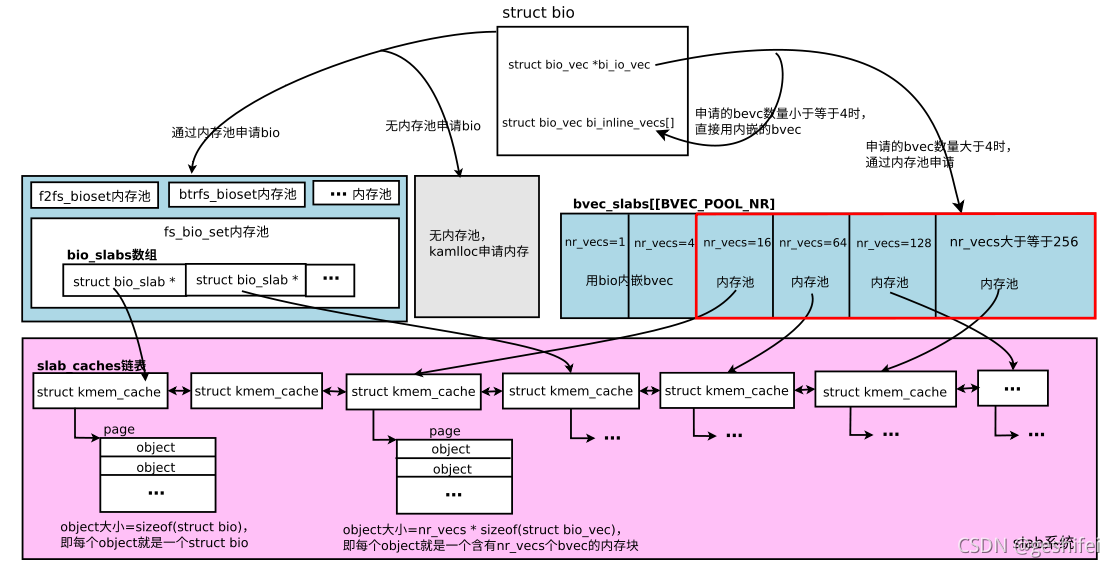 图4 bio子系统内存管理总览图
图4 bio子系统内存管理总览图
图4中蓝色部分是bio子系统的数据结构,紫色部分是内存管理的slab数据结构。
内核各模块使用struct bio时,有的模块需要在struct bio结构体前附加一些数据用于实现特定目的,这就导致各模块需申请“附加数据块+struct bio”大小的内存块,内核将相同大小的内存块归为一类,所以我们在内核代码中看到有f2fs_bioset、btrfs_bioset、fs_bio_set、blkdev_dio_poo等等不同类型的内存池。其中fs_bio_set内存池中的bio是标准的struct bio,bio结构体前无附加数据,若对bio没有特殊需求,就从该内存池中申请bio即可。
3.初始化源码分析
写源码细节是比较繁琐的,初始化代码主要就是将各个内存池初始化成图4的样子,如果不想了解细节,可以跳过后面内容。这里作为个人记录,以便日后不看源码的情况下,就能知道代码细节。
init_bio初始化了fs_bio_set类型内存池,其他类型内存池的初始化,由各个使用bio的模块进行初始化。在这个函数中还初始化了数据完整性(data integrity)相关的内存池、bvec内存池。详细代码如下。
1)kcalloc初始化bio_slab数组
init_bio
--> bio_slabs = kcalloc(bio_slab_max, sizeof(struct bio_slab), GFP_KERNEL)
分配2个struct bio_slab块,bio_slabs指向内存块起始地址。struct bio_slab结构体说明如下:
| @slab 指向cache描述符,cache描述符描述了slab信息 @slab_ref bio_slab结构体引用计数 @slab_size 内存池中object大小 @name 内存池名称,/proc/slabinfo可以看到 |
分配的内存示意图:
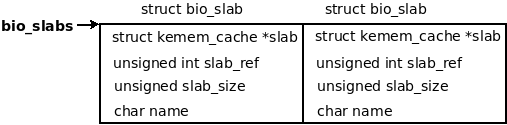
图5 分配的bio_slabs内存示意图
没当bioset_init创建一个新类型的内存池时,需要占用一个bio_slab,bio_slab用完时,通过krealloc分配更多的bio_slab(见bioset_init --> bio_find_or_create_slab流程)。
2)bio_integrity_init初始化data integrity内存池
init_bio
--> bio_integrity_init
基于slab机制分配data integrity内存池,略去分析(遇到bio初始化时再分析slab代码)。
3)biovec_init_slabs初始化bvec内存池
init_bio
--> biovec_init_slabs
调用 kmem_cache_create为bvec_slabs数组中的部分元素创建cache描述符:
1633 static void biovec_init_slabs(void)
1634 {
1635 int i;
1636
1637 for (i = 0; i < BVEC_POOL_NR; i++) {
1638 int size;
1639 struct biovec_slab *bvs = bvec_slabs + i;
1640
1641 if (bvs->nr_vecs <= BIO_INLINE_VECS) {
1642 bvs->slab = NULL;
1643 continue;
1644 }
1645
1646 size = bvs->nr_vecs * sizeof(struct bio_vec);
1647 bvs->slab = kmem_cache_create(bvs->name, size, 0,
1648 SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL);
1649 }
1650 }bvec_slabs数组管理bvec内存池,各数组元素的nr_vecs值不一样。如果bio需要的bvec数量≤4,直接用内嵌的bio->bi_inline_vecs[],否则就从内存池中申请,参考图4。数组定义如下:
#define BVEC_POOL_NR 6
#define BV(x, n) { .nr_vecs = x, .name = "biovec-"#n }
static struct biovec_slab bvec_slabs[BVEC_POOL_NR] __read_mostly = {
BV(1, 1), BV(4, 4), BV(16, 16), BV(64, 64), BV(128, 128), BV(BIO_MAX_PAGES, max),
};此时仅仅是创建了cache描述符,并没有为slab中的object(object大小= nr_vecs * sizeof(struct bio_vec))分配内存。
cache描述符中有cache名称、object数量、大小等等属性,可以通过cat /proc/slabinfo查看,因为还未分配object内存,可看到“当前正在使用的object数量”、“总的object数量”都是0。
| root@linux:/home/gsf# cat /proc/slabinfo slabinfo - version: 2.1 # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail> biovec-max 0 0 4096 8 8 : tunables 0 0 0 : slabdata 19 19 0 biovec-128 0 0 2048 16 8 : tunables 0 0 0 : slabdata 4 4 0 biovec-64 0 0 1024 16 4 : tunables 0 0 0 : slabdata 6 6 0 |
4)bioset_init初始化fs_bio_set类型内存池
单从bio子系统来说,这个函数没什么好讲的,就是基于内核的slab机制创建bio cache、bvec cache,并在cache中分配至少BIO_POOL_SIZE(值为2)个object,相关代码属于内存管理模块的。但由于slab在init_bio初始化中反复出现,还是有必要针对涉及的代码说一下。
init_bio
--> bioset_init(&fs_bio_set, BIO_POOL_SIZE, 0, BIOSET_NEED_BVECS)
| bioset_init(struct bio_set *bs, unsigned int pool_size, unsigned int front_pad, int flags) @bs 需要初始化的bio_set指针。bio_set有f2fs_bioset、btrfs_bioset、fs_bio_set、blkdev_dio_poo等等不同类型,init_bio初始化的是fs_bio_set。 @pool_size 内存池中bio的最小数量。 @front_pad struct bio结构体前附加数据块的大小,front_pad+sizeof(struct bio)就是内存池中object的大小。从fs_bio_set类型内存池中申请bio内存块,bio前无附加数据。 @flags BIOSET_NEED_BVECS :创建一个单独的内存池用于分配iovecs,fs_bio_set需设置该标记。BIOSET_NEED_RESCUER:创建一个workqueue,处理函数为bio_alloc_rescue,当内存不足无法从内存池中申请到bio时,该workqueue把处理stack device时(比如raid)暂存在list中的bio(参考后文“bio的提交”)提交处理,从而回收bio。对于非stack device场景,不需要这个工作队列。 |
block/bio.c
| 1577 int bioset_init(struct bio_set *bs, 1578 unsigned int pool_size, 1579 unsigned int front_pad, 1580 int flags) 1581 { 1582 unsigned int back_pad = BIO_INLINE_VECS * sizeof(struct bio_vec); 1583 1584 bs->front_pad = front_pad; 1585 1587 bio_list_init(&bs->rescue_list); 1588 INIT_WORK(&bs->rescue_work, bio_alloc_rescue); 1589 1590 bs->bio_slab = bio_find_or_create_slab(front_pad + back_pad); 1593 1594 if (mempool_init_slab_pool(&bs->bio_pool, pool_size, bs->bio_slab)) 1595 goto bad; 1596 1597 if ((flags & BIOSET_NEED_BVECS) && 1598 biovec_init_pool(&bs->bvec_pool, pool_size)) 1599 goto bad; 1600 1601 if (!(flags & BIOSET_NEED_RESCUER)) 1602 return 0; 1603 1604 bs->rescue_workqueue = alloc_workqueue("bioset", WQ_MEM_RECLAIM, 0); 1612 } |
主要工作,建立bio及bvec内存池、并在各内存池中分配至少BIO_POOL_SIZE(值为2)个object内存空间。
下面分析bio_find_or_create_slab代码。
init_bio
--> bioset_init(&fs_bio_set, BIO_POOL_SIZE, 0, BIOSET_NEED_BVECS)
--> bio_find_or_create_slab(front_pad + back_pad)
| static struct kmem_cache *bio_find_or_create_slab(unsigned int extra_size) @extra_size 申请bio结构体时,需要多申请的额外空间 |
block/bio.c
| 64 static struct kmem_cache *bio_find_or_create_slab(unsigned int extra_size) 65 { 66 unsigned int sz = sizeof(struct bio) + extra_size; 67 struct kmem_cache *slab = NULL; 68 struct bio_slab *bslab, *new_bio_slabs; 69 unsigned int new_bio_slab_max; 70 unsigned int i, entry = -1; 71 73 74 i = 0; 75 while (i < bio_slab_nr) { 76 bslab = &bio_slabs[i]; 77 78 if (!bslab->slab && entry == -1) 79 entry = i; 80 else if (bslab->slab_size == sz) { 81 slab = bslab->slab; 82 bslab->slab_ref++; 83 break; 84 } 85 i++; 86 } 87 88 if (slab) 89 goto out_unlock; 90 91 if (bio_slab_nr == bio_slab_max && entry == -1) { 92 new_bio_slab_max = bio_slab_max << 1; 93 new_bio_slabs = krealloc(bio_slabs, 94 new_bio_slab_max * sizeof(struct bio_slab), 95 GFP_KERNEL); 96 if (!new_bio_slabs) 97 goto out_unlock; 98 bio_slab_max = new_bio_slab_max; 99 bio_slabs = new_bio_slabs; 100 } 101 if (entry == -1) 102 entry = bio_slab_nr++; 103 104 bslab = &bio_slabs[entry]; 105 106 snprintf(bslab->name, sizeof(bslab->name), "bio-%d", entry); 107 slab = kmem_cache_create(bslab->name, sz, ARCH_KMALLOC_MINALIGN, 108 SLAB_HWCACHE_ALIGN, NULL); 109 if (!slab) 110 goto out_unlock; 111 112 bslab->slab = slab; 113 bslab->slab_ref = 1; 114 bslab->slab_size = sz; 117 return slab; 118 } |
该函数分为两部分。
第一部分:
75~104行,在bio_slabs数组中找到一个bio_slab。
- 遍历bio_slabs数组,若某个bio_slab->slab_size等于sizeof(struct bio) + extra_size,那么就选择这个bio_slab,转第二部分执行。
- 若bio_slabs有空闲未用的bio_slab,选择该bio_slab,转第二部分执行。
- 经过上面两步依然未找到可用的bio_slab,通过krealloc将bio_slabs数组长度扩大一倍,并选择其中一个空闲的bio_slab,转第二部分执行。
第二部分:
107行,执行kmem_cache_create创建一个cache描述符。
init_bio
--> bioset_init(&fs_bio_set, BIO_POOL_SIZE, 0, BIOSET_NEED_BVECS)
--> bio_find_or_create_slab(front_pad + back_pad)
-->kmem_cache_create
| struct kmem_cache * kmem_cache_create(const char *name, unsigned int size, unsigned int align, slab_flags_t flags, void (*ctor)(void *)) @name cache名称,/proc/slabinfo中可以看到 @size cache中object大小 @align object按照align大小对齐,ARCH_KMALLOC_MINALIGN, @flags slab的标记,其中SLAB_HWCACHE_ALIGN表示object大小按硬件缓存行对齐/sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size可查看大小 @ctor 分配object内存后,对object执行的构造函数 |
mm/slab_common.c
405 struct kmem_cache *
406 kmem_cache_create(const char *name, unsigned int size, unsigned int align,
407 slab_flags_t flags, void (*ctor)(void *))
408 {
409 return kmem_cache_create_usercopy(name, size, align, flags, 0, 0,
410 ctor);
411 }简单封装,执行kmem_cache_create_usercopy函数。
mm/slab_common.c
300 struct kmem_cache *
301 kmem_cache_create_usercopy(const char *name,
302 unsigned int size, unsigned int align,
303 slab_flags_t flags,
304 unsigned int useroffset, unsigned int usersize,
305 void (*ctor)(void *))
306 {
307 struct kmem_cache *s = NULL;
308 const char *cache_name;
338 usersize = useroffset = 0;
340 if (!usersize)
341 s = __kmem_cache_alias(name, size, align, flags, ctor);
342 if (s)
343 goto out_unlock;
344
345 cache_name = kstrdup_const(name, GFP_KERNEL);
350
351 s = create_cache(cache_name, size,
352 calculate_alignment(flags, align, size),
353 flags, useroffset, usersize, ctor, NULL);
358
376 return s;
377 }首先调用__kmem_cache_alias,遍历slab_caches链表,检查已有的slab cache中是否能找到满足条件的cache(条件:链表中cache管理的object大小满足参数@size需求),若找到这样的cache,就用这个slab cache,不需要创建新的slab cache了。
共用已有的slab cache,又称作slab merging,此时,/proc/slabinfo只能看到原slab的名称,毕竟用的是原来的struct kmem_cache,通过/sys/kernel/slab/名称/aliases可以看到合并的slab数量(不含自己),通过kernel/tools/vm/slabinfo.c编译的slabinfo工具可以查看合并slab的名称。
假设不能merge到已有的slab cache,这时就要通过create_cache创建一个新的slab cache了。
232 static struct kmem_cache *create_cache(const char *name,
233 unsigned int object_size, unsigned int align,
234 slab_flags_t flags, unsigned int useroffset,
235 unsigned int usersize, void (*ctor)(void *),
236 struct kmem_cache *root_cache)
237 {
238 struct kmem_cache *s;
239 int err;
240
243
244 err = -ENOMEM;
245 s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL);
246 if (!s)
247 goto out;
248
249 s->name = name;
250 s->size = s->object_size = object_size;
251 s->align = align;
252 s->ctor = ctor;
253 s->useroffset = useroffset;
254 s->usersize = usersize;
255
256 err = __kmem_cache_create(s, flags);
257 if (err)
258 goto out_free_cache;
259
260 s->refcount = 1;
261 list_add(&s->list, &slab_caches);
262 out:
265 return s;
270 }245~254行,分配一个struct kmem_cache结构,并初始其成员。256行在sysfs文件系统中创建一个节点(/sys/kernel/slab/名称),261行将新建的kmem_cache描述符添加到全局链表slab_caches中,这样就能通过/proc/slabinfo查看。
总结一下,上面流程执行完后的状态:
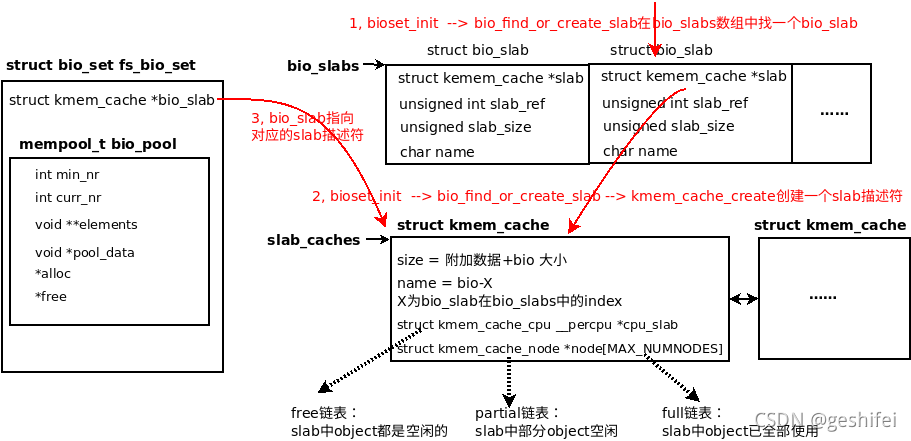
图6 bio_find_or_create_slab执行完后的状态
回到bioset_init,分析mempool_init_slab_pool代码,准备初始化图5左边的fs_bio_set->bio_pool。
init_bio
--> bioset_init(&fs_bio_set, BIO_POOL_SIZE, 0, BIOSET_NEED_BVECS)
--> bio_find_or_create_slab(front_pad + back_pad)
--> mempool_init_slab_pool
| static inline int mempool_init_slab_pool(mempool_t *pool, int min_nr, struct kmem_cache *kc) @pool 待初始化的bio内存池 @min_nr 内存池中最小的元素数量 @kc slab描述符 include/linux/mempool.h |
include/linux/mempool.h
59 static inline int
60 mempool_init_slab_pool(mempool_t *pool, int min_nr, struct kmem_cache *kc)
61 {
62 return mempool_init(pool, min_nr, mempool_alloc_slab,
63 mempool_free_slab, (void *) kc);
64 }简单封装,指定mempool_alloc_slab为构造函数、mempool_free_slab为析构函数。
mm/mempool.c
226 int mempool_init(mempool_t *pool, int min_nr, mempool_alloc_t *alloc_fn,
227 mempool_free_t *free_fn, void *pool_data)
228 {
229 return mempool_init_node(pool, min_nr, alloc_fn, free_fn,
230 pool_data, GFP_KERNEL, NUMA_NO_NODE);
231
232 }mm/mempool.c
178 int mempool_init_node(mempool_t *pool, int min_nr, mempool_alloc_t *alloc_fn,
179 mempool_free_t *free_fn, void *pool_data,
180 gfp_t gfp_mask, int node_id)
181 {
182 spin_lock_init(&pool->lock);
183 pool->min_nr = min_nr;
184 pool->pool_data = pool_data;
185 pool->alloc = alloc_fn;
186 pool->free = free_fn;
187 init_waitqueue_head(&pool->wait);
188
189 pool->elements = kmalloc_array_node(min_nr, sizeof(void *),
190 gfp_mask, node_id);
191 if (!pool->elements)
192 return -ENOMEM;
193
194 /*
195 * First pre-allocate the guaranteed number of buffers.
196 */
197 while (pool->curr_nr < pool->min_nr) {
198 void *element;
199
200 element = pool->alloc(gfp_mask, pool->pool_data);
201 if (unlikely(!element)) {
202 mempool_exit(pool);
203 return -ENOMEM;
204 }
205 add_element(pool, element);
206 }
207
208 return 0;
209 }189行分配min_nr个sizeof(void *),用于存放slab object地址,对于fs_bio_set,min_nr=BIO_POOL_SIZE即2个object。这里的object就是“附加数据+bio”内存块。
197~205行,如果内存池中object数量小于最小值pool->min_nr,就通过pool->alloc即mempool_alloc_slab,mempool_alloc_slab内部调用链很深,不做过多描述,记住这里会为slab分配object内存空间,并返回一个空闲object地址,然后通过add_element加入到内存池中。上面流程执行完后的状态:
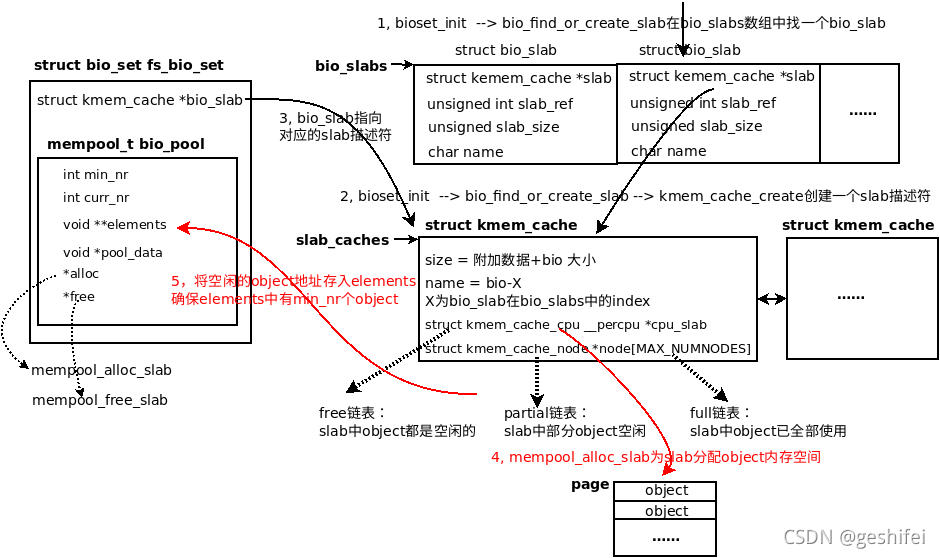
图7 mempool_init_slab_pool执行完后的状态
理解了上面代码就能很容易看懂余下的biovec_init_pool、biovec_init_pool函数,不再分析。

















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









