







参考教程:
https://pytorch.org/tutorials/beginner/basics/saveloadrun_tutorial.html
文章目录
训练好的模型,可以保存下来,用于后续的预测或者训练过程的重启。
为了便于理解模型保存和加载的过程,我们定义一个简单的小模型作为例子,进行后续的讲解。
这个模型里面包含一个名为self.p1的Parameter和一个名为conv1的卷积层。我们没有给模型定义forward()函数,是因为暂时不需要用到该方法。假如你想使用这个模型对数据进行前向传播,会返回 “NotImplementedError: Module [Model] is missing the required “forward” function”。
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.t1 = torch.randn((3,2))
self.p1 = nn.Parameter(self.t1)
self.conv1 = nn.Conv2d(1, 1, 5)
net = Model()
pytorch中的保存与加载
首先我们来看一下pytorch中的保存和加载的方法是怎么实现的。
torch.save()
参考文档:https://pytorch.org/docs/stable/generated/torch.save.html
首先来看一下torch.save()函数。
torch.save(obj, f, pickle_module=pickle, pickle_protocol=DEFAULT_PROTOCOL, _use_new_zipfile_serialization=True)
torch.save()函数传入的第一个参数,就是我们要保存的对象,它的类别要求是object,而没有限定在nn.Module()或者nn.Parameters()等等之间。说明它可以保存的类型是多种多样的,很灵活。
传入的第二个参数是f,f是一个file-like object或者文件路径,也就是我们想要保存的位置。
后面的几个参数可以不用管它,一般也不会用到。从参数名称可以看到,我们想要保存的object是以pickle的形式保存的。因为pickle支持多种数据类型。
在源码中给了两个使用torch.save的例子。
>>> # xdoctest: +SKIP("makes cwd dirty")
>>> # Save to file
>>> x = torch.tensor([0, 1, 2, 3, 4])
>>> torch.save(x, 'tensor.pt')
>>> # Save to io.BytesIO buffer
>>> buffer = io.BytesIO()
>>> torch.save(x, buffer)
第一个例子把一个tensor保存在了‘tensor.pt’中,第二个则是将tensor保存在一个buffer中。这都是允许的。
torch.load()
参考文档:https://pytorch.org/docs/stable/generated/torch.load.html#torch.load
再来看一下torch.load()函数。
torch.load(f, map_location=None, pickle_module=pickle, *, weights_only=False, **pickle_load_args)
torch.load()传入的第一个参数f对应着torch.save()中的f,它可以是一个路径,也可以是一个file-like object。
因为我们的模型训练支持cpu也支持gpu等设备,所以我们保存的object也可能处于多种设备环境中,在torch.load()时,这个object会现在CPU上进行反序列化,然后移动到其保存时所处的设备上。假如当前的系统不支持这个设备,就会出现问题,这个时候就需要使用map_location参数,这个参数可以指定你想要放置object的设备,假如没有特别指定,在设备不能实现时就会报错。
weights_only参数可以限定你先要unpickle的object的种类,在使用weights_only参数的同时,你必须明确定义pickle_moduel这个参数(默认为pickle,这也是对的),否则就会报错RuntimeError(“Can not safely load weights when explicit pickle_module is specified”。一般情况下我们也不需要管这个参数。
代码示例
给出一个简单的例子,我们将一个tensor保存在’tensor.pt’中,又使用torch.load()加载进来。

因为保存支持的输入是object,所以我们即使只保存一个字符串也是可以的。(可以,但没必要)

模型的保存与加载
保存 state_dict()
在之前的章节中有说过,调用model.state_dict()方法时,得到的返回结果是一个orderdict,这个字典的key是模型中参数的名字,value是模型的参数值。
我们通常说的保存模型,保存的就是模型的state_dict(),也就是只保存了模型的参数名和参数值,因此我们是不知道模型的正确结构和forward()中的运算顺序的,你也没有办法直接使用这个state_dict()进行预测。
现在我们保存最开始定义的笨蛋小模型的state_dict()
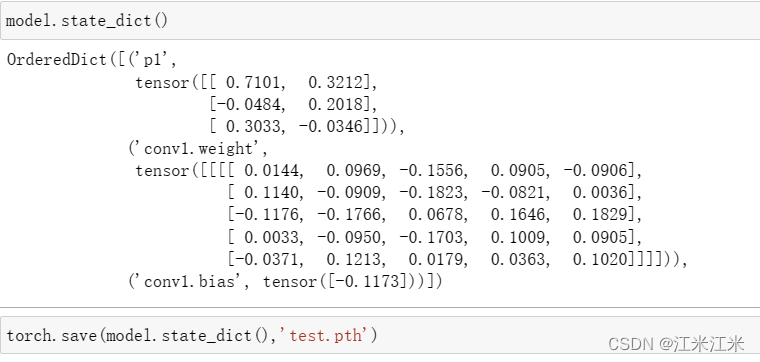
我们只保存了模型的参数名和参数值,这个’test.pth’的大小只有1.39 KB (1,428 字节)。
nn.Module().load_state_dict()
def load_state_dict(self, state_dict: Mapping[str, Any],
strict: bool = True):
load_state_dict()传入的参数是一个key和value的mapping。这里的keys对应的当前模型自己的state_dict的key,或者说参数名。
在使用load_state_dict()时,该方法会对传入的mapping中的key和模型本身的key进行对比。如果key可以匹配上,就会进行一些操作后,更改模型的key对应的参数值。假如没有匹配上,这个key就会被放进missing_keys或者unexpected_keys中去。
strict这个参数默认是True,所以当有不匹配的key时,就会返回报错。
加载模型参数
我们只保存的模型的参数,所以想要使用这个参数,就需要把它放置在一个现有的模型中去。比如说我们现在有一个新模型model2,它和model1有着一样的结构,但是因为初始化的随机性,它们的参数值可能是不一样的。
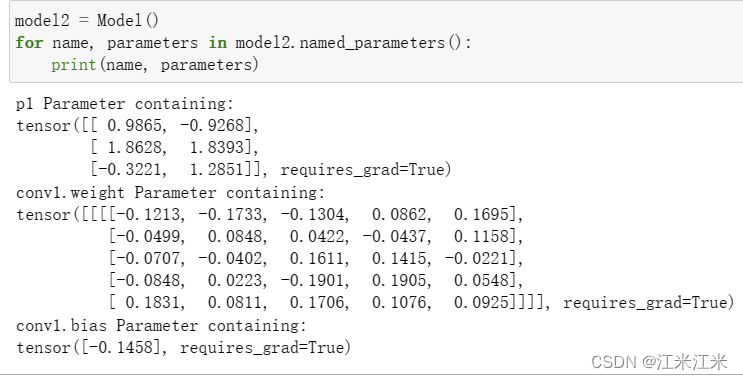
可以看到我们的model2中的参数名和model1一样,但是对应的值不一样。
我们可以使用load_state_dict()方法将model1的参数值根据参数名放到model2中去。
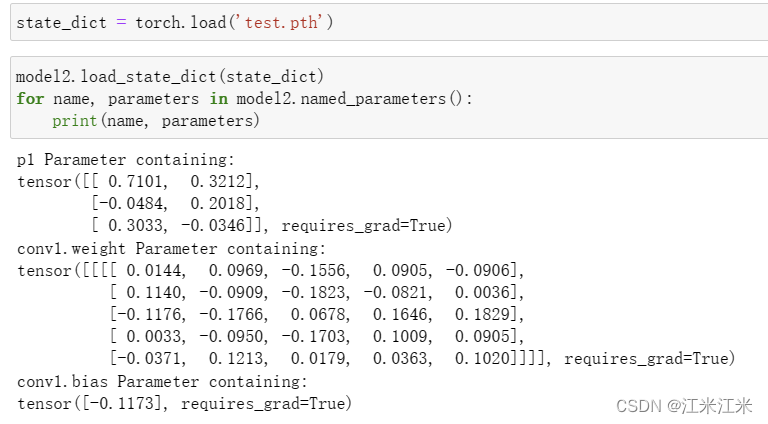
现在model1和model2中的参数值也都变得一样了。
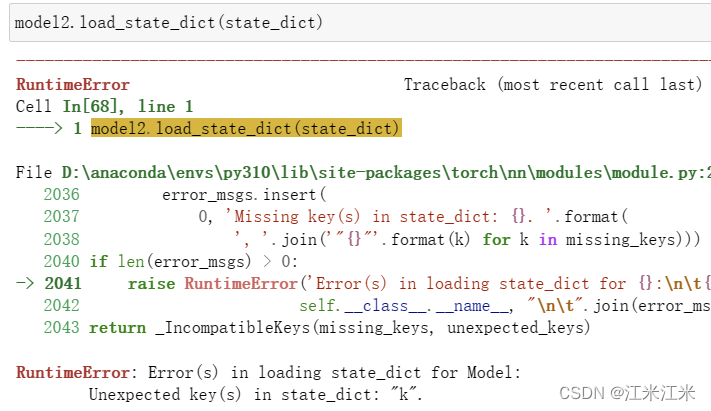
假如我们手动修改一下我们使用torch.load()加载的state_dict,给它增加一个新的值。加载时就会报错,出现了unexpected_keys。相应地,假如给它删除一个值,就会出现Missing key(s) 的错误,在这里不举例子。
保存模型本身
torch.save()支持保存的对象是object,而我们的模型本身,作为nn.Module(),自然也是符合object的要求的。因此你也可以直接保存整个模型。

我们保存的是整个模型,包括了模型的结构和模型的参数名+参数值。这个’test2.pth’的大小是2.39 KB (2,457 字节)。
加载模型本身
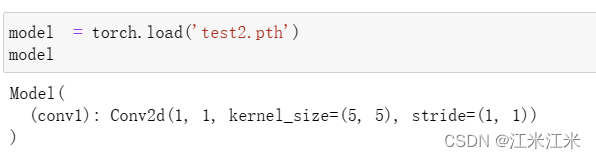
我们在上面将整个模型都保存在了’test2.pth’中,因此我们使用torch.load('test2.pth)时,获得的结果就是模型本身,它的类型是nn.Module()。
checkpoint
保存与读取
假如我们现在有一个保存好的模型’model.pth’,我们想要继续当前模型的状态继续训练。这个时候我们就会发现,'model.pth’中拥有我们模型的参数名和参数值,但是随着我们之前的训练的进行,我们使用的optimizer或者lr_scheluder的状态我们是无法获取的,它们中也有一些参数可能在训练时发生了变化。
因此为了帮助我们重启训练状态,我们需要保存更多的信息,而不是只保存一个模型的state_dict。这些被保存的信息,统称为checkpoint。
在保存checkpoint时,我们同样使用torch.save()方法,在加载时,也是用torch.load()方法。因为torch.save支持保存各种格式,我们可以将想要保存的信息按照key和value组成一个dict,并将这个dict保存下来。
在下面这个例子中,被保存下来的信息包括当前的epoch数,模型的state_dict, 优化器的state_dict还有louss。
# Additional information
torch.save({
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
}, PATH)
在加载时,我们只要按照key取其中的value就可以。
# Additional information
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
多个模型的保存与读取
我们已经知道可以将key和value对应的dict保存成checkpoint的形式,帮助我们重启训练状态。当我们有多个模型时,只不过是增加了要保存到信息而已,方法是一样的。
# Specify a path to save to
PATH = "model.pt"
torch.save({
'modelA_state_dict': netA.state_dict(),
'modelB_state_dict': netB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
}, PATH)
在这个checkpoint中,我们分别保存了modelA和modelB的state_dict,和它们对应的优化器optimizerA和optimizerB的state_dict。
因此在使用时,只要分别放置到对应的object中就可以。
modelA = Net()
modelB = Net()
optimModelA = optim.SGD(modelA.parameters(), lr=0.001, momentum=0.9)
optimModelB = optim.SGD(modelB.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
modelA.eval()
modelB.eval()
# - or -
modelA.train()
modelB.train()















 2911
2911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









