







python 核心数据类型
| 对象类型 | 例子 |
|---|---|
| 数字 | 1234,.1415,+4j,Decimal,Fraction |
| 字符串 | ‘samp’,”guido’s”,b’a\xolc’ |
| 列表 | [1,[2,’three’],4] |
| 字典 | {‘food’:’spam’,’taste’:’yum’} |
| 元组 | (1,’samp’,4,’U’) |
| 文件 | myfile = open(‘egg’,’r’) |
| 集合 | set(‘abc’),{‘a’,’b’,’c’} |
| 其他类型 | None、布尔型 |
| 编程单元类型 | 函数、模块、类 |
| 与现实相关的类型 | 编译的代码堆栈跟踪 |
python在程序中处理的每样东西都是一种对象
数字
math模块包括更高级的数学工具,如函数。而random模块可以作为随机数字的生成器和随机选择器。
import math
import random
print (math.pi)
print(math.sqrt(85))
print(random.random())
print(random.choice([1,2,3,4]))
字符串
字符串能反向索引,从最后一个开始。S[-1]
序列也支持一种所谓的分片(slice)操作,一步就能提取整个分片的方法。一般形式为X[I:J],表示“取出在X中偏移量为I,直到但不包括偏移量为J的内容”
字符串支持用+号进行合并
s = 'spam'
print (s[0])
print (s[-1])
print (s[1:3])
print (s)
s = s + ' lisha'
print (s)
- 不可变性
字符串在python中具有不可变性–在创建后就不能随意的改变,例如:不能通过对其某一位置进行赋值而改变字符串,但是你总是可以通过建立一个新的字符串并以同一个变量名对其进行赋值。因为python在运行过程中会清理旧的对象。
可以用分片的方式
s = 'spam'
s[0] = 2
print (s)s = 'spam'
#s[0] = 2
#print (s)
s = 'z' + s[1:]
print (s)
s = 'a' + s[1:3] + 'b'
print (s)- 特定类型的方法
字符串fing方法是一个基本的子字符串查找的操作,而字符串replace方法将会对全局进行替换。split(通过分隔符将字符串拆分成子串)、upper(字符串变成大写)、isalpha(测试字符串的内容)、rstrip(去掉字符串后的空格字符) 但是,始终注意的是,字符串在python中具有不可变性
字符串还支持一种格式化的高级替代操作,可以以一个表达式的形式和一个字符串的方法调用。
s = 'spam'
print (s.find('pa'))
print (s.replace('pa', 'XYZ'))
line = 'aaa,bbb,ccccc,dd\n'
print (line.split(','))
print (line.upper())
print (line.isalpha())
print (line.rstrip())
print (s, line)
print ('%s, eggs, and %s'%('spam','SPAM!'))
print ('{0}, eggs, and {1}'.format('spam','SPAM!'))- 寻求帮助
以双下划綫开头并结尾的变量名是用来表示python实现细节的命名模式。没有下划线的属性是字符串对象能够调用的方法。dir 和 help 是python文档的首要选择

Python下使用help(dict),显示’more’不是内部或外部命令,也不是可运行的程序或批处理文件,该如何处理?
环境变量设置的问题,进入 Path 的环境变量设置界面,将;%SystemRoot%\system32;加到最后(错误提示的 more 便在该文件夹下)。(%SystemRoot%指的是 C:\Windows)
然后重启 Python 的命令行界面。
编写字符串中单引号与双引号相同
- 模式匹配
import re
match = re.match('/(.*)/(.*)/(.*)','/usr/home/lumberjack')
print (match.groups())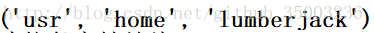
列表
检索的时候与string一致,可以用 len() 、S[0] 、S + [1,2,3]。
- 特定类型的操作
列表没有固定类型的约束,列表没有固定大小,也就是说能顾按照需要增加或者减小列表的大小,来相应其特定的操作。
L = [123, 'spam', 1.23]
print (len(L))
print (L[0])
print (L[-1])
L.append('NI')
print (L)
L.pop(2)
print (L)
L = ['bb', 'aa', 'cc']
L.sort()
print (L)
L.reverse()
print (L)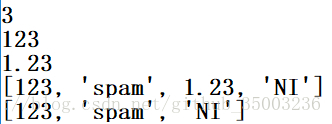
开始直接将 L = [123, ‘spam’, 1.23] 排序与反转。报错,错误的原因如下
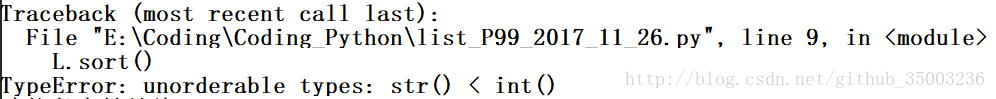
列表支持任意的嵌套。二维数组。
- 列表解析
使用列表解析可以简单的获得到一列
M = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print (M)
print (M[1])
print (M[2][10])
#列表解析
col1 = [row[1] for row in M]
print (col1)
col2 = [row[1]+1 for row in M]
print (col2)
col3 = [row[1] for row in M if row[1] % 2 == 0]
print (col3)
dig = [M[i][i] for i in [0, 1, 2]]
print (dig)
double = [i * 2 for i in 'spam']
print (double)
G = (sum(row) for row in M)
print (next(G), next(G), next(G))
print (list(map(sum,M)))
print ([ord(x) for x in 'spam'])#将字符编程ASCII码
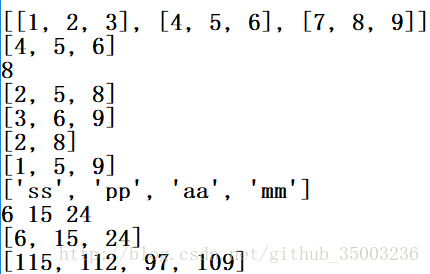
字典
python中的字典完全是不同的东西,他们不是序列,而是一种映射。
映射操作
- 字典编写在大括号中,并包含一系列的“键:值”对。
- 通过键对这个字典进行索引来读取或改变键所关联的值。
D = {'food':'spam','quantity':4,'color':'pink'}


可以用大括号的形式来创建字典,也可以直接通过赋值的方式。
A = {} A['name'] = 'shuai' A['age'] = '22' A['school'] = 'USTB'字典的重访嵌套操作
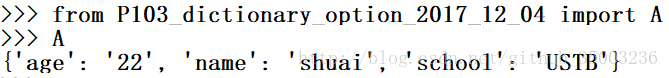
rex = {'name':{'first name':'Lisha','last name':'Shuai'},
'age':'22',
'school':['USTB','NCLG']}
print ('first name:{0}\nage:{1} \nschool:{2}' . format(rex['name']['first name'],rex['age'],rex['school']))
print('school[-1]:%s'%(rex['school'][-1]))
rex['school'].append('JJSZ')
print ('school:%s'%(rex['school']))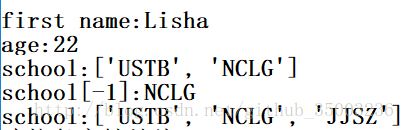
- 建立一个字典,并将它打印出来,它的键也许会与我们输入时顺序不同出现。如果在一个字典元素中,我们确实要强调某种顺序的时候,一个常用的方法通过字典的Keys方法收集一个键的列表,使用列表的sort方法进行排序。
D = {'a':1,'b':2,'c':3}
print (D)
key = list(D.keys())
print (key)
key.sort()
print('key.sort():%s'%(key))
for ke in key:
print (ke,'=>',D[ke])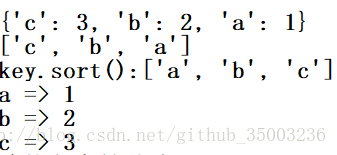
- 通过使用最新的sorted的函数,可以将上面的一步完成。
for ke in sorted(D):
print (ke,'=>',D[ke])元组
- 元组对象(tuple)基本上就像一个不可以改变的列表。
T = (1,2,3,4)
print ('len(T):%s'%(len(T)))
S = T + (5,6)
for data in S:
print(data)
print ('len(T):%s'%(len(T)))
print ('T.index(4):%s'%T.index(4)) #查找4在哪一个位置
print ('T.count(4):%s'%T.count(4)) #查找4出现了几次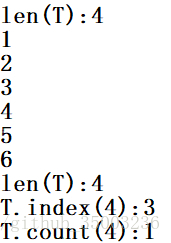
文件
- 文件对象是python代码对电脑上外部文件的主要接口,要创建一个文件对象,需调用内置的open函数以字符串的形式传递给它一个外部文件的名字以及一个处理模式的字符串。
f = open('E:\\Coding\\Coding_Python\\data.txt', 'w') #没有这个文件则创建这个文件
f.write('hello!\n world!') #将字符串写入文件
f.close() #关闭文件,不需要加参数
f = open('E:\\Coding\\Coding_Python\\data.txt', 'r')
text = f.read()
print (text)
print ('text.split():%s'%(text.split()))
f.close()















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









