







目录
一、概念
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
总结:MapReduce是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为Map和Reduce两个阶段的编程模型。
MapReduce核心思想:分而治之
二、MapReduce计算模型
MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。
Map是映射,负责数据的过滤分法,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,而这个将Map输出进行进一步整理并交给Reduce的过程就是Shuffle。整个MR的大致过程如下:
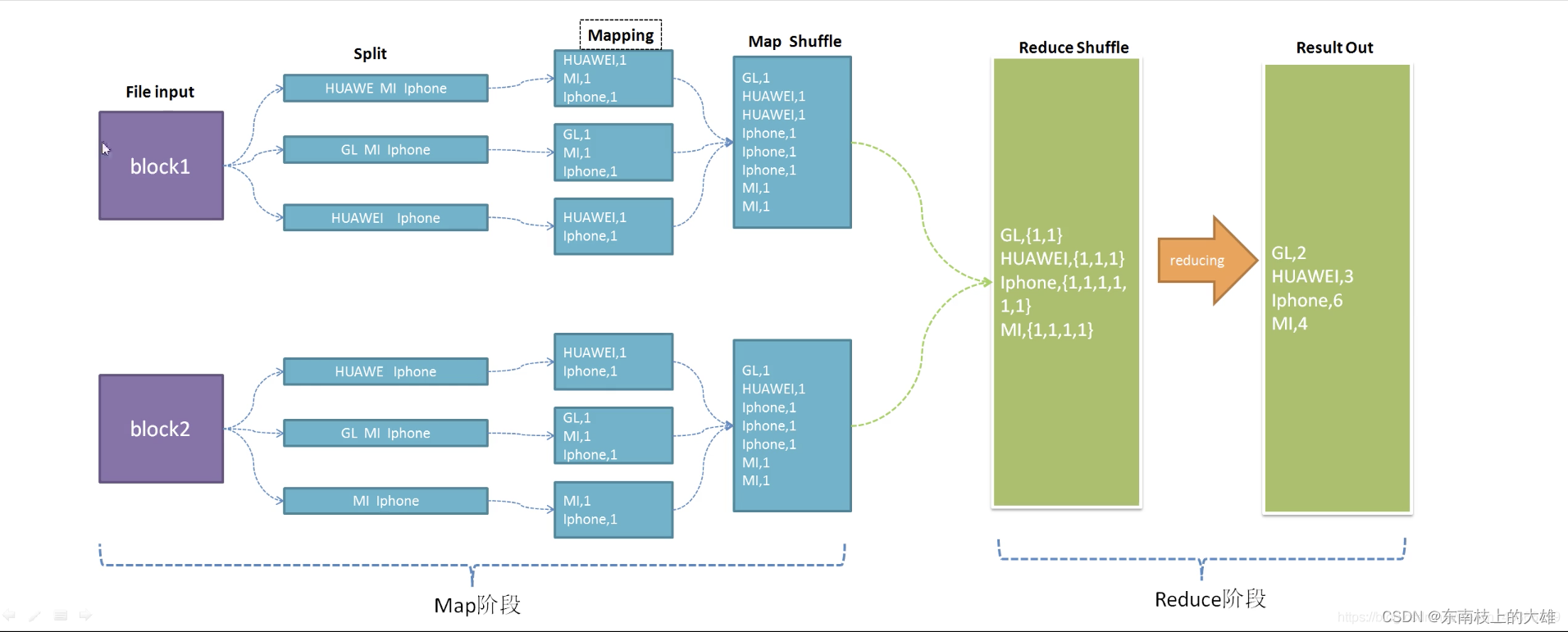
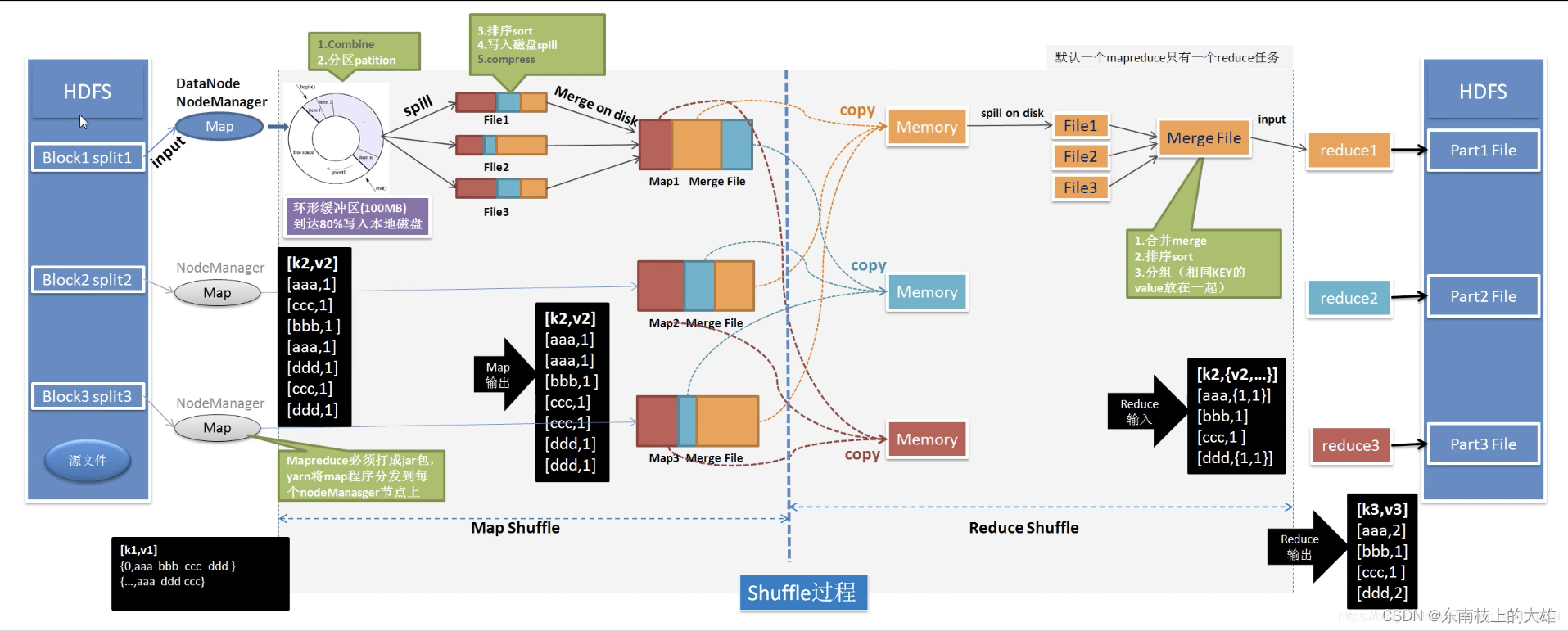
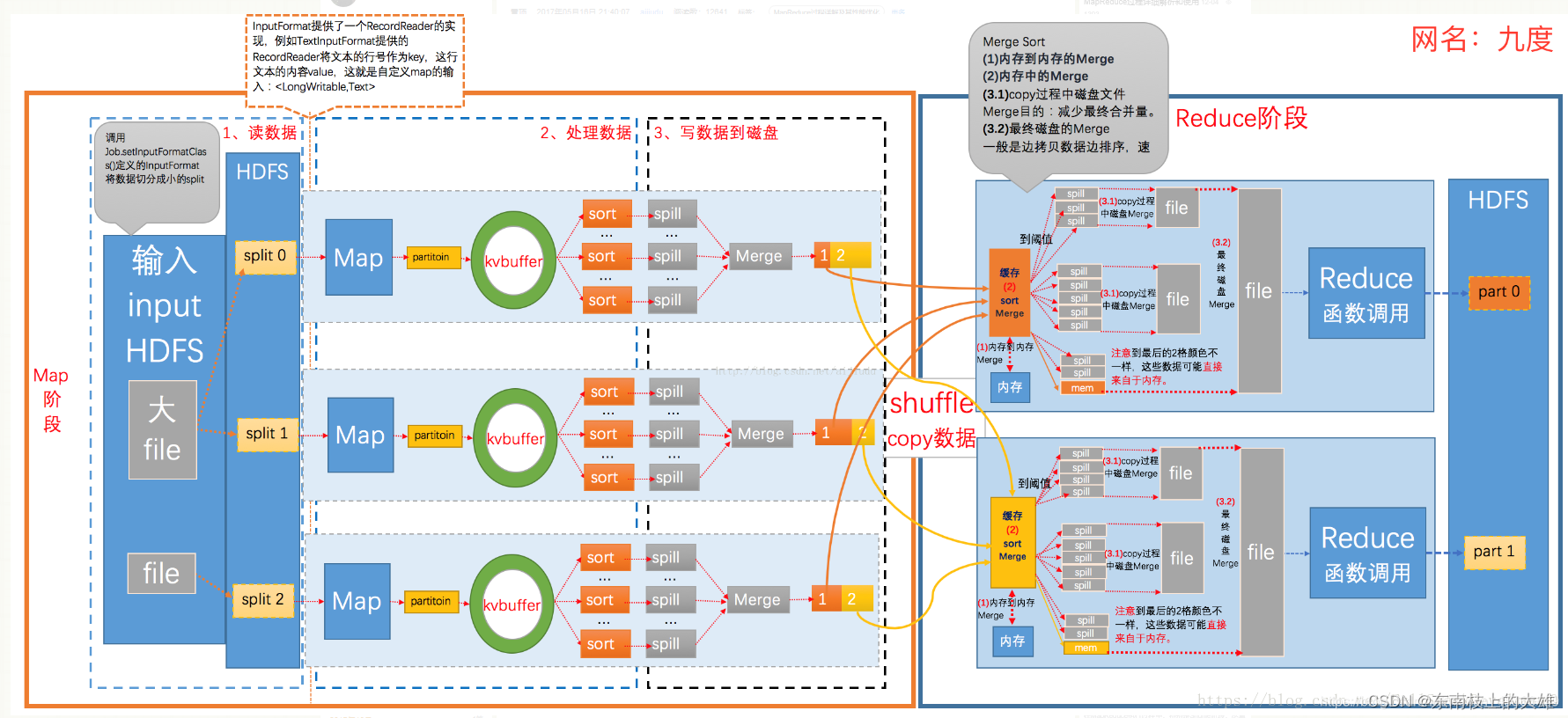
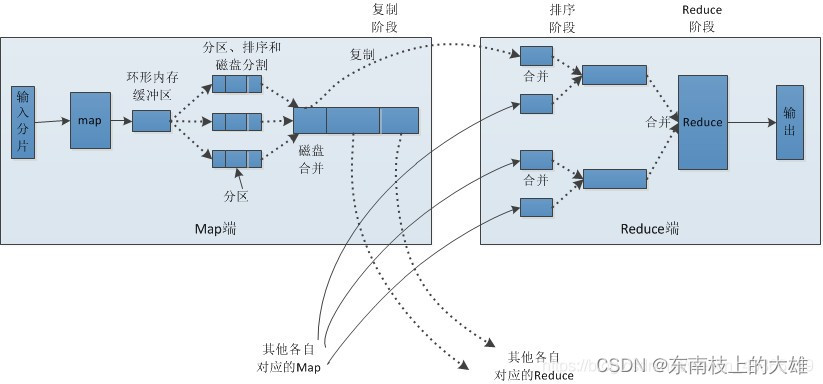
Map和Reduce操作需要我们自己定义相应Map类和Reduce类,以完成我们所需要的化简、合并操作,而shuffle则是系统自动帮我们实现的,了解shuffle的具体流程能帮助我们编写出更加高效的Mapreduce程序。
Shuffle是MR处理流程中的一个过程,它的每一步处理步骤是分散在各个map task和reduce task 节点上完成的。
三、执行流程
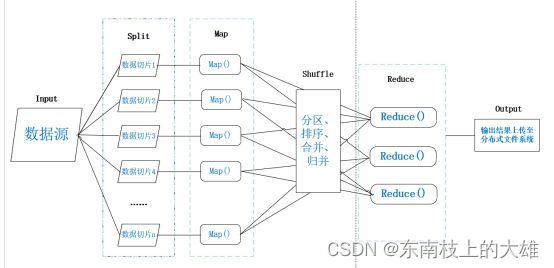
如图展示的就是MapReduce的工作过程,一共分为input、split、map、shuffle、reduce、output六个阶段。我们用作三明治的例子演示一下MapReduce的工作流程:
√ input阶段相当于准备食材的步骤;
√ split阶段相当于分食材的步骤,数据切片1表示面包、数据切片2表示培根、数据切片3表示西红柿、数据切片4表示生菜;
√ map阶段相当于切面包、煎培根、切西红柿、洗生菜四个步骤同时进行;
√ shuffle阶段相当于把切好的食材分类,存放、汇总;
√ reduce阶段相当于整合组装成三明治;
√ output阶段相当于打包。
有了这个通俗易懂的例子加上前面map函数和reduce函数的介绍,我们再来理解MapReduce的工作过程就很轻松了。
- input 阶段:一个路径下的文件交给FileInputFormat
- split 阶段: FileInputFormat拿到文件计算切片,(不人为干涉,切片最小为0,最大为整数型的最大值,正常情况下为blocksize,计算切片大小computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M)
- map 阶段: 一个切片起一个map,如存在3和切片则启动3个map,3个map对于切片的处理是并行的,启动RecordReader对切片处理,每一次读一行,返回(key,value)(k:行首偏移量,v:行的内容),读取出来后每一行都给到mapper端的map进程中的map方法,经过逻辑处理形成新的(k,v),通过context.write输出到OutputCollector收集器。
- shuffle 阶段:收集器再把收集到的(k,v)键值对写到环形缓冲区(默认100M,可以复用的内存空间),只写80%,当环形缓冲区里面的数据达到80%,会触发spill溢出(写入数据与溢写数据也为并发,每溢写一次生成一个文件),溢出前对数据进行处理:分区有序,分区内键有序;分区:int partNo = key.hashcode()%job.getNumReduceTasks();排序,外部排序,快排。 此时若map阶段处理数据量较大会溢出多个文件,此时会被merge归并排序成大的溢出文件。
- reduce 阶段:reduce task根据自己的分区编号去各个map task节点上拷贝相同的分区数据到reduce task本地磁盘工作目录,此时多个分区文件会再次归并排序成一个大文件,文件内键有序。至此shuffle阶段结束,进入reduce task的逻辑运算过程。此时,首先对大文件里的数据进行分组处理,从文件中每取出一组(k,v),都会调用reduce()进行逻辑处理。
- output 阶段:发给OutPutFormat,将结果写入"part-r-000"结果文件中(分布式文件系统,即HDFS)
(注意:1.若存在combiner,溢写文件时,在同一个分区内,相同的键会被合并起来。
2.shuffle 阶段是MP处理流程的一个过程,它的每一个处理步骤分散在各个map task和reduce task节点上完成的,整体来看,分为3个步骤:1、分区:int partNo = key.hashcode()%job.getNumReduceTasks()。2、sort根据key排序,外部排序,快排 。3、Combiner进行局部value的并合)
- 如有错误,欢迎大佬指正,感激不尽!















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









