







KNN
定义
距离谁近就归谁。
距离分类
距离度量的相关公式:
- 闵可夫斯基距离(Minkowski Distance)
- 欧氏距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
- 切比雪夫距离(Chebyshev Distance)
- 夹角余弦(Cosine)[余弦相似度]
- 汉明距离(Hamming distance)
- 杰卡德相似系数(Jaccard similarity coefficient)
闵可夫斯基距离(Minkowski Distance)
它表示的时一组距离的计算和度量方式。
d 12 = ∑ k = 1 n ( x 1 k − x 2 k ) p p d12 = \sqrt[p]{\sum_{k=1}^{n}(x_{1k}-x_{2k})^{p}} d12=pk=1∑n(x1k−x2k)p
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
欧氏距离(Euclidean Distance)
欧氏距离(L2范数)是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。
二维平面两点的欧式距离即点A(x1,y1)和点B(x2,y2)
d
12
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
2
d12 = \sqrt[2]{(x1-x2)^{2}+(y1-y2)^{2}}
d12=2(x1−x2)2+(y1−y2)2
三维空间两点A(x1,y1,z1)与B(x2,y2,z2)之间的欧式距离
d
12
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
+
(
z
1
−
z
2
)
2
d12 = \sqrt{(x1-x2)^{2}+(y1-y2)^{2}+(z1-z2)^{2}}
d12=(x1−x2)2+(y1−y2)2+(z1−z2)2
两个n维向量A(x11,x12,…x1n)和B(x21,x22,…x2n)的欧式距离:
d
12
=
∑
k
=
1
n
(
x
1
k
−
x
2
k
)
2
d12 = \sqrt{\sum_{k=1}^{n}(x_{1k}-x_{2k})^2}
d12=k=1∑n(x1k−x2k)2
表示为向量运算的方式即为:
d
12
=
(
A
−
B
)
(
A
−
B
)
T
d12 = \sqrt{(A-B)(A-B)^T}
d12=(A−B)(A−B)T
在我们实际运算时,也基本使用的是向量的方式对其进行实现。
实现思路有两种:
"""
描述:
欧式距离的实现
计算公式:SQRT((A-B)*(A-B)^T)
输入:
A向量 B向量
输出:
AB之间的欧式距离
"""
def Euclidean(x1,x2):
distance = np.sqrt(np.dot((x1-x2),np.transpose(x1-x2)))
return distance
def Euclidean2(x1,x2):
distance = np.sqrt(np.sum((x1-x2)**2))
return distance
## 测试
x1 = np.array((4.8,2.2))
x2 = np.array((4.7,2.1))
print(x1,x2)
dist = Euclidean(x1,x2)
dist2 = Euclidean2(x1,x2)
print("dist:{0}_{1}".format(dist,dist2))
曼哈顿距离(Mahattan Distance)
曼哈顿距离的应用场景是滴滴地图、百度地图、高德地图的路线规划中得到广泛应用。这是因为它本身就是计算的街区距离所定位。想想除了大灰机等是可以直线到达,在城市交通中,曼哈顿距离是十分有用。
[外链图片转存失败(img-IFLlNhiV-1563287663970)(https://gss1.bdstatic.com/9vo3dSag_xI4khGkpoWK1HF6hhy/baike/c0%3Dbaike72%2C5%2C5%2C72%2C24/sign=41c86b3a2df5e0fefa1581533d095fcd/8326cffc1e178a8208d61b83f603738da977e82f.jpg)]
二维平面两点的欧式距离即点A(x1,y1)和点B(x2,y2)
d
12
=
∣
x
1
−
x
2
∣
+
∣
y
1
−
y
2
∣
d12 = |x_{1}-x_{2}|+|y_{1}-y_{2}|
d12=∣x1−x2∣+∣y1−y2∣
两个n维度向量之间的曼哈顿距离为
d
12
=
∑
k
=
1
n
∣
x
1
k
−
x
2
k
∣
d12 = \sum_{k=1}^{n}|x_{1k}-x_{2k}|
d12=k=1∑n∣x1k−x2k∣
代码实现如下:
"""
描述:
计算两个向量之间的曼哈顿距离
输入:
和计算Euclidean距离输入参数一致
输出:
AB之间的曼哈顿距离
"""
def Manhattan(x1,x2):
distance =np.sum(np.abs(x1-x2))
return distance
x1 = np.array((4.8,2.2))
x2 = np.array((4.7,2.1))
dist3 = Manhattan(x1,x2)
print("Manhattan Distance:{0}".format(dist3))
切比雪夫距离(Chebyshev Distance)
切比雪夫距离也会用在仓储物流中。数学上使用的是L1距离的最大值。
二维平面两点的欧式距离即点A(x1,y1)和点B(x2,y2)
d
12
=
m
a
x
(
∣
x
1
−
x
2
∣
,
∣
y
1
−
y
2
∣
)
d12 = max(|x_{1}-x_{2}|,|y_{1}-y_{2}|)
d12=max(∣x1−x2∣,∣y1−y2∣)
两个n维向量之间切比雪夫距离为
d
12
=
m
a
x
i
(
∣
x
1
i
−
x
2
i
∣
)
d12 = max_{i}(|x_{1i}-x_{2i}|)
d12=maxi(∣x1i−x2i∣)
代码实现
"""
描述:
计算两点之间的切比雪夫距离(应用仓储物流)
输入:
同上
输出:
输出向量之间的切比雪夫距离
"""
def Chebyshev(x1,x2):
distance = np.max(np.abs(x1-x2))
return distance
dist4 = Chebyshev(x1,x2)
print("Chebyshev Distance{0}".format(dist4))
夹角余弦(余弦相似度 Cosine)
用向量之间的方向差异来衡量样本之间的差异。
在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式
c
o
s
(
θ
)
=
x
1
x
2
+
y
1
y
2
x
1
2
+
y
1
2
x
2
2
+
y
2
2
cos(\theta) = \frac{x_{1}x_{2}+y_{1}y_{2}}{\sqrt{x_{1}^2+y_{1}^2}\sqrt{x_{2}^2+y_{2}^2}}
cos(θ)=x12+y12x22+y22x1x2+y1y2
两个n维样本点A (x11,x12,…,x1n)与 B(x21,x22,…,x2n)的夹角余弦。类似的,对于两个n维样本点A(x11,x12,…,x1n)与 B(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度。
c
o
s
(
θ
)
=
A
B
∣
A
∣
∣
B
∣
cos(\theta) = \frac{AB}{|A||B|}
cos(θ)=∣A∣∣B∣AB
即:
KaTeX parse error: Got function '\sum' as argument to '\sqrt' at position 55: …k}x_{2k}}{\sqrt\̲s̲u̲m̲_{k=1}^{n}x_{1k…
代码显示如下:
"""
描述:
计算向量之间的余弦相似度
输入:
同上
输出:
余弦相似度
"""
def Cosine(x1,x2):
cosV12 = np.dot(x1,x2)/(np.linalg.norm(x1)*np.linalg.norm(x2))
return cosV12
cosinv=Cosine(x1,x2)
print("Cosine:{0}".format(cosinv))
算法
超参数:
不会给算法本身添加优化和求解,只是给算法加相应的规则
1.计算距离
2.排序
3.取与其最近的k个样本
注意:
1.K值选取为奇数
2.K在一般情况下选取在20以内
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 16 19:12:43 2019
@author: Administrator
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
data = pd.read_csv("../data/vehicle.csv")
feature = np.array(data.iloc[:,0:2])
label = data['label'].tolist()
x = np.array(np.arange(data.shape[0]))
y = data.iloc[:,0]
def ShowOriginDataByLabels():
plt.title('Width & Length of different vehicles')
plt.scatter(data['length'][data['label']=="car"],data['width'][data['label']=='car'],c='b',label="car")
plt.scatter(data['length'][data['label']=="truck"],data['width'][data['label']=='truck'],c='r',label="truck")
plt.legend()
def Euclidean(x1,x2):
distance = np.sqrt(np.dot((x1-x2),np.transpose(x1-x2)))
return distance
def CalDistance(x1):
x1 = np.tile(x1,(data.shape[0],1))
diff = x1 - feature
diff = np.sum(diff**2,axis=1)
diff = diff**0.5
return diff
def CalDistance2(x1):
diff=[];
for index in range(feature.shape[0]):
x2 = feature[index,:]
plc = Euclidean(x1,x2)
diff.append(plc)
return diff
def SortData(x1):
data = np.argsort(x1)
return data
def Labels(k):
label_count =[]
classCount={}
for i in range(k):
voteLabel = label[sortIndex[i]]
classCount[voteLabel] = classCount.get(voteLabel,0)+1
label_count.append(voteLabel)
return label_count,classCount
def MostValue(x1):
word_counts =Counter(x1)
top = word_counts.most_common(1)
return top
test = [4.7,2.1]
#1.计算距离
test_return = np.array(CalDistance(test))
test_return2 = np.array(CalDistance2(test))
#2.排序
sortIndex = SortData(test_return2)
#3.设置K值对其进行统计
label_cout,classCount = Labels(9)
#.获取推测值
top =MostValue(label_cout)
print(test_return)
print(test_return2)
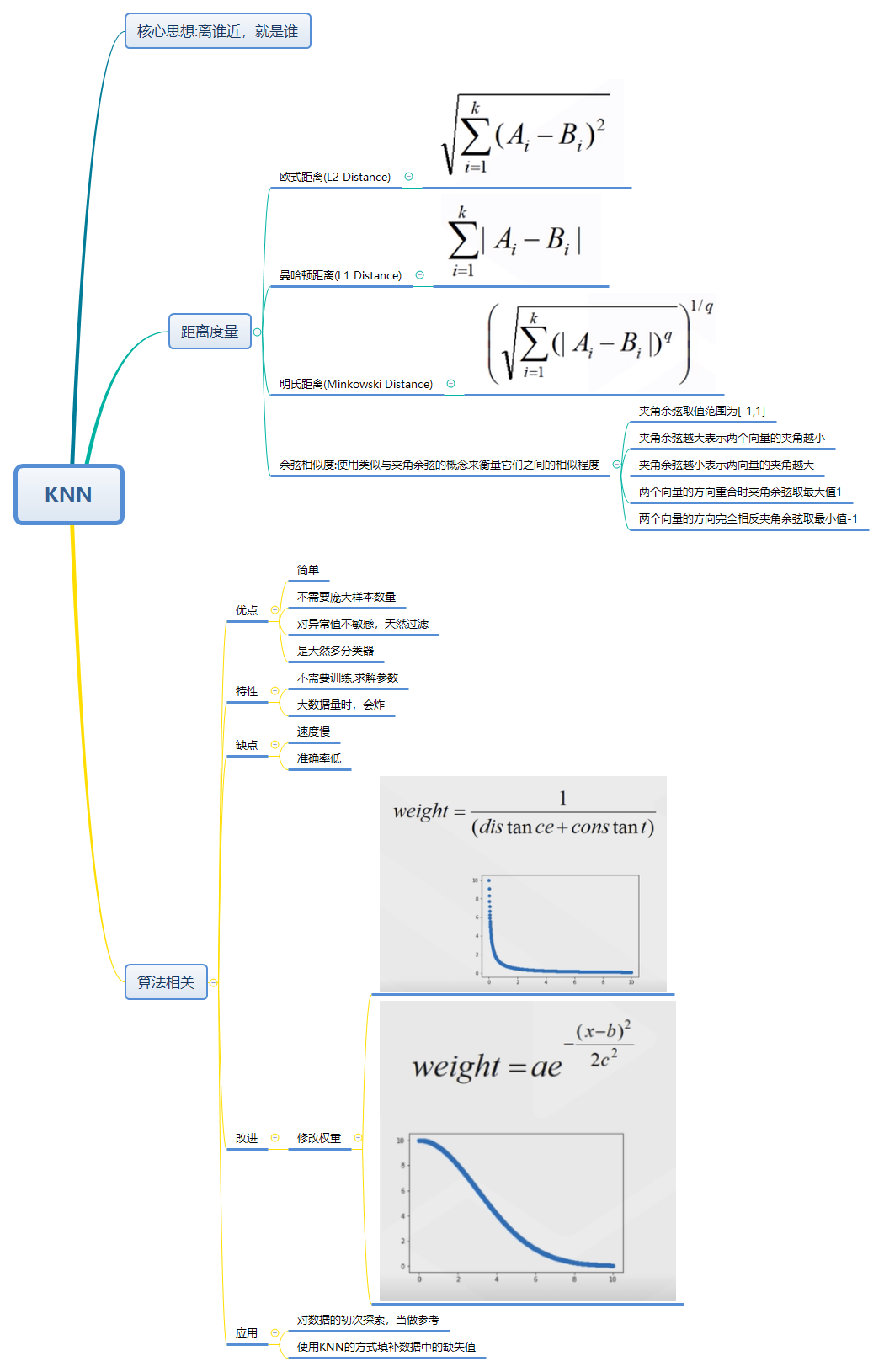
知识思维导图
[外链图片转存失败(img-BGkmljuM-1563287711993)(https://github.com/black-giser/hminl_blog_sets/blob/master/machine_learning/data/Image/KNN.png?raw=true)]
关于我
大家可以star我的笔记库:














 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}