







 本文介绍了如何使用Jsoup库解析HTML,包括下载Jsoup、解析网页以获取图片下载地址、图片列表页面及分页链接。通过实例展示了获取图片名、下载图片的完整流程,详细解析了实现步骤和代码实现。
本文介绍了如何使用Jsoup库解析HTML,包括下载Jsoup、解析网页以获取图片下载地址、图片列表页面及分页链接。通过实例展示了获取图片名、下载图片的完整流程,详细解析了实现步骤和代码实现。
之前已经发表过一篇使用HtmlParser类来解析视频网站的教程
我发现htmlparser类太旧了,而且用起来语法也不清晰。
所以我又找来一个更强大的解析网页的工具类:Jsoup 来帮助我们制作更强大的网络爬虫
下载Jsoup类
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jar包地址:
构建Maven项目自动下载jar包:
Jsoup在线API文档:
Jsoup开发指南:
解析网页
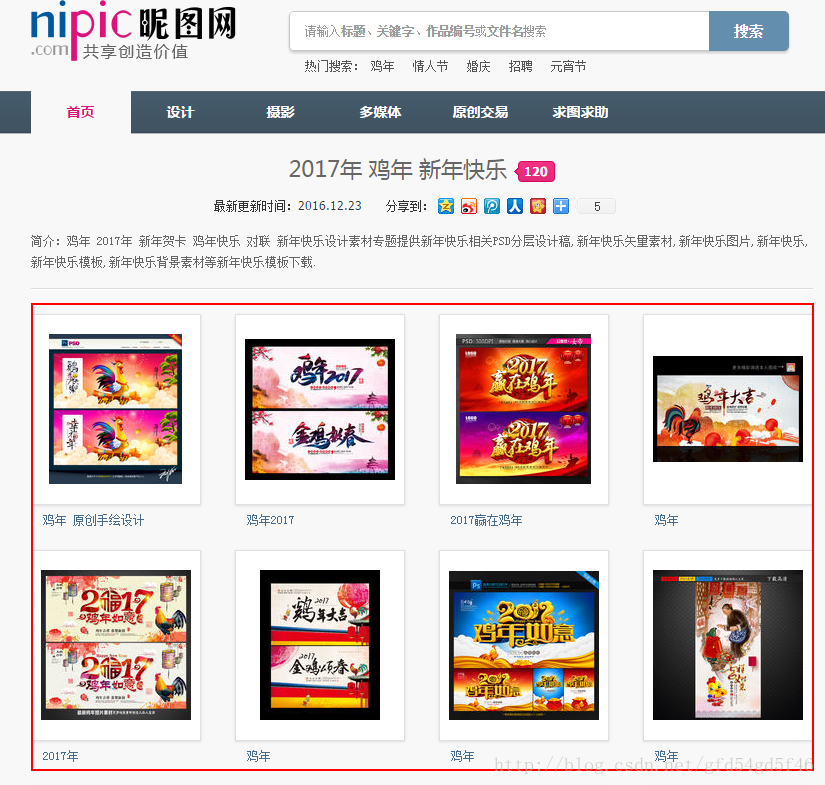
我这里就找一个图片网站来进行测试
1、获取单张图片的下载地址
- 随便点击一张首页的图片

进去之后我们发现这个页面只是图片的列表,我们要获取的是单个图片的地址,所以还需要点击进去查找
点击第一张图片,查看到了单张图片
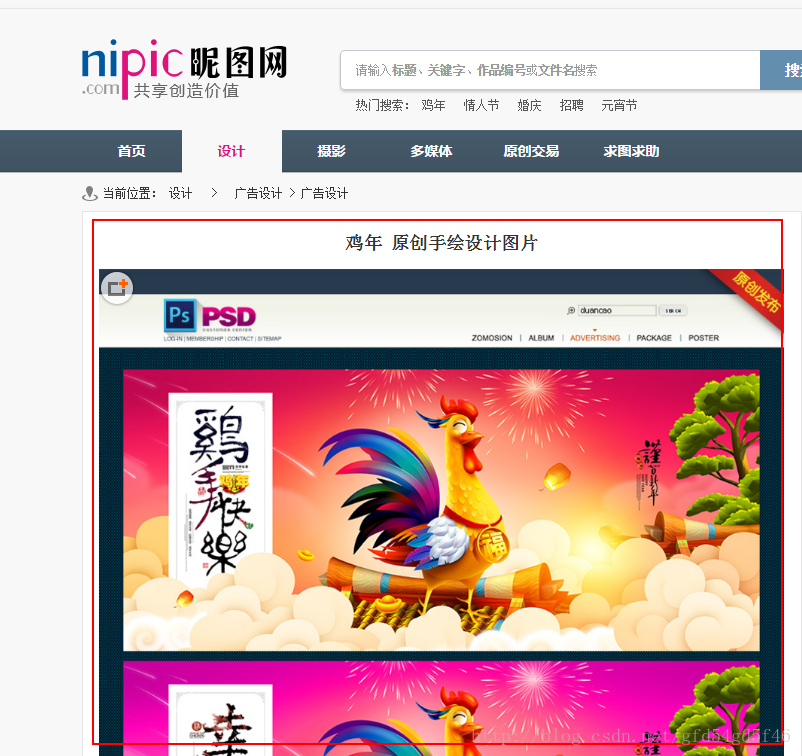
同样,我们要对这个页面进行分析,找到规律来获取这张图片的地址链接
F12进入调试页面
观察规律发现:
图片的下载地址在src属性下
图片有个唯一的id属性:J_worksImg
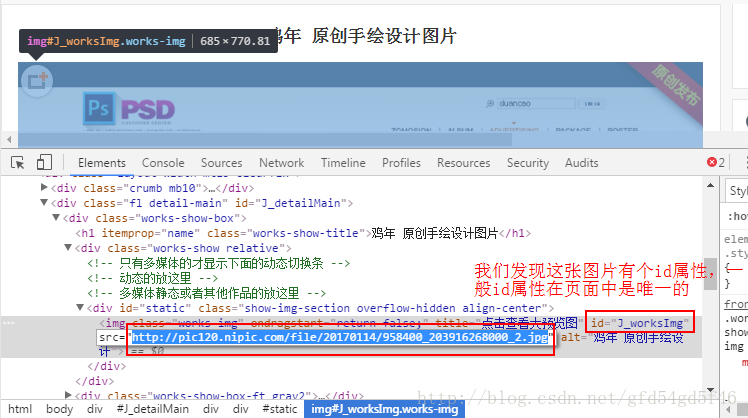
找到规律后,我们就来使用Jsoup来获取一下图片的下载地址
- 代码实现:
/**
* 通过子页面链接(图片网页)获取到图片下载地址
* "http://www.nipic.com/show/16519633.html"
* @return downloadPicUrl
*/
public static List<String> getPicDownUrlFromAllPicPage(String url) {
//保存图片的下载地址
List<String> list = new ArrayList<String>();
try {
//通过传入一个url打开一个链接并且获取内容,将内容存到文件中
Document doc = Jsoup.connect(url).get();
//如果文档不为空 && 页面中没有出现 “唔,未找到任何页面!!!” 则认为该页面是个正常页面
if (doc != null && !Jsoup.connect(url).get().html().contains("唔,未找到任何页面!!!")) {
//获取到网页的唯一的id元素
Element element = doc.getElementById("J_worksImg");
//判断元素不为空 && src里面的内容不为空
if (element != null && !element.attr("src").equals("")) {
//将图片地址添加到集合中
list.add(element.attr("src"));
}
}
} catch (IOException e) {
e.printStackTrace();
}
//http://pic120.nipic.com/file/20170114/958400_203916268000_2.jpg
return list;
}
Main方法()
public static void  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









