






前言
excel导入数据是开发中再正常不过的事,但是对于复杂表头的excel导入的处理,单纯使用java进行开发还是一件比较有难度的事情的,下面我将介绍自己在工作中遇到的多层次复杂excel的导入
首先来看一下我们需要导入的excel文件的内容:
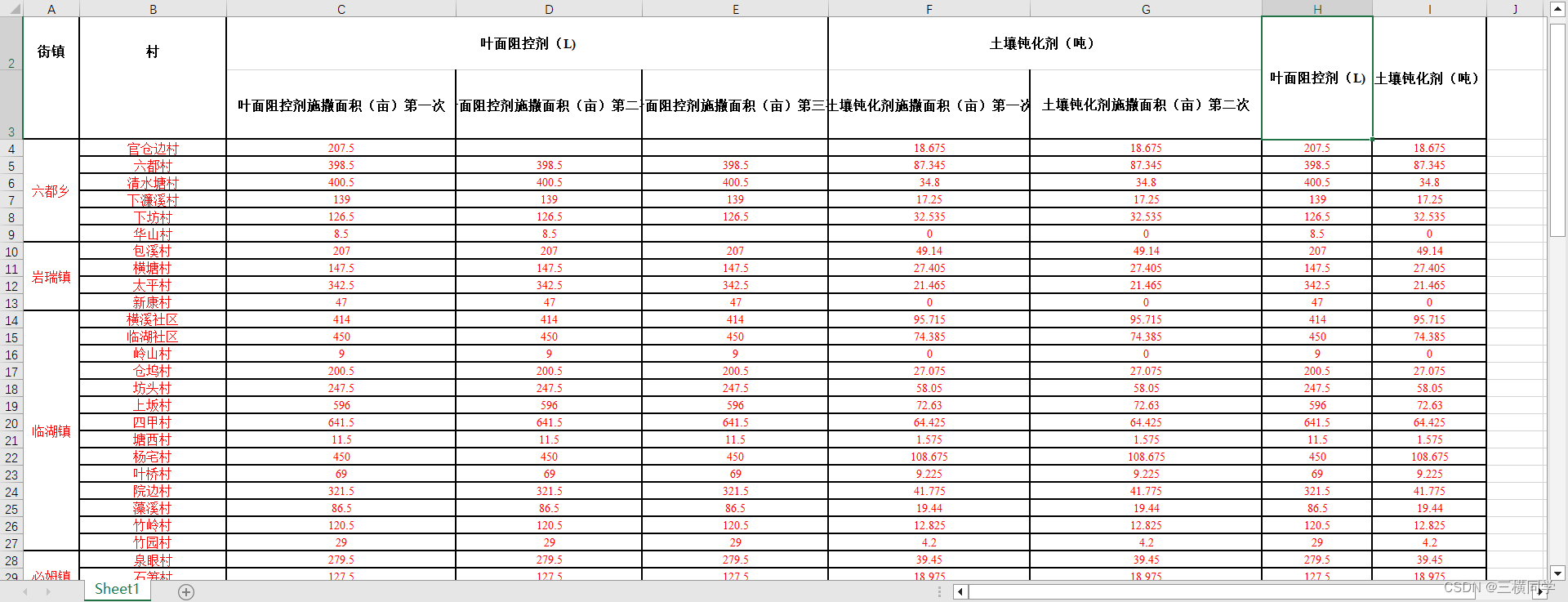
模板说明:
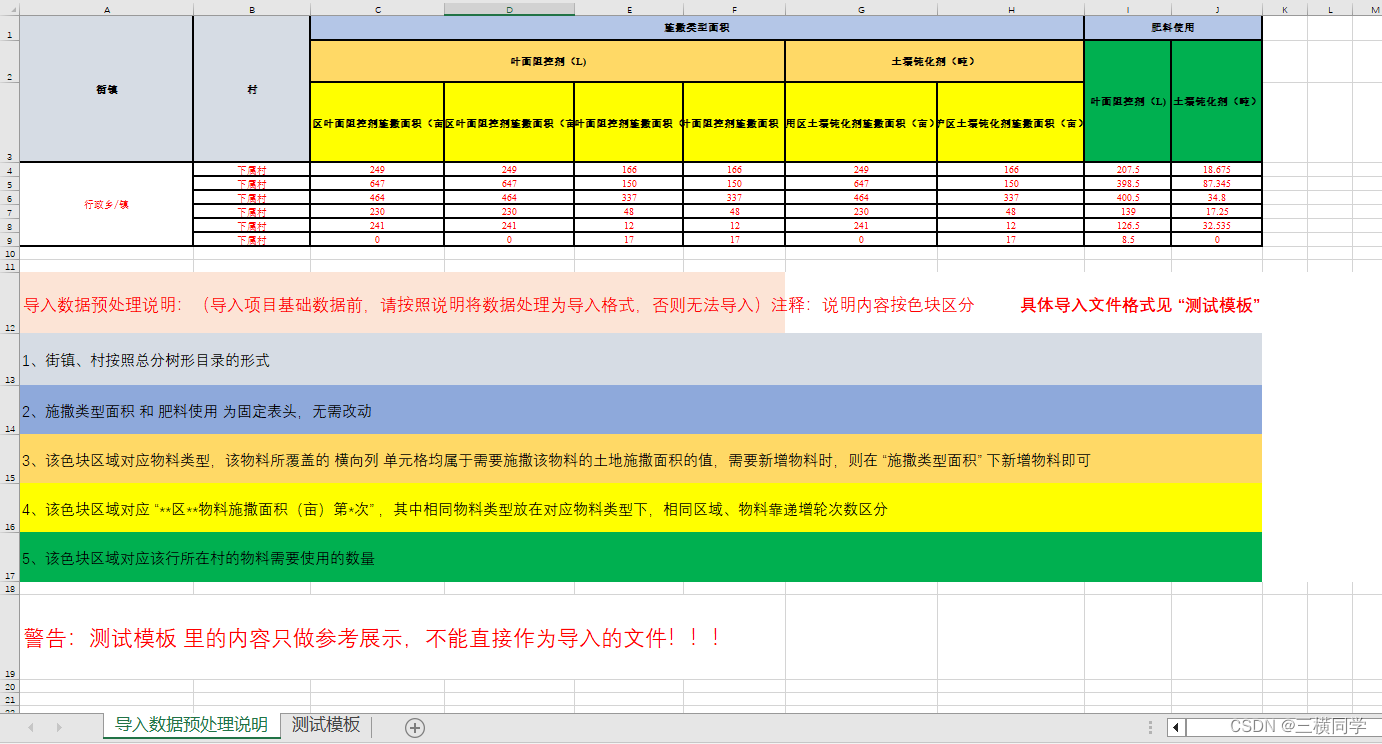
简单说明:这张excel表数据分为三类即乡镇、面积、用量且需要将这一张excel的数据导入到三张不同的数据库表中,且自动维护好这三种表之间为联系 总体来说还是比较复杂的excel导入
代码实现
controller:
/**
* 耕地项目初始信息excel导入
* @param multipartFile
* @return
*/
@PostMapping(value = "/import")
public R restoreImport(@RequestParam("file") MultipartFile multipartFile){
System.out.println("获取到的租户id为:"+TenantContextHolder.getTenantId());
// TenantContextHolder.setTenantId(1799005981370114049L);
System.out.println("修改后的租户id为:"+TenantContextHolder.getTenantId());
try{
EasyExcel.read(multipartFile.getInputStream(), new MultiLevelHeaderListener(restoreRegionService,restoreLandService,restoreMatterService))
.extraRead(CellExtraTypeEnum.MERGE)
.sheet() // 读取第一个sheet
.headRowNumber(3)
.doRead();
}catch (Exception e){
e.printStackTrace();
return R.failed("导入异常,请联系管理员!");
}
return R.ok();
}
Listener:
package com.wlh.zetc.restore.Listener;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.enums.CellExtraTypeEnum;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.excel.metadata.CellExtra;
import com.alibaba.excel.metadata.CellRange;
import com.alibaba.excel.util.ListUtils;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.wlh.zetc.restore.entity.RestoreRegionEntity;
import com.wlh.zetc.restore.service.RestoreLandService;
import com.wlh.zetc.restore.service.RestoreMatterService;
import com.wlh.zetc.restore.service.RestoreRegionService;
import java.util.*;
import java.util.stream.Collectors;
public class MultiLevelHeaderListener extends AnalysisEventListener<Map<Integer, String>> {
private final RestoreRegionService restoreRegionService;
private final RestoreLandService restoreLandService;
private final RestoreMatterService restoreMatterService;
private static final int BATCH_COUNT = 3000;
private List<Map<Integer, String>> headerList = new ArrayList<>(BATCH_COUNT);
private List<CellRange> cellRangeList = new ArrayList<>(BATCH_COUNT);
private List<Map<Integer, String>> dataColumnList = new ArrayList<>(BATCH_COUNT);
//分割下标
private int separateRowIndex = 0;
private int maxRowValue = 0;
public MultiLevelHeaderListener(RestoreRegionService restoreRegionService, RestoreLandService restoreLandService, RestoreMatterService restoreMatterService) {
this.restoreRegionService = restoreRegionService;
this.restoreLandService = restoreLandService;
this.restoreMatterService = restoreMatterService;
}
@Override
public void invoke(Map<Integer, String> data, AnalysisContext context) {
dataColumnList.add(new HashMap<>(data));
if (dataColumnList.size() >= BATCH_COUNT) {
doAfterAllAnalysed(context);
dataColumnList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
headerList.add(new HashMap<>(headMap));
if (headerList.size() >= BATCH_COUNT) {
doAfterAllAnalysed(context);
headerList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void extra(CellExtra extra, AnalysisContext context) {
if (extra.getType() == CellExtraTypeEnum.MERGE) {
cellRangeList.add(new CellRange(extra.getFirstRowIndex(), extra.getLastRowIndex(),
extra.getFirstColumnIndex(), extra.getLastColumnIndex()));
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
//多层次列表头处理
mergeHeaderCells(headerList);
//列表数据处理
mergeDataColumnCells(dataColumnList);
//数据分割点获取
getSplitPoint();
//数据处理完后进行存储
save();
}
private void mergeHeaderCells(List<Map<Integer, String>> dataList) {
int maxColumnIndex = cellRangeList.stream()
.mapToInt(CellRange::getLastCol)
.max()
.orElse(-1);
for (Map<Integer, String> row : dataList) {
for (int i = 0; i <= maxColumnIndex; i++) {
row.putIfAbsent(i, null);
}
}
for (CellRange cellRange : cellRangeList) {
int firstRow = cellRange.getFirstRow();
int firstCol = cellRange.getFirstCol();
if (firstRow < dataList.size()) {
String mergedValue = dataList.get(firstRow).get(firstCol);
for (int rowIndex = firstRow; rowIndex <= cellRange.getLastRow(); rowIndex++) {
if (rowIndex < dataList.size()) {
Map<Integer, String> dataRow = dataList.get(rowIndex);
for (int colIndex = firstCol; colIndex <= cellRange.getLastCol(); colIndex++) {
dataRow.put(colIndex, mergedValue);
}
}
}
}
}
}
private void mergeDataColumnCells(List<Map<Integer, String>> dataList) {
int maxRowIndex = dataList.get(0).size() - 1;
maxRowValue = maxRowIndex;
for (int colIndex = 0; colIndex <= maxRowIndex; colIndex++) {
String mergedValue = dataList.get(0).get(colIndex);
for (int rowIndex = 1; rowIndex < dataList.size(); rowIndex++) {
String currentValue = dataList.get(rowIndex).get(colIndex);
if (currentValue != null && !currentValue.isEmpty()) {
mergedValue = currentValue;
}
dataList.get(rowIndex).put(colIndex, mergedValue);
}
}
}
private void getSplitPoint() {
//获取施撒类型面积与肥料使用所分割的单元格位置
System.out.println("获取分割点下标:");
int lastIndex = headerList.get(0).entrySet().stream()
.filter(entry -> "施撒类型面积".equals(entry.getValue()))
.map(Map.Entry::getKey)
.reduce((first, second) -> second)
.orElse(-1);
separateRowIndex = lastIndex;
System.out.println("下标点位为:"+separateRowIndex);
}
private void streetTownSave(){
// 对街镇进行提取和去重
List<String> filteredDataDistinct = dataColumnList.stream()
.map(row -> row.get(0)) // 获取第一个字段的数据
.filter(value -> value != null && !value.isEmpty()) // 进行过滤处理
.distinct() // 进行去重处理
.collect(Collectors.toList()); // 返回List<String>
restoreRegionService.streetTownInitialize(filteredDataDistinct);
}
private void villageAndDataSave(){
//数据分组处理
Map<String, List<Map<Integer, String>>> groupedData = dataColumnList.stream()
.collect(Collectors.groupingBy(row -> row.get(0)));
// 遍历groupedData
groupedData.forEach((key, value) -> {
RestoreRegionEntity streetTown = restoreRegionService.getOne(Wrappers.<RestoreRegionEntity>lambdaQuery()
.eq(RestoreRegionEntity::getParentId, 0L)
.eq(RestoreRegionEntity::getRegionName, key)
.eq(RestoreRegionEntity::getRegionLevel, String.valueOf(1)));
System.out.println(key+":");
value.forEach(row -> {
RestoreRegionEntity restoreRegion = null;
//存储村信息
if(StringUtils.isNotEmpty(row.get(1))){
restoreRegion = restoreRegionService.villageInitialize(streetTown.getRegionId(), row.get(1));
}
System.out.println("row.get(1):"+row.get(1));
//存储施撒类型面积
for (int i = 2; i <= separateRowIndex; i++){
if (StringUtils.isNotEmpty(row.get(i)) &&
!row.get(i).equals(0) &&
!Objects.isNull(restoreRegion)){
restoreLandService.LandAreaInitialize(restoreRegion,
headerList.get(1).get(i),
headerList.get(2).get(i),
row.get(i));
}
}
//存储肥料使用量
for (int i = separateRowIndex + 1; i <= maxRowValue; i++){
if(StringUtils.isNotEmpty(row.get(i)) &&
!row.get(i).equals(0) &&
!Objects.isNull(restoreRegion))
restoreMatterService.matterInitialize(String.valueOf(restoreRegion.getRegionId()),
headerList.get(1).get(i),
row.get(i));
}
});
});
}
private void save(){
streetTownSave();
villageAndDataSave();
}
}
本代码处理的核心主要在listener类中,将excel分为列表头与数据列两部分处理,在代码的处理顺序与数据逻辑处理都还比较优雅的,具体看代码的实现,代码中包含每步的注释说明

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











