






5.微基准测试与统计
你不能糊弄自己,你自己恰恰是最容易被蒙骗的人。 --Richard Feynman
5.1 Java 性能测量
仅仅收集数据是不够的,还要保证不被数据欺骗
没有谁是一座孤岛
一个排序的基准测试
Code
public class ClassSort {
private static final int N = 1_000;
private static final int I = 15_000;
private static final List<Integer> testData = new ArrayList<>();
public static void main(String[] args) {
Random random = new Random();
for (int i = 0; i < N; i++) {
testData.add(random.nextInt(Integer.MAX_VALUE));
}
System.out.println("Testing Sort Algorithm");
double startTime = System.nanoTime();
for (int i = 0; i < I; i++) {
List<Integer> copy = new ArrayList<>(testData);
Collections.sort(copy);
}
double endTime = System.nanoTime();
double timePeroperation = ((endTime - startTime) / (1_000_000_000L * I));
System.out.println("Result: " + (1 / timePeroperation) + " op/s");
}
}1. 没有考虑jvm预热
2. 没有考虑外部垃圾收集
3. 测试的代码没用到,Copy是死代码,有可能被优化了
4. 单个计时结果无法全面了解基准测试的性能;
5. 同时要考虑硬件性能(电源模式/其他资源争用);
虚拟机参数
• -Xms2048m -Xm2048m --- -把堆的大小固定为两G ---对应问题1
• -XX:PrintCompilation --每当一个方法被编译,就会输出一行日志
• -verbose:gc -- 产生垃圾日志收集条目---对应问题2
输出的情况
java -Xms2048m -Xmx2048m -verbose:gc ClassSort.java
[0.005s][info][gc] Using G1
Testing Sort Algorithm
[0.667s][info][gc] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 102M->3M(2048M) 2.221ms
Result: 28055.877349714563 op/s5.2 JMH
5.2.1 不是万不得己,不要做基准测试
一个故事
1. 因为使用新版本的库导致性能问题
2. 认为是自己的代码问题,优化无果
5.2.2 何时进行基准测试
分析整个java程序的性能要比分析一小段代码更有效
微基准测试或底层代码分析应用的场景:
1. 通用库代码
2. JDK开发人员
3. 对延迟极为敏感的代码
微基准测试的可怕之处在于,他们总是会给出一个数字,即使这个数字毫无意义,他们确实测量了某个事物,只是我们并不知道测试的是什么。---- Brian Goetz
以下的情况才有可能用到微基准测试:
1. 代码执行时间小于1毫秒或100微秒;
2. 测量过的内存分配率,小于1Mb/s,最好是接近于0;
3. 使用了100%的可用CPU,且系统利用率一直比较低;
4. 已经使用了执行剖析器来了解了正在消耗CPU的方法的分布情况;
微基准测试是一种高级且很少使用的技术
? 我为啥要看这个。。。。
任何没有进行过反汇编和代码生成分析的nano级别基准测试都是不可信的,言尽于此。----Aleksey Shipilev
5.2.3 JMH 框架
JMH是一个JAVA工具,用于构建,运行和分析用JAVA和其他以JVM为目标平台的语言编写nano/micro/milli/macro基准测试。----OpenJDK
5.2.4 执行基准测试
生成项目框架
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DartifactId=jmh-study \
-Dversion=1.0 \
-DgroupId=com.github.yfge生成的基本代码如下:
@Benchmark
public void testMethod() {
// This is a demo/sample template for building your JMH benchmarks. Edit as needed.
// Put your benchmark code here.
}JMH特性:可以通过配置参数来控制其执行
public static void main(String[] args) {
Options opt = new OptionsBuilder().include(MyBenchmark.class.getSimpleName())
.warmupIterations(100)
.measurementIterations(5)
.forks(1)
.jvmArgs("-server", "-Xms2048m", "-Xmx2048m")
.build();
try {
new Runner(opt).run();
} catch (RunnerException e) {
e.printStackTrace();
}
}命令行上的参数会覆盖main()方法中设置的参数值
JMH特性:状态以及控制状态
可以用@State注解来定义该状态,并接受Scope枚举来定义状态可见范围(Group,Benchmark,Thread)
JMH特性:防止JVM移除代码
如果一个代码执行没有副作用并且返回的值也不影响方法的返回,JVM会将其优化掉。
JMH提供了黑洞(BlackHole) 机制来避免这种情况。 BlackHole 提供了4种与优化相关的保护,以避免优化影响测试:
1. 防止运行时把死代码优化掉;
2. 防止重复计算被折叠成常量;
3. 防止伪共享,读写值个值会影响当前的高速缓存运行;
4. 避免写墙(Write Wall)
墙----指资源已经饱和并且事实上造成了应用程序的瓶颈。如果命中写墙,会影响高速缓存并污染缓冲区。
BlackHole的两段避免优化的代码:
public volatile int i1=1,i2=2;
/**
* 消耗对象。该调用有一个副作用,可以防止JIT消除我们要依赖的计算。
* @param i 要消耗的int
*/
public final void consume(int i){
if (i ==i1 & i ==i2){
//不该发生
mullBait.i1 = i; //隐含空指针异常
}
}1. 变量声明为
volatile,表明运行时必须重新计算;2.
if语句永远不可能为真,但编译器必须保证代码运行;3. 使用按位与&,避免了额外的分支,同时保证了性能;
JMH特性
• 能够控制编译器
使用
@CompileControl要求编译器不内联,明确内联或从编译中排除该方法。• 在基准测试期间模拟CPU利用水平
使用
BlackHole消耗CPU周期。
基准测试的一个demo
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
@Fork(1)
public class MyBenchmark {
private static final int N = 1_000;
private static final List<Integer> testData = new ArrayList<>();
@Setup
public static final void setup() {
Random random = new Random();
for (int i = 0; i < N; i++) {
testData.add(random.nextInt(Integer.MAX_VALUE));
}
System.out.println("Setup Complete.");
}
@Benchmark
public List<Integer> classicSort() {
List<Integer> copy = new ArrayList<>(testData);
Collections.sort(copy);
return copy;
}
@Benchmark
public List<Integer> standardSort() {
return testData.stream().sorted().collect(Collectors.toList());
}
@Benchmark
public List<Integer> parallelSort() {
return testData.parallelStream().sorted().collect(Collectors.toList());
}
public static void main(String[] args) {
Options opt = new OptionsBuilder().include(MyBenchmark.class.getSimpleName())
.warmupIterations(100)
.measurementIterations(5)
.forks(1)
.jvmArgs("-server", "-Xms2048m", "-Xmx2048m")
.addProfiler(GCProfiler.class)
.addProfiler(StackProfiler.class)
.build();
try {
new Runner(opt).run();
} catch (RunnerException e) {
e.printStackTrace();
}
}
}输出:
# JMH version: 1.35
# VM version: JDK 16.0.1, OpenJDK 64-Bit Server VM, 16.0.1+9-24
# VM invoker: /Users/geyunfei/Library/Java/JavaVirtualMachines/openjdk-16.0.1/Contents/Home/bin/java
# VM options: -server -Xms2048m -Xmx2048m
# Blackhole mode: full + dont-inline hint (auto-detected, use -Djmh.blackhole.autoDetect=false to disable)
# Warmup: 100 iterations, 1 s each
# Measurement: 5 iterations, 1 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Throughput, ops/time
# Benchmark: com.github.yfge.MyBenchmark.classicSort
# Run progress: 0.00% complete, ETA 00:05:15
# Fork: 1 of 1
# Warmup Iteration 1: Setup Complete.
13371.976 ops/s
# Warmup Iteration 2: 17069.648 ops/s
# Warmup Iteration 3: 17547.192 ops/s
# Warmup Iteration 4: 17002.185 ops/s
# Warmup Iteration 5: 17657.026 ops/s
# Warmup Iteration 6: 17350.780 ops/s
# Warmup Iteration 7: 16966.759 ops/s
# Warmup Iteration 8: 17201.778 ops/s加入GC的输出
# Run progress: 0.00% complete, ETA 00:05:15
# Fork: 1 of 1
[0.007s][info][gc] Using G1
# Warmup Iteration 1: Setup Complete.
[2.061s][info][gc] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 102M->2M(2048M) 9.230ms
13045.460 ops/s
# Warmup Iteration 2: 15182.546 ops/s
# Warmup Iteration 3: [3.772s][info][gc] GC(1) Pause Young (Normal) (G1 Evacuation Pause) 128M->2M(2048M) 4.227ms
15369.810 ops/s
# Warmup Iteration 4: 15150.795 ops/s
# Warmup Iteration 5: [7.275s][info][gc] GC(2) Pause Young (Normal) (G1 Evacuation Pause) 265M->2M(2048M) 3.309ms
15220.751 ops/s
# Warmup Iteration 6: 16233.202 ops/s
# Warmup Iteration 7: 15102.771 ops/s
# Warmup Iteration 8: 15569.647 ops/s5.3 JVM性能统计
我们信奉上帝,其他人请用数据说话。----MichaelBloomberg
5.3.1 误差类型
系统性误差
某个不明因素在以一种相关的方式影响可观测的测量。
随机性误差
某个测量误差或不相关的因素以不相关的方式影响了结果。
通常认为随机误差遵循正太分布,但这并不适用JVM
假相关
相关性不代表因果性
5.3.2 非正态统计
性能统计更多为长尾分布。所以经常使用百分位进行统计。
长尾分布可以称为高动态范围分布(High Dynamic Range Distribution) ,观测值的范围通常定义为最大记录值除以最小记录值。
可以用maven库HdrHistoram库来处理高动态分布的数据集,同时会有相应的展示工具。
5.4 统计的解释
无论他们告诉你们什么,都是人的问题。----Gerald Weinberg
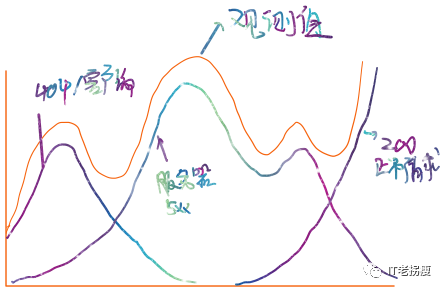
例:对服务器请求时间的直方图:
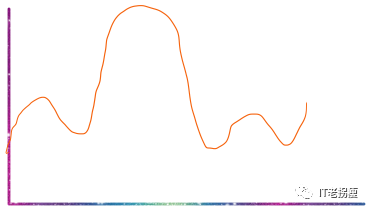
统计客户端错误(404)直方图:
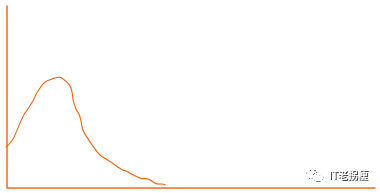
统计服务端错误(5XX)直方图:
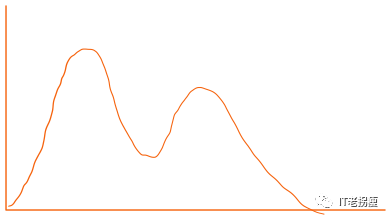
统计成功请求的(200)的直方图:
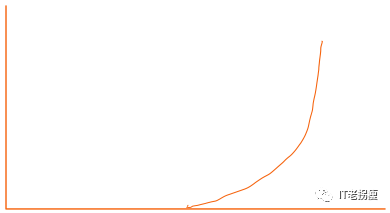
实际走向:















 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









