






背景
目前我们使用Lambda架构来处理数据,Flink处理实时数据,Spark处理离线数据。Spark离线任务在每天凌晨的0-8点调度执行,在这段时间内,用户是看不到昨日未产出的离线数据的,数据应用对这些未产出的指标进行了特殊处理,用户看到的未产出的指标数据为0或者—。但在没有任何提示的情况下,用户不明白为什么会有这样的情况,给用户带来不好的使用体验。因此,我们需要一套离线数据兜底方案来解决昨日离线数据未产出,导致用户看数体验下降的问题。
目标
通过数据产品功能和数据查询方式上的改进与优化,解决0-8点离线数据未产出问题,降低该问题对用户使用数据的影响。
解决方案
当前在数据应用产品上我们可以看到日周月三个时间粒度的数据,其中,今日数据是实时的,昨日数据是离线的,周和月的数据也是离线的。基于Lambda架构下离线数据和实时数据的特点,为了降低离线数据未产出的问题对用户使用数据带来的影响,我们在数据查询方式和数据产品功能设计上,使用以下三个方案实现离线数据兜底,通过这套离线数据兜底方案,使用户对数据的产出无感知,屏蔽数据产出对用户看数的影响,方案如下:
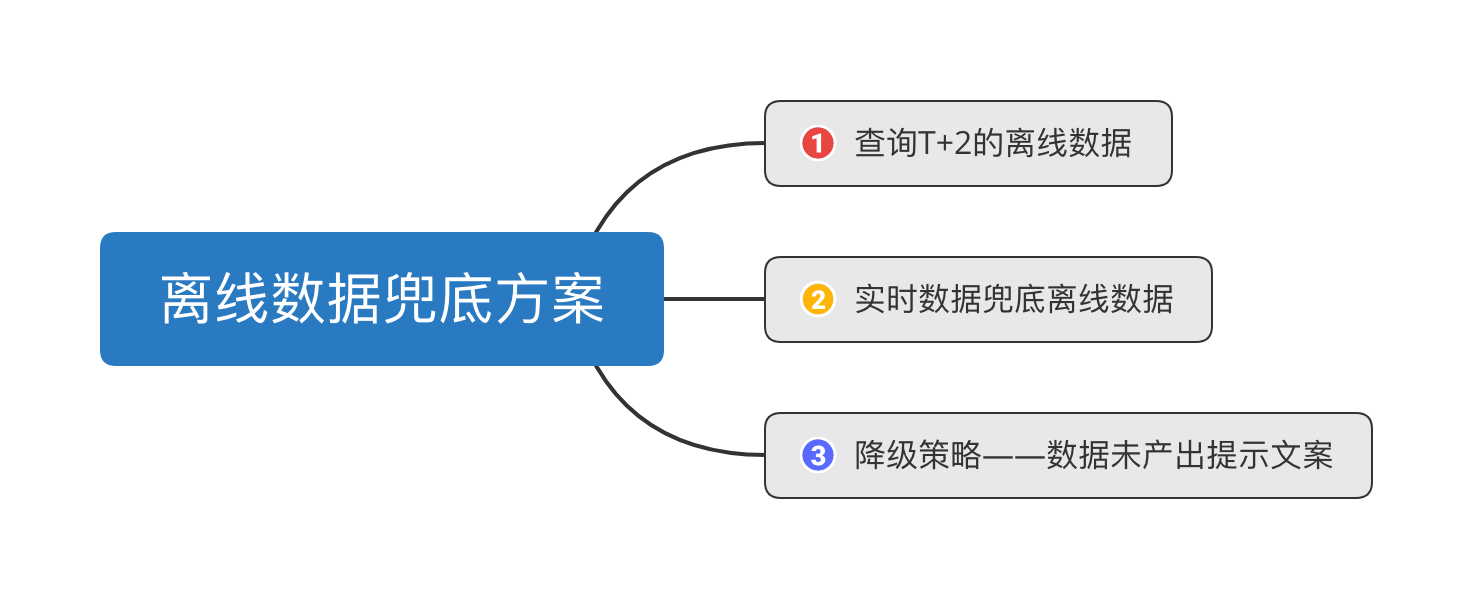
总体上我们使用的是方案2+方案3整合的解决方案。方案1和2属于数据查询方式上的优化,都是为了解决昨日离线数据未产出的问题,在查询方式优化上,我们主要使用的是方案2,方案1属于早期方案,已被废弃。方案3属于数据产品功能上的优化,在产品功能设计上,对于时间粒度为日周月的离线数据,都会考虑加入方案3。
由于用户对数据的使用粘性很高,无论是离线数据还是实时数据,使用上都要求能对数据进行实时查询、实时多维分析。因此,我们选择使用ClickHouse为主、StarRocks为辅的存储架构,这两款OLAP引擎都具备实时OLAP分析的能力,我们会根据实际遇到的问题和场景来选择使用哪一款存储引擎,这两款OLAP引擎对比如下:
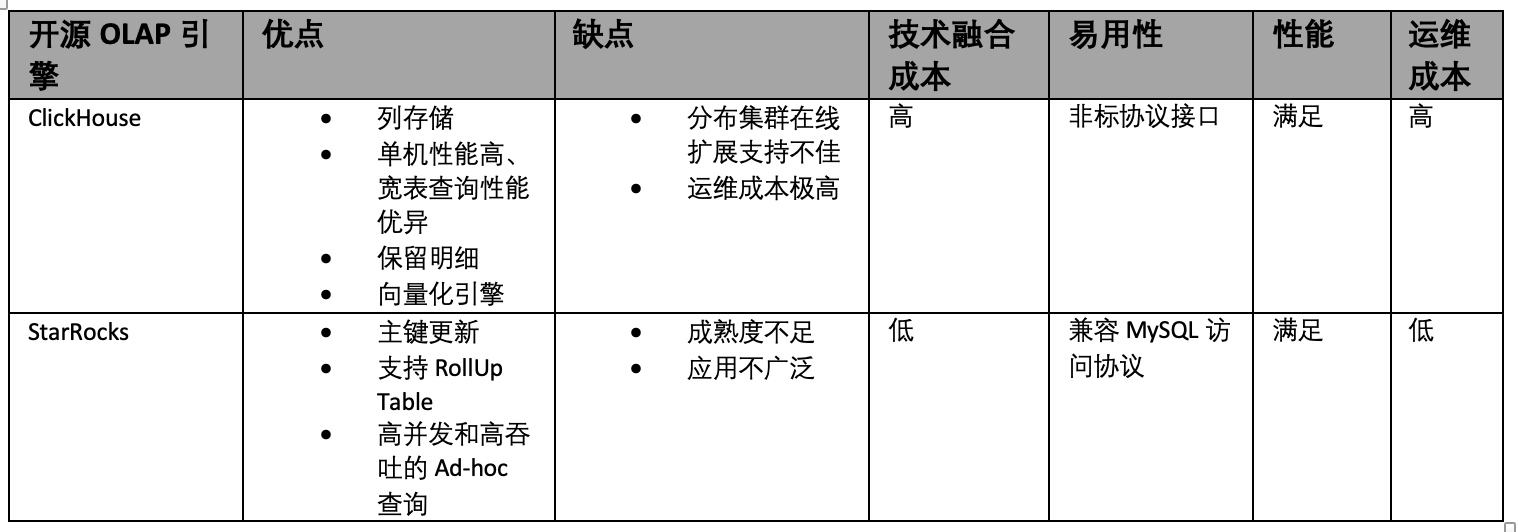
由于方案1比较简单,而且我们不再继续使用,接下来重点介绍方案2和方案3。
实时数据兜底离线数据方案
在Lambda架构中,无论是实时场景还是离线场景,对于同一个指标,它的统计口径都是一样的。在这个前提下,我们利用StarRocks的临时分区、临时分区可以原子替换正式分区的特性,制定了实时数据兜底离线数据方案,方案设计思路如下:
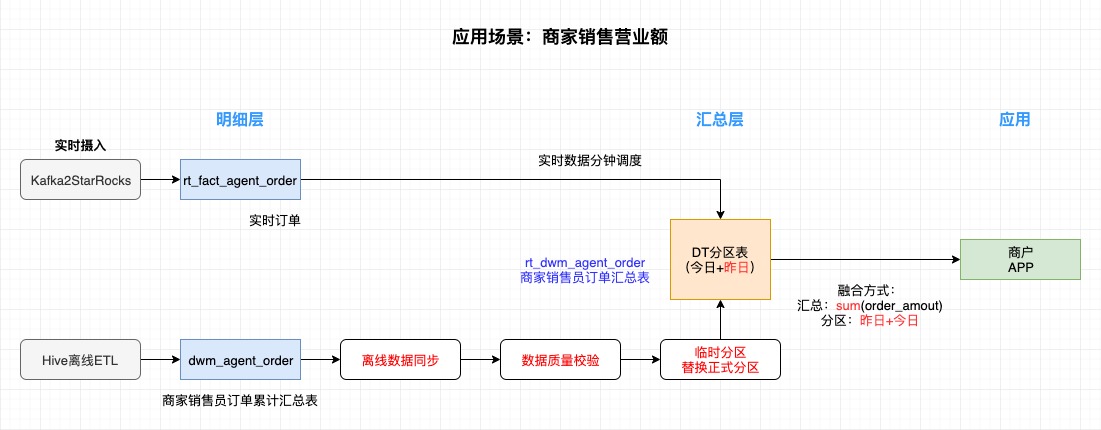
在这个方案中,Hive保存离线数据,StarRocks保存实时数据,StarRocks表的临时分区是实现这个方案的核心,整个方案主要分为三个步骤实现:
1、数据生产: 数据生产分为实时数据链路和离线数据链路,这两条链路产出的数据最终下推到汇总层,数据应用直接从汇总层取数展示给用户。我们以离线任务汇总出的数据为准,数据汇总层的汇总表按天分区,实时任务计算出的汇总数据直接写到汇总表的今日分区里,每天0点过后,今日分区变成昨日分区。
2、分区替换: 这是该方案实现的核心环节,主要分为三步进行:
- (1) 同步Hive离线汇总表数据到StarRocks汇总表临时分区: 一旦离线汇总表的计算任务完成,负责给StarRocks汇总表临时分区同步离线数据的Spark任务就可以将Hive离线汇总表的昨日分区数据同步到StarRocks汇总表临时分区,StarRocks汇总表临时分区的名称与Hive离线汇总表昨日分区的名称一致,比如都是yyyy-MM-dd格式
- (2) 数据质量校验: 第一个步骤完成之后,需要对Hive离线汇总表昨日分区数据与StarRocks汇总表临时分区数据的关键字段、数据行数等指标进行对比,如果两表的分区数据一致,执行第三步的替换操作
- (3) 临时分区替换正式分区: 数据质量检验完成后,在Spark任务里执行StarRocks临时分区替换正式分区脚本,用StarRocks汇总表临时分区的数据覆盖正式分区的数据
3、 数据查询: 数据应用在查询数据时,都可以从StarRocks汇总表去查询
经过以上步骤,就解决了凌晨离线数据未产出,用户不能看到昨日数据的问题。以日时间粒度的数据表为例,实时数据和离线数据都是以0点为分界线,0点过后,实时数据的今日分区变成昨日分区,离线数据的昨日分区的调度任务开始执行,如果用户想要访问昨日的数据,分以下两种情况:
- 当离线数据昨日分区的调度任务未执行完成时,数据应用查询的是实时表昨日分区里未用昨日离线数据替换的汇总数据
- 当离线数据昨日分区的调度任务执行完成,并替换实时表昨日分区的数据之后,数据应用查询的是实时表昨日分区里用昨日离线数据替换后的汇总数据
以上操作都是在数据处理环节完成,对于查看昨日数据的用户,看到的是离线数据还是实时数据,是没有感知的。但最终,用户查看的今日数据还是实时的,今日以前的数据还是离线的,通过昨日离线覆盖昨日实时这一操作,我们将实时数据和离线数据统一存储到一张实时表中,将实时表作为数据的统一出口。
降级策略
降级是在数据应用和业务系统里经常使用的一个策略,比如当用户访问出异常时给用户一个友好的提示,通过这个策略,提升用户的使用体验。
在数据应用层解决离线数据未产出这个问题时,除了使用实时数据兜底离线数据方案,我们也会配合使用数据未产出提示文案的形式给用户提示,减少用户在数据应用产品使用上产生的疑问。在需求、技术评审阶段确认是否需要支持“降级文案“的功能,前端&后端提供管理页面,用来控制文案展示的时间段、文案展示的内容、文案显示的页面,如果遇到数据加工异常可以通过更改文案,提示用户,比如”数据校准中仅供参考,预计6点后更新“的文案,前端会通过在页面上方挂”黄色滚动条“提示用户。
小结&思考
以上方案只是个人在工作实践中的总结,还需要不断完善和改进,后续会考虑在数据处理层使用批流一体架构来统一离线和实时数据,提升数据的产出效率和质量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









