







确认性偏差,或者叫做确认性偏误,Confirmation bias,是个人选择性的回忆和收集对自己有利的情节,忽略不利或者矛盾的资讯,来支持自己已有的想法或者假设。
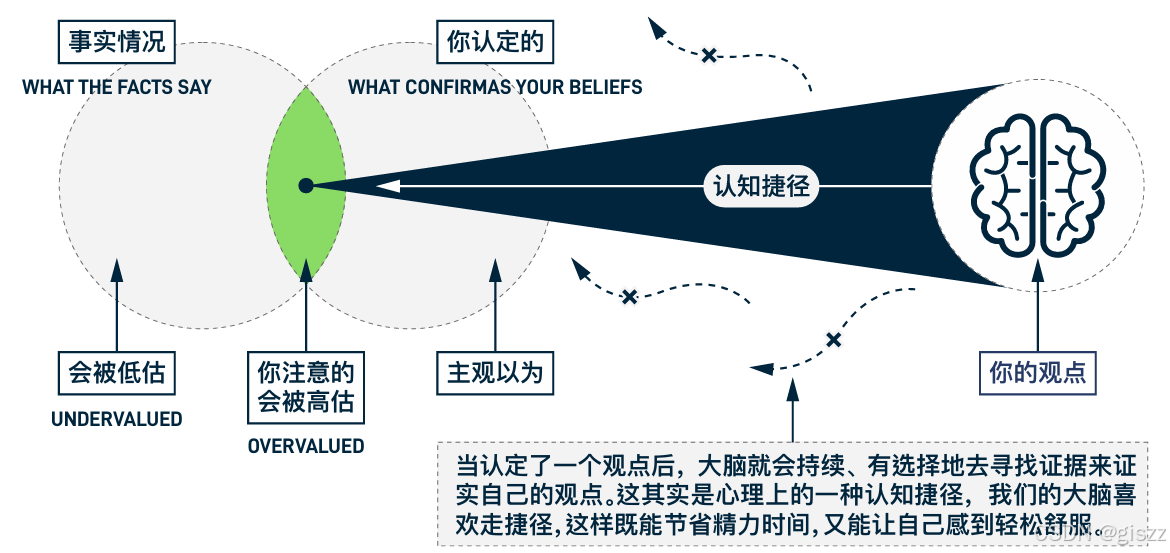
实际上,我们应该去做的,是切断认知认知捷径,能够开放的接收全部的信息,避免做出错误的判断。
现实中,这又何尝不是难上加难!
求同存异,也许是正解。
下面,我们来认识一下这个思维模型。
比「骗子」更危险的是「自我欺骗系统」
确认性偏差(Confirmation Bias):
人类大脑自带的信息过滤系统,会主动搜捕支持已有观点的证据,扭曲矛盾信息,遗忘不利事实,最终在思维茧房中完成自我说服的完整闭环。
当你在某件事上投入越多(时间/金钱/情感),大脑越会开启「证据造假模式」,用诺贝尔经济学奖得主理查德·塞勒的话说:“我们不是用大脑思考,而是用内脏思考。”
四大核心机制与经典战场
1. 信息狩猎:选择性眼盲症
运作机制:
大脑像装了关键词过滤器的搜索引擎,只抓取符合预设结论的数据。
🌰 经典案例:
- 总统选举:支持者A看到候选人的慈善新闻立刻转发,却自动屏蔽其财务丑闻
- 投资踩雷:股民坚信某公司会涨,只关注券商“买入”评级报告,忽视做空机构的19页证据链
- 神经学解释:
- 前额叶皮质启动「认知节能模式」,相比耗能的批判性思考,直接调用既有结论省力80%
2. 解释扭曲:事实裁缝术
运作机制:
对同一事实进行方向性解读,如同在认知暗房冲洗照片时手动调色
🌰 经典实验:
- 斯坦福大学向学生展示死刑是否有效的两组数据
- → 支持者:“数据证明死刑降低犯罪率23%!”
- → 反对者:“同一数据显示司法误判率达11%!”
商业灾难:
柯达工程师早在1975年就发明数码相机,但高管坚信“人们永远需要实体照片”,将技术锁进保险柜
3. 记忆篡改:大脑的PS工厂
- 运作机制:海马体自动编辑记忆细节,使过往经历更贴合当前信念
- 🌰 心理学实验:要求被试回忆911事件细节,2001年与2004年的描述差异率高达53%,且都坚信自己记忆准确
- 职场镜像:创业失败者回忆:“当初明明做过市场调研”(实际只问了3个朋友)
4. 群体极化:认知回音壁效应
运作机制:
当确认性偏差遇到社交圈层,会触发「逆火效应」——越是反驳,信徒越疯狂
🌰 历史教训:
- 麦道夫骗局:华尔街精英们互相确认“他可是纳斯达克主席”,集体忽略监管机构的17次警告
- 元宇宙泡沫:投资人俱乐部里,任何质疑硬件普及率的声音都被踢出群聊
五步破解框架(CIA反情报训练法改编)
1. 安装「逆思维触发器」
在表达观点前强制自问:
- 有什么证据能立刻推翻我的结论?
- 如果是我的死对头,会怎么攻击这个逻辑?
案例:
- 桥水基金创始人达利奥要求员工必须找到至少3个反驳自己观点的证据,否则报告不予受理
2. 构建「魔鬼代言人」机制
重要决策时指定专人扮演反对派,按这个比例分配资源:
- 60%用于推进原计划
- 40%用于证伪原计划
案例:
- 亚马逊高管会议有个空椅子,代表“客户反对意见”,任何忽视用户痛点的方案会被当场否决
3. 建立「反数据崇拜」清单
遇到支持性数据时,必须检查:
- 样本量是否>300?(小样本易出现幸存者偏差)
- 数据源是否有利益关联?
- 是否有人刻意删除不利数据段?
案例:
- 医药公司宣称“某药有效率67%”,但隐藏了“对亚裔群体有效率仅12%”的子集数据
4. 开启「认知版本控制」
给每个重要观点打上时间戳和置信度标签:
观点:比特币将取代黄金
版本号:v2.3
更新时间:2023.9
置信度:65%
证据更新:
- 新增:萨尔瓦多法币化实验(+10%)
- 删减:FTX暴雷事件影响(-15%)
5. 实施「反向信息投喂」
在算法时代主动污染自己的信息食谱:
- 关注5个立场相反的KOL
- 每周抽1小时阅读“最讨厌的媒体”
- 用ChatGPT生成反对自己观点的10条论据
历史级灾难与重生启示录
⚠️灾难现场:
- 诺基亚陨落:工程师持续报告“触摸屏不实用”的问卷,却忽视苹果用户凌晨排队现象
- 次贷危机:评级机构只选择房价上涨时期的数据建模,集体忽略前三次地产周期规律
✅ 重生模板:
- 微软转型:纳德拉强制要求所有产品线必须找到“云计算替代方案”,即使当时Windows占营收70%
- 字节跳动:用A/B测试对抗产品经理的“我觉得用户需要”,数据权重大于高管直觉
哲学家卡尔·波普尔警告:“确信自己掌握真理的人,终将成为真理的掘墓人。”
(未完待续)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











