







Data Structure
内容基于九章算法课件
(http://www.jiuzhang.com/)
Linear and tree
Linear Data Structure,通常用数组实现
-Queue
-Stack
-Hash
Tree Data Structure,通常用指针
-Tree
Queue : BFS
O(1) Push Pop Top
Stack :
O(1) Push Pop Top
Min Stack
Implement a stack with min() function, which will return the smallest number in the stack.
It should support push, pop and min operation all in O(1) cost.
Notice
min operation will never be called if there is no number in the stack.
Example
Tags
Related Problems
push(1)
pop() // return 1
push(2)
push(3)
min() // return 2
push(1)
min() // return 1
最暴力的解法:
min()的时候for一遍剩下的元素,找到最小的
别担心,勇敢的说,谁的第一反应都是这个。
稍微高级点的解法:
push的时候记录最小值,push+min
-要是加上pop呢?
两个stack,加一个最小值的stack,pop原来的数的时候,也从最小值stack里pop出来一个相应的
题外话
算法要具象化,数据结构也要具象化
栈好像一个大箱子,往里面一本本放书,拿的时候得从最上面的拿。
Implement Queue by Two Stacks
As the title described, you should only use two stacks to implement a queue’s actions.
The queue should support push(element), pop() and top() where pop is pop the first(a.k.a front) element in the queue.
Both pop and top methods should return the value of first element.
Example
push(1)
pop() // return 1
push(2)
push(3)
top() // return 2
pop() // return 2
准备两个stack,stack1和stack2
放stack1里放正了,再倒到stack2里 就倒过来了,push就push倒stack1里,pop要从stack2里pop
题外话:
老师说他比较喜欢数据结构设计的题:
1.加一台机器(带ID)
2.删一台机器(带ID)
3.随机挑一台机器
嗯。。毫无头绪
Largest Rectangle in Histogram
Given n non-negative integers representing the histogram’s bar height where the width of each bar is 1, find the area of largest rectangle in the histogram.
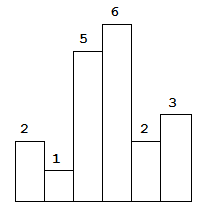
Above is a histogram where width of each bar is 1, given height = [2,1,5,6,2,3].
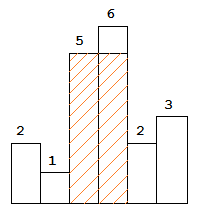
The largest rectangle is shown in the shaded area, which has area = 10 unit.
Example
Tags
Related Problems
Given height = [2,1,5,6,2,3],
return 10.
直接的是
O(n2)
二重循环(枚举,搜索)
如果想提速的话,可以有两种O(nlogn)和O(n)两个可能
nlogn:
- 二分 for(1….到n, 每次logn)
- 排序 nlogn
- heap logn
二分要排序,但是这道题一排序就乱了
核心点:最矮的那根木头
其实就是for每根木头i,向左摆找第一个比他矮的x,再向右找第一个比他矮的y,
算出height[i]*(y-x-1)
此时,引出了一个坑爹的数据形式:
单调栈
单调栈是个找左边第一个的比它小,右边第一个比它小的。
给出一组数据 2 1 5 6 2 3
流程如下:

先把2塞进去,ok, 比1大
把1塞进去,1比2小,把2踢出来,左边没有,右边第一个比它小的是1
把5塞进去,ok, 比1大
把6塞进去,ok,比1和5 都大
把2塞进去,不行了,比5和6小,从和2接近的踢
即把6踢出去,右边第一个比它小的是2,左边第一个比它小的是5
再把5踢出去,右边第一个比它小的是2,左边第一个比它小的是1
把3塞进去再,ok比1,2大
3是最后一个数,之后再塞一个非正整数的-1
即3被踢出来,右边第一个比它小的是-1,左边是2
接着2被踢出来,右边第一个比它小的是-1,左边是1
接着1被踢出来左边无,右边-1
为了更好的理解单调栈,再跑一组数据,这组我们记录左边和右边第一个比它小的数的index:
4,3,2,1,5,6,2

代码如下:
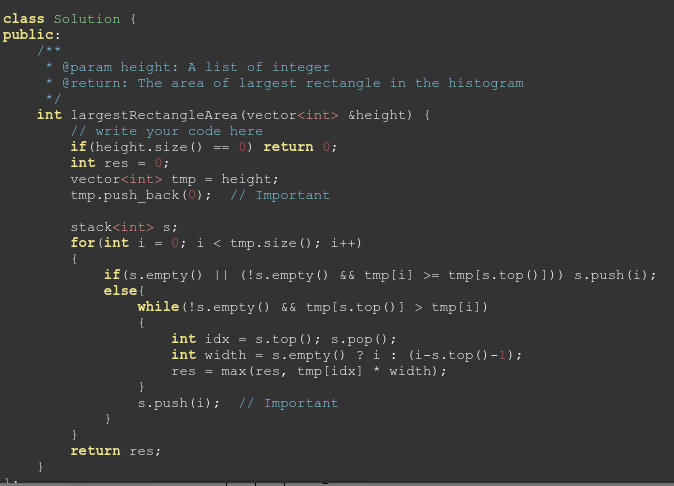
遇到for()里面又套了一个while的这种要小心,乍一看容易觉得时间复杂度是
O(n2)
, 但是平均复杂度很有可能只是O(n).
因为要分析最坏的情况是不是能每次都发生,是不是为了攒一次最坏的情况,要耗费之前很多次之前的。
这种要蓄一波才能发射的,要算平均。
单调栈适合把
O(n2)
变为O(n)。
Maximal Rectangle
Given a 2D boolean matrix filled with False and True, find the largest rectangle containing all True and return its area.
Given a matrix:
[
[1, 1, 0, 0, 1],
[0, 1, 0, 0, 1],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 0, 1]
]
return 6.
对每一行做底,解前面的矩形问题。
Hash table
O(1)的insert,delete和hash
hash table的本质是个大数组,如果hash function设计的好的话,对于一个key值x所对应的数组index,应该没有另一个key值y也指向。
为什么用数组呢,因为A[index]这个操作在数组里面时间复杂度是O(1). 如果用比如linked list之类的,这个操作是O(n)
一般key的值域在0~
232−1
hash key
最简单的是取模,比如key%100
但是如果有一列数101,201,301,401。。那就坑爹了。。。
还有一种md5(key)的hash function,缺点是计算量大。
一般hash function是针对string即char的,因为其它的数据形式都可以转化成char
比如int是4byte的,就是4个char
double是8byte的,就是8个char
如果一个class是{2int加上1double}就可以等同一个8+8的string
貌似好像java下面是每个字节×33+字节对的整数取模,其实也就是转换成33进制,再取模
hash function的设计要求是:越乱越好,越没有规律越好
hash function的collision
open hash table:有collision就存个linked list,拉链法
close hash table:有collision就占下一个坑,占坑法
其中需要注意的是close hash,在删除一个key之后,要标注可用,而不是空位,具体如下:
加入7,3,12三个数字到一个hash function为%5的table里,假设前面一小部分如下:
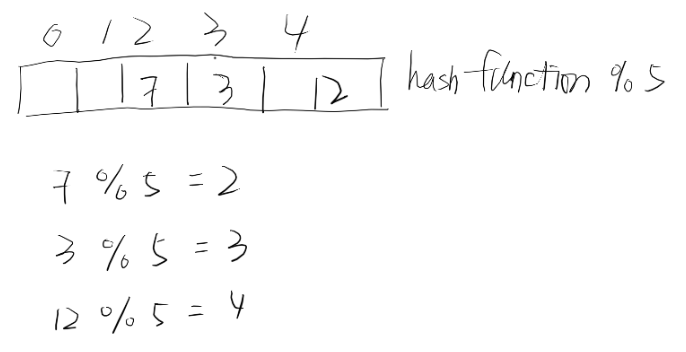
其中7加到index为2的,3加到index为3的,到12的时候,算出来的index是2,但是2已经被占了,所以向后挪一个,去看看3,结果3也被占了,所以12就被塞到了index为4的地方
当删除3的时候,不能直接把index为3的位置直接标空位,而应该标available,这样查询12的时候,会去2找,没有去看3,发现available,知道之前被占过,然后接着向后找
hash table size
size > 0.1capacity
size是实际被占的,如果实际被占的空间超过十分之一,冲突率太高。如果数组需要开的更大,就需要开一个更大的数组,并且把原来的小的copy过去,类似于动态数组,但是很多时候hash function就会变,所以最好不要轻易折腾,举个栗子:
本来有[4,1,2,3]四个数,其中他们的位置按照%4得到的
我们要扩充数组到八个坑,我们开八个坑,要把1,2,3,4挪过去。但是这次1,2,3,4要根据%8来找他们的位置,而不是直接copy过去,所以增加了不少计算量
题外话:
java里面,hash table三个关键字是:
HashTable HashMap 和HashSet
其中 hash table不是thread sage
hash map是thread safe
LRU cache 和LFU cache
cache的原理就是比较hot的条目放速度快的地方存着,评价hot与否的原则是:
LRU: last recent used 时间戳
LFU: last frequent used
其中LRU是必须掌握的:实现方法为doubly linked list+ hashmap
假设一个LRU cache只有三个坑,最近的是
2->1->3
我们现在出现一个新的使用是2 我们要变成
1->3->2
出现了5,变成
3->2->5
heap
支持: add O(logn)时间
delete O(logn)时间
取max/min O(1)时间
heap是个最优二叉树
完全二叉树是增加了限定条件的二叉树。假设一个二叉树的深度为n。为了满足完全二叉树的要求,该二叉树的前n-1层必须填满,第n层也必须按照从左到右的顺序被填满。
并且具有最大或最小的关系特性:
如果是min heap,则父亲要小于所有的儿子。以下插入和删除的操作来源于其它博客,侵删。
——————————————————————
在插入操作的时候,会破坏上述堆的性质,所以需要进行名为sift up的操作,以进行恢复。新插入的节点new放在完全二叉树最后的位置,再和父节点比较。如果new节点比父节点小,那么交换两者。交换之后,继续和新的父节点比较…… 直到new节点不比父节点小,或者new节点成为根节点。这样得到的树,就恢复了堆的性质。
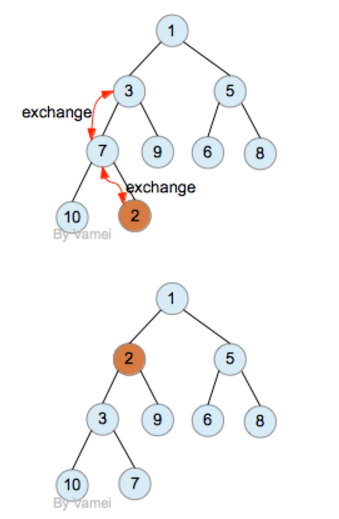
我们插入节点2:
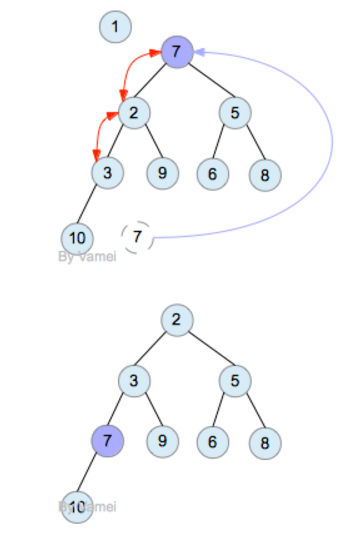
删除操作只能删除根节点。根节点删除后,我们会有两个子树,我们需要基于它们重构堆。进行percolate_down的操作: 让最后一个节点last成为新的节点,从而构成一个新的二叉树。再将last节点不断的和子节点比较。如果last节点比两个子节点中小的那一个大,则和该子节点交换。直到last节点不大于任一子节点都小,或者last节点成为叶节点。
删除根节点1。如图:
——————————————————————
当我们插入或者删除结点的时候, 就是一路换大或者换小,最多换logN次,所以插入或者删除操作的时间复杂度都是O(logn)
priority queque
适合用来解决data stream median 的问题:
Data Stream Median
Numbers keep coming, return the median of numbers at every time a new number added.
Clarification
What’s the definition of Median?
- Median is the number that in the middle of a sorted array. If there are n numbers in a sorted array A, the median is A[(n - 1) / 2]. For example, if A=[1,2,3], median is 2. If A=[1,19], median is 1.
Example
For numbers coming list: [1, 2, 3, 4, 5], return [1, 1, 2, 2, 3].
For numbers coming list: [4, 5, 1, 3, 2, 6, 0], return [4, 4, 4, 3, 3, 3, 3].
For numbers coming list: [2, 20, 100], return [2, 2, 20].
用两个堆, max heap 和 min heap. 维持两个堆的大小相等(max堆可以比min堆多一个). 则max堆的顶即为median值.
hash table 要懂原理,会实现
string的hash table 时间复杂度是O(L),其中L是string的长度
O(key的长度)是hash function的时间复杂度
BFS的实现原理是hash map+ queque, 用到了两个最常用的数据结构,所以非常常考。















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









