







机器学习课堂笔记(十五)
<matlab>
% Find closest cluster members
idx = findClosestCentroids(X, centroids)
% Essentially, now we have represented the image X as in terms of
% the indices in idx.
% We can now recover the image from the indices (idx) by mapping
% each pixel (specified by it's index in idx) to the centroid value
X_recovered = centroids(idx,:);
% Reshape the recovered image into proper dimensions
X_recovered = reshape(X_recovered, img_size(1), img_size(2), 3);
<matlab>
调用idx=findClosestCentroids(X, centroids)得到
size(X,1)×1
的矩阵
调用X_recovered = centroids(idx,:)得到
size(X,1)×size(X,2)
的矩阵
<matlab>
% Instructions: Compute the projection of the data using only the
% top K eigenvectors in U (first K columns).
% For the i-th example X(i,:), the projection on to the k-th
% eigenvector is given as follows:
% x = X(i, :)';
% projection_k = x' * U(:, k);
<matlab>
调用x = X(i, :)';得到
size(X,2)×1
的列向量
调用projection_k = x' * U(:, k);得到
1×1
的值
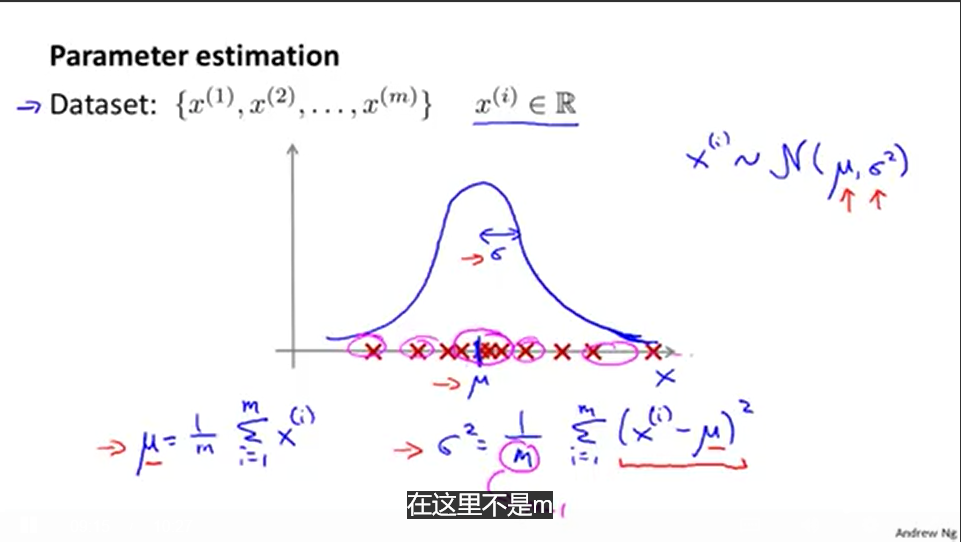
根据样本值计算
μ
和
σ

每个特征值服从不同的高斯分布

设计一种评估算法性能的方法让选择特征更容易

训练样本:交叉验证集:测试集=6:2:2

对于偏斜的数据集:
1、计算真阳性,假阳性,假阴性,真阴性的值
2、计算查准率和召回率
3、计算
F1
积分

使用交叉验证集选择
σ
,然后使用测试集评估算法的性能

对于异常检测:如果异常的种类很多的话,少量的正样本难以学习到所有的异常。未来的异常可能和以前的异常完全不同
对于监督学习:拥有足够的正样本,未来的正样本和训练集中的正样本相似

当拥有大量的正样本和负样本时,异常检测也可以使用监督学习的算法
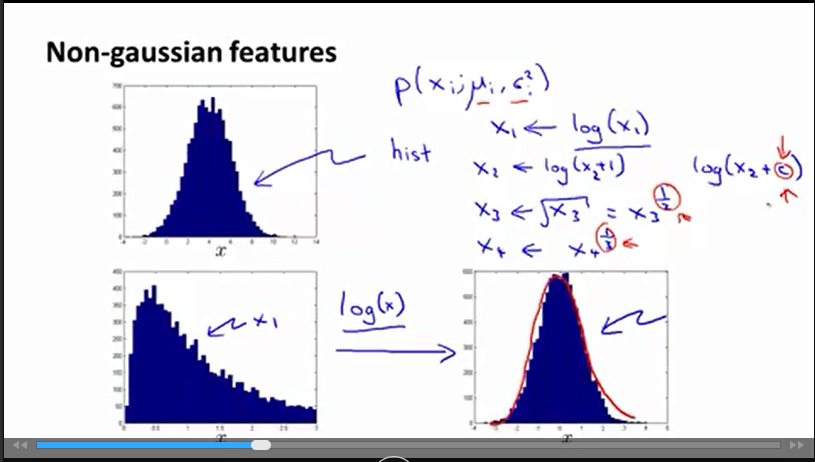
使用hist(x_i)查看
xi
的分布
变换
xi
使其满足高斯分布

寻找算法没能标记的异常点,以此启发创造新的特征变量,从而使其与正常点区分
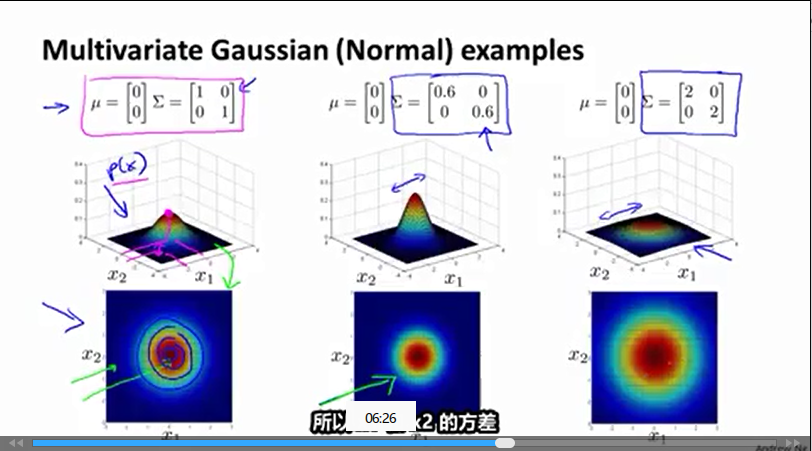
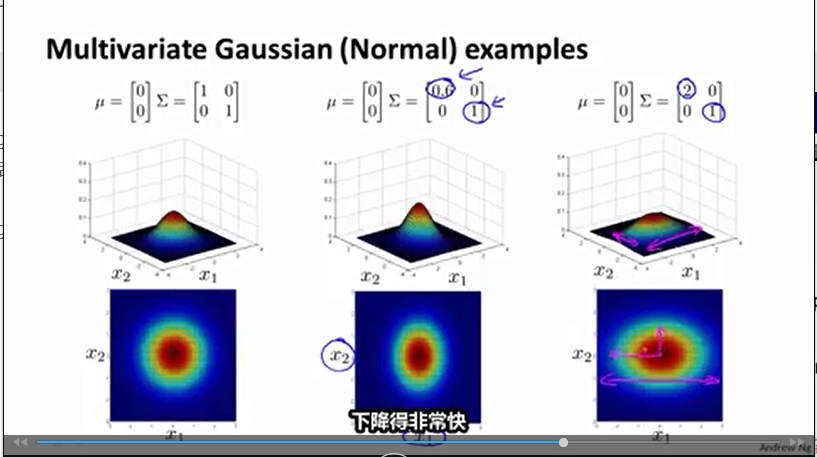
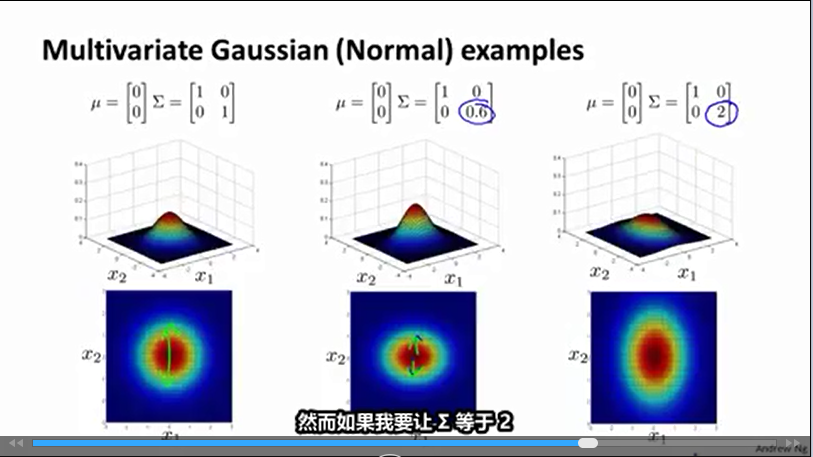
Σ(1,1)
改变
x1
下降速度
Σ(2,2)
改变
x2
下降速度
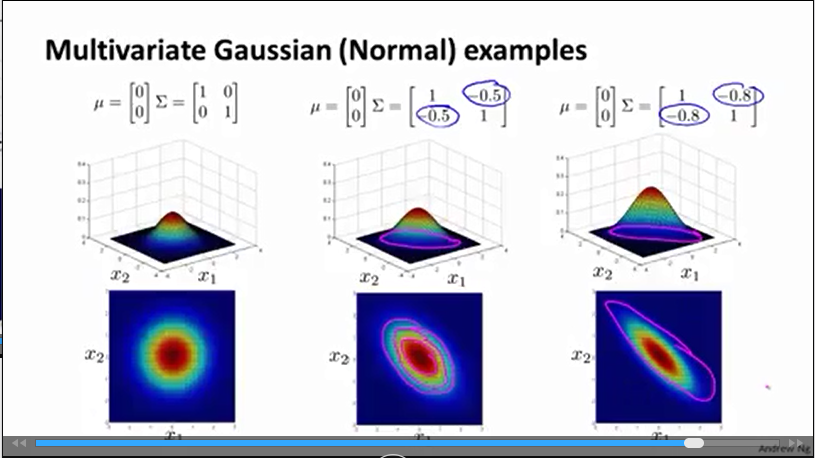
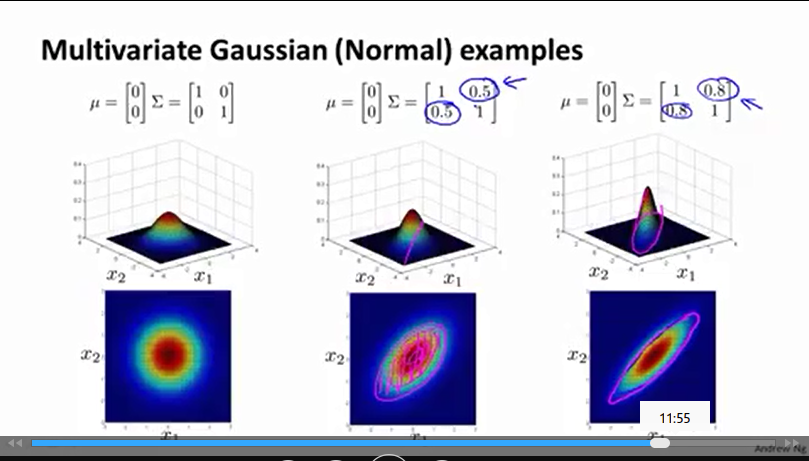
Σ(1,2)
和
Σ(2,1)
改变
x1
和
x2
的相关性
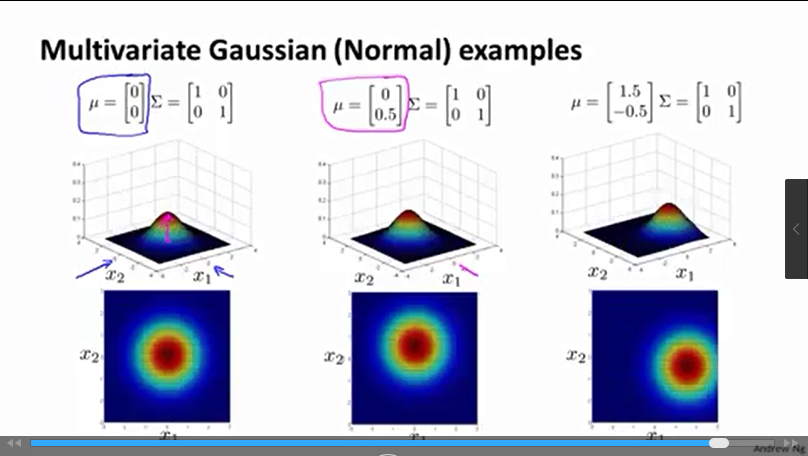
多元分布的中心值为
(μ(1),μ(2))

根据样本值计算
μ
和
Σ

原来的模型是多元高斯模型的一个特例

在m>10n的情况下,使用多元高斯模型能省去手动创造参数来捕捉异常的工作
如果m>n的情况下
Σ
任然不可逆,检查冗余特征变量















 2572
2572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









