







- 构造基本抓取页面
# -*- coding:utf-8 -*-
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/1'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason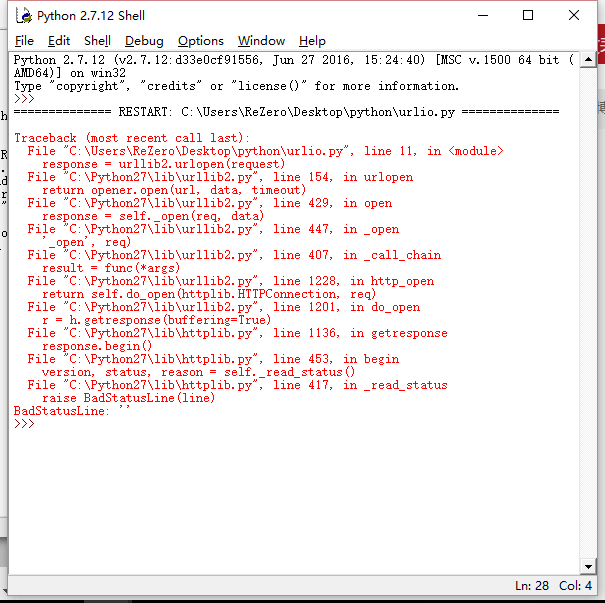
Seem’s magnificent error on it,and I don’t konw what’s they mean….
But if we try to give it a header to be confirmed, just like this
# -*- coding:utf-8 -*-
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/1'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
Then we’ll get the expect answer.
Then I search the error and found that the error we just need to note the last line.
line 373, in _read_status
raise BadStatusLine(line)
httplib.BadStatusLine: ”
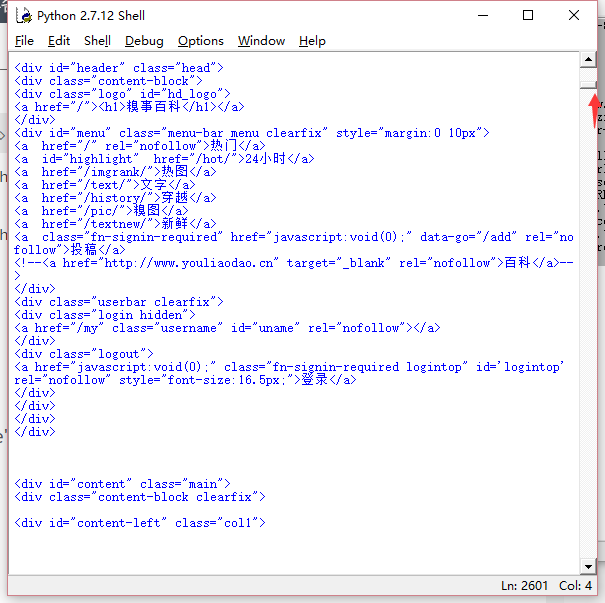
let us find how to get all of the paragraphs in one page.
Firstly, we inspect elements by touch F12, then show the scene like this :
we could see that every paragraph was covered by tag likes
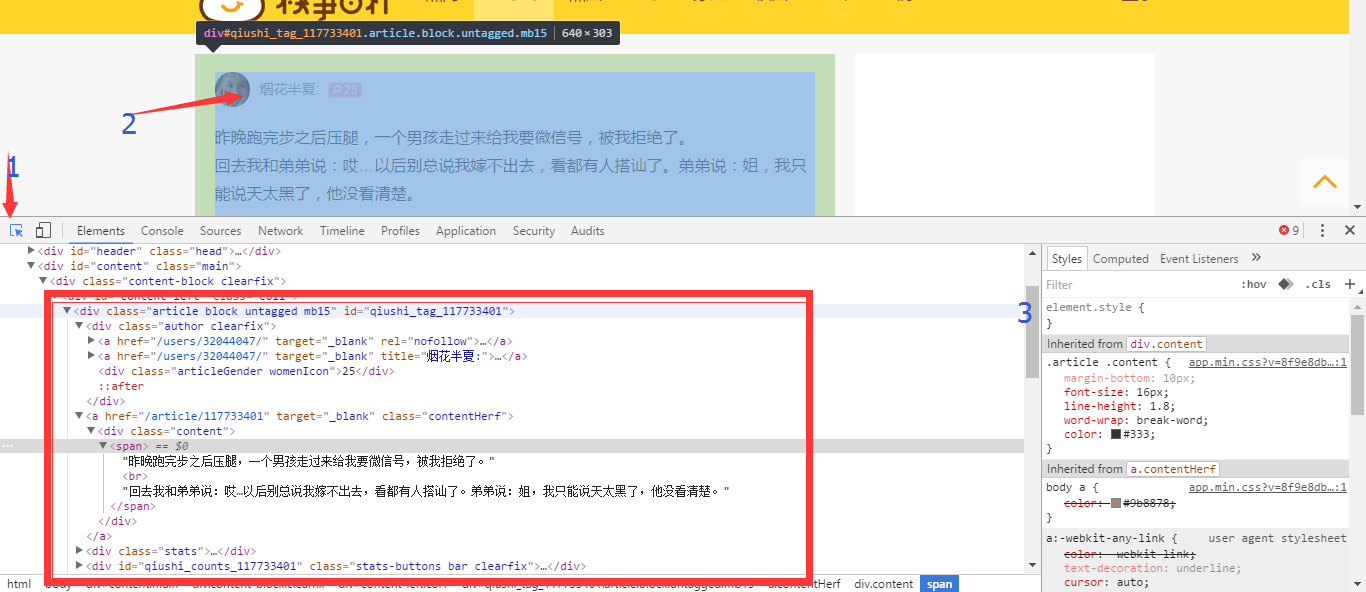
<div class="article block untagged mb15" id="qiushi_tag_117733401" > ... </div>3.Now we want to accquire the publisher, publish date, the content of paragraph, and the number of Zan. But we konw show the picture on consoler is unrealistic, so we rule out the paragraph having picture(What’s the fuck?!!).Year, you are right if you also has thought the method regular expression.And we use the re.findall.
And it shows like this:
content = response.read().decode('utf-8')
pattern = re.compile('<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?'+
'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S)
items = re.findall(pattern,content)
for item in items:
print item[0],item[1],item[2],item[3],item[4]Now we give some instructions:
现在正则表达式在这里稍作说明
1).? 是一个固定的搭配,.和代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2)(.?)代表一个分组,在这个正则表达式中我们匹配了五个分组,在后面的遍历item中,item[0]就代表第一个(.?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
OK, next step we will fliter the picture paragraph
and we could find that those picture paragraph tag more same as this, and normal paragraph without it, so the item[3] gotten is null if it did not have the picture.
<img src="http://pic.qiushibaike.com/system/pictures/11772/117723703/medium/app117723703.jpg" alt="糗事#117723703">
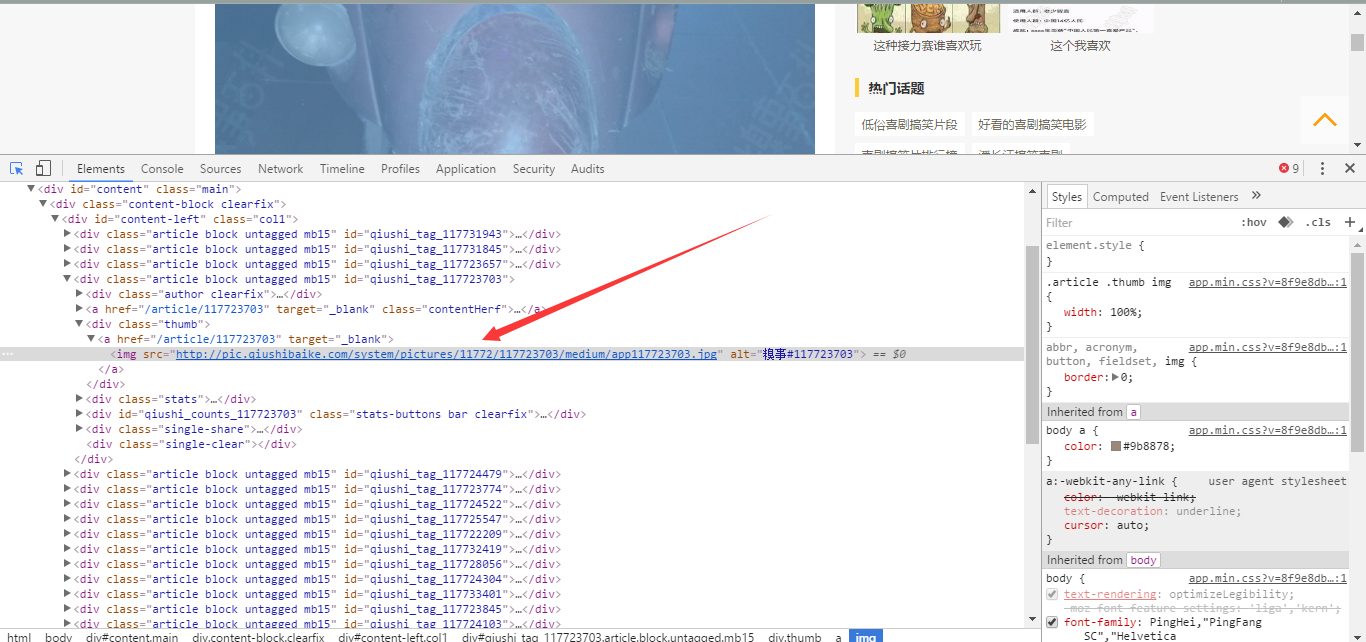
what else, we do some change for our code:
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]So far, we get the code is :
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
pattern = re.compile('<div class="<div.*?clearfix">.*?<h2>(.*?)</h2>.*?"content">(.*?)</div>.*?number">(.*?)</.*?number">(.*?)</.',re.S)
items = re.findall(pattern,content)
for item in items:
print item[0],item[1],item[2],item[3]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
Now, just run it.















 3597
3597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









