







先贴一份印度码农向他老婆解释MapReduce的文章,挺有意思的。
昨天,我在Xebia印度办公室发表了一个关于MapReduce的演说。演说进行得很顺利,听众们都能够理解MapReduce的概念(根据他们的反馈)。我成功地向技术听众们(主要是Java程序员,一些Flex程序员和少数的测试人员)解释了MapReduce的概念,这让我感到兴奋。在所有辛勤的工作之后,我们在Xebia印度办公室享用了丰盛的晚餐,然后我径直回了家。
回家后,我的妻子(Supriya)问道:“你的会开得怎么样?”我说还不错。 接着她又问我会议是的内容是什么(她不是从事软件或编程领域的工作的)。我告诉她说MapReduce。“Mapduce,那是什么玩意儿?”她问道: “跟地形图有关吗?”我说不,不是的,它和地形图一点关系也没有。“那么,它到底是什么玩意儿?”妻子问道。 “唔…让我们去Dominos(披萨连锁)吧,我会在餐桌上跟你好好解释。” 妻子说:“好的。” 然后我们就去了披萨店。
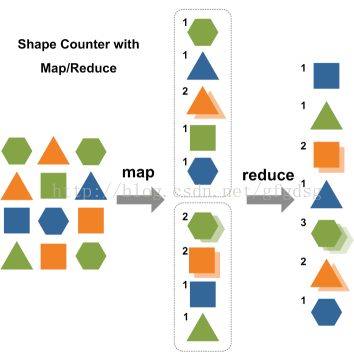
我们在Domions点餐之后,柜台的小伙子告诉我们说披萨需要15分钟才能准备好。于是,我问妻子:“你真的想要弄懂什么是MapReduce?” 她很坚定的回答说“是的”。 因此我问道:
我: 你是如何准备洋葱辣椒酱的?(以下并非准确食谱,请勿在家尝试)
妻子: 我会取一个洋葱,把它切碎,然后拌入盐和水,最后放进混合研磨机里研磨。这样就能得到洋葱辣椒酱了。
妻子: 但这和MapReduce有什么关系?
我: 你等一下。让我来编一个完整的情节,这样你肯定可以在15分钟内弄懂MapReduce.
妻子: 好吧。
我:现在,假设你想用薄荷、洋葱、番茄、辣椒、大蒜弄一瓶混合辣椒酱。你会怎么做呢?
妻子: 我会取薄荷叶一撮,洋葱一个,番茄一个,辣椒一根,大蒜一根,切碎后加入适量的盐和水,再放入混合研磨机里研磨,这样你就可以得到一瓶混合辣椒酱了。
我: 没错,让我们把MapReduce的概念应用到食谱上。Map和Reduce其实是两种操作,我来给你详细讲解下。
Map(映射): 把洋葱、番茄、辣椒和大蒜切碎,是各自作用在这些物体上的一个Map操作。所以你给Map一个洋葱,Map就会把洋葱切碎。 同样的,你把辣椒,大蒜和番茄一一地拿给Map,你也会得到各种碎块。 所以,当你在切像洋葱这样的蔬菜时,你执行就是一个Map操作。 Map操作适用于每一种蔬菜,它会相应地生产出一种或多种碎块,在我们的例子中生产的是蔬菜块。在Map操作中可能会出现有个洋葱坏掉了的情况,你只要把坏洋葱丢了就行了。所以,如果出现坏洋葱了,Map操作就会过滤掉坏洋葱而不会生产出任何的坏洋葱块。
Reduce(化简):在这一阶段,你将各种蔬菜碎都放入研磨机里进行研磨,你就可以得到一瓶辣椒酱了。这意味要制成一瓶辣椒酱,你得研磨所有的原料。因此,研磨机通常将map操作的蔬菜碎聚集在了一起。
妻子: 所以,这就是MapReduce?
我: 你可以说是,也可以说不是。 其实这只是MapReduce的一部分,MapReduce的强大在于分布式计算。
妻子: 分布式计算? 那是什么?请给我解释下吧。
我: 没问题。
我: 假设你参加了一个辣椒酱比赛并且你的食谱赢得了最佳辣椒酱奖。得奖之后,辣椒酱食谱大受欢迎,于是你想要开始出售自制品牌的辣椒酱。假设你每天需要生产10000瓶辣椒酱,你会怎么办呢?
妻子: 我会找一个能为我大量提供原料的供应商。
我:是的..就是那样的。那你能否独自完成制作呢?也就是说,独自将原料都切碎? 仅仅一部研磨机又是否能满足需要?而且现在,我们还需要供应不同种类的辣椒酱,像洋葱辣椒酱、青椒辣椒酱、番茄辣椒酱等等。
妻子: 当然不能了,我会雇佣更多的工人来切蔬菜。我还需要更多的研磨机,这样我就可以更快地生产辣椒酱了。
我:没错,所以现在你就不得不分配工作了,你将需要几个人一起切蔬菜。每个人都要处理满满一袋的蔬菜,而每一个人都相当于在执行一个简单的Map操作。每一个人都将不断的从袋子里拿出蔬菜来,并且每次只对一种蔬菜进行处理,也就是将它们切碎,直到袋子空了为止。
这样,当所有的工人都切完以后,工作台(每个人工作的地方)上就有了洋葱块、番茄块、和蒜蓉等等。
妻子:但是我怎么会制造出不同种类的番茄酱呢?
我:现在你会看到MapReduce遗漏的阶段—搅拌阶段。MapReduce将所有输出的蔬菜碎都搅拌在了一起,这些蔬菜碎都是在以key为基础的 map操作下产生的。搅拌将自动完成,你可以假设key是一种原料的名字,就像洋葱一样。 所以全部的洋葱keys都会搅拌在一起,并转移到研磨洋葱的研磨器里。这样,你就能得到洋葱辣椒酱了。同样地,所有的番茄也会被转移到标记着番茄的研磨器里,并制造出番茄辣椒酱。
披萨终于做好了,她点点头说她已经弄懂什么是MapReduce了。我只希望下次她听到MapReduce时,能更好的理解我到底在做些什么。
编注:下面这段话是网上其他人用最简短的语言解释MapReduce:
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes.
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
Now we get together and add our individual counts. That’s reduce.
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
正文:
MapReduce作业运行流程
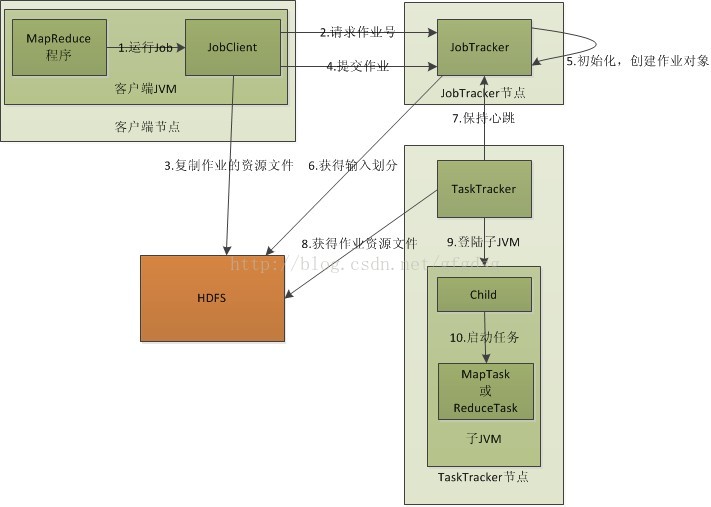
流程分析:
1.在客户端启动一个作业。
2.向JobTracker请求一个Job ID。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
2.Map、Reduce任务中Shuffle和排序的过程
同样贴出我在visio中画出的流程示意图:

流程分析:
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









