







第一题:GeekChallege
很像第七届强网杯初赛的fuzz
tips:len(array)=5&&len(passwd)=114
脚本:
from pwn import *
from string import printable
from string import ascii_letters
from string import digits
able=ascii_letters+digits
conn = remote('yuanshen.life', 39484)
non_matching_strings = []
str1=['0']*114
str2=''
for char in printable:
payload = char * 114
conn.recvuntil(b'>')
conn.sendline(payload.encode())
response = conn.recvline().decode().strip()
if response != "000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000":
for n in range(114):
if response[n] == '1':
str1[n]=char
print(payload)
print(response)
non_matching_strings.append(char)
if len(non_matching_strings) == 5:
for j in str1:
str2 += j
print(str2)
conn.sendline(str2.encode())
response1 = conn.recvuntil(b'}').decode().strip()
print(response1)

这里有个坑,就是他密码不是固定的,每次重新连接就会刷新一次五个不同元素的密码
所以我们要在for循环结束之前,能够把全部0变成1的那段payload发出去,防止他刷新密码
第二题:WHO?WHO?WHO
用ziperello工具,爆破密码qweqwe
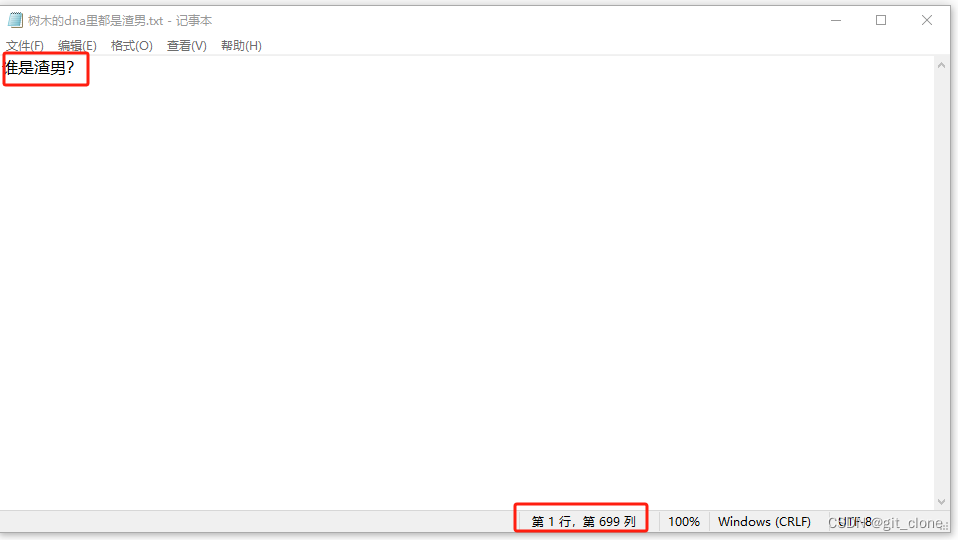
宽字节隐写
谁是渣男??树木是渣男,就解释了为什么后面Rabbit加密的密钥是shumu

注意看开头部分U2FsdGVkX19
rabbit,aes,des这三种可能
shumu应该是呼应txt文件中的人,然后再看到文件名字dna,猜测dna解密
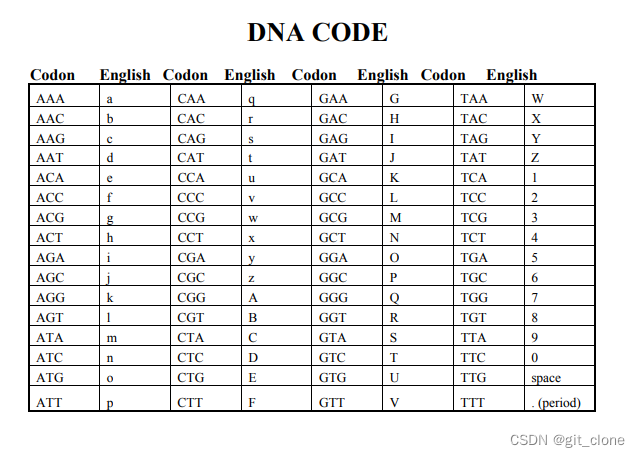
把这些字母写成一个字典,用python跑
import re
# 定义字母表和对应的三联体密码子
dna_code = {
'A': 'CGG', 'B': 'CGT', 'C': 'CTA', 'D': 'CTC',
'E': 'CTG', 'F': 'CTT', 'G': 'GAA', 'H': 'GAC',
'I': 'GAG', 'J': 'GAT', 'K': 'GCA', 'L': 'GCC',
'M': 'GCG', 'N': 'GCT', 'O': 'GGA', 'P': 'GGC',
'Q': 'GGG', 'R': 'GGT', 'S': 'GTA', 'T': 'GTC',
'U': 'GTG', 'V': 'GTT', 'W': 'TAA', 'X': 'TAC',
'Y': 'TAG', 'Z': 'TAT', '1': 'TCA', '2':'TCC','3':'TCG',
'4':'TCT', '5':'TGA','6':'TGC','7':'TGG','8':'TGT','9':'TTA','0':'TTC',
'a': 'AAA', 'b': 'AAC', 'c': 'AAG', 'd': 'AAT',
'e': 'ACA', 'f': 'ACC', 'g': 'ACG', 'h': 'ACT',
'i': 'AGA', 'j': 'AGC', 'k': 'AGG', 'l': 'AGT',
'm': 'ATA', 'n': 'ATC', 'o': 'ATG', 'p': 'ATT',
'q': 'CAA', 'r': 'CAC', 's': 'CAG', 't': 'CAT',
'u': 'CCA', 'v': 'CCC', 'w': 'CCG', 'x': 'CCT',
'y': 'CGA', 'z': 'CGC', ' ': 'TTG'
}
# 输入要解密的 DNA 序列
str=''
dna_string = input("请输入要解密的DNA序列:")
separator_pattern = r"[{}_]"
groups = re.split(separator_pattern, dna_string)
cnt=0
print(groups)
for j in range(len(groups)):
str+=groups[j]
# 将 DNA 序列分成每三个核苷酸一组
codons = [str[i:i+3] for i in range(0, len(str), 3)]
print(codons)
# 将核苷酸三联体对应到字母表中的字符,得到解密后的字符串
decoded_string = ''.join([list(dna_code.keys())[list(dna_code.values()).index(codon)] for codon in codons])
# 输出解密后的字符串
print("解密后的字符串为:", decoded_string)
str=''
自己写脚本的能力有限,不能一次性跑出来,需要手动拼接
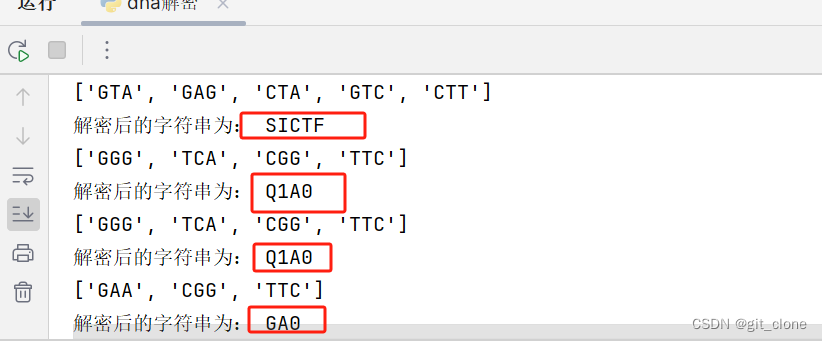















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









