







python爬取B站视频历史弹幕
演示
1.运行程序,输入Bvid和爬取日期。
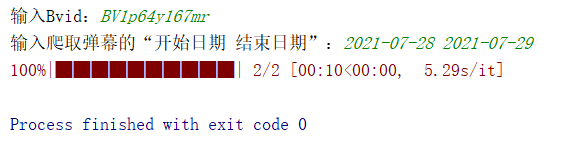
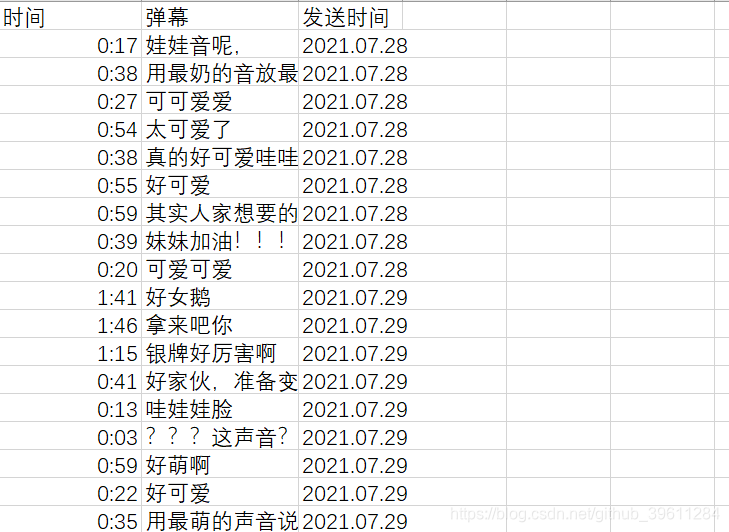
2.程序运行完成后会在当前文件夹下生成一个csv格式文件。
百度网盘链接: https://pan.baidu.com/s/1jhLWjtWlenY4JIdP4w91FA
提取码: hjm5
完毕~
由于本人不经常上CSDN,刚看到大家的问题 抱歉~
根据大家的问题,通过检查代码运行状况,发现在解析弹幕ProtoBuf格式中会产生错误,所以更新一下了代码,在此贴一下代码供大家学习参考:)
在爬取弹幕中需要用到两个py文件:Bztm_pb2.py和B站爬取弹幕.py(需放在同一个文件夹下)
Bztm_pb2.py的作用是为解析弹幕seg.so文件提供支持,它的代码是通过Protoc生成的,代码太多了就不粘贴代码了 (下载链接: https://pan.baidu.com/s/1BSTp-96VlCi5XZApfZELjA 提取码: 2ess )
B站爬取弹幕.py的作用就是下载弹幕文件->解析文件->保存为csv文件,代码如下:
import requests
import re
from Bztm_pb2 import DmSegMobileReply
import json
from google.protobuf.json_format import MessageToJson
import csv
import os
import datetime
from tqdm import tqdm
import time
'获取弹幕api:https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=252900431&date=2021-05-20'
orgin_url='https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={}&date={}'
#获取cid
def get_cid(bvid):
video_url = 'https://www.bilibili.com/video/' + bvid
page = requests.get(video_url, headers=header).text
cid = re.search(r'"cid":[0-9]+', page).group()[6:]
return cid
#生成日期序列
def create_assist_date(datestart = None,dateend = None):
# 创建日期辅助表
if datestart is None:
datestart = '2016-01-01'
if dateend is None:
dateend = datetime.datetime.now().strftime('%Y-%m-%d')
# 转为日期格式
datestart=datetime.datetime.strptime(datestart,'%Y-%m-%d')
dateend=datetime.datetime.strptime(dateend,'%Y-%m-%d')
date_list = []
date_list.append(datestart.strftime('%Y-%m-%d'))
while datestart<dateend:
# 日期叠加一天
datestart+=datetime.timedelta(days=+1)
# 日期转字符串存入列表
date_list.append(datestart.strftime('%Y-%m-%d'))
return date_list
#获取日期输入
def get_dates():
des=input('输入爬取弹幕的“开始日期 结束日期”:')
dates=des.split()
date_list=create_assist_date(dates[0],dates[-1])
return date_list
#时间戳转换成日期
def get_time(ctime):
timeArray = time.localtime(int(ctime))
otherStyleTime = time.strftime("%Y.%m.%d", timeArray)
return str(otherStyleTime)
#时间戳转换成时间
def get_time2(t):
t1 = float(t)/1000
t2 = time.localtime(t1)
t3 = time.strftime("%M:%S", t2)
return t3
if __name__=='__main__':
##第一个运行软件创建设置文件
f_path = os.getcwd()
fnames = os.listdir(f_path)
if 'cookie.init' not in fnames:
cookie= input('请输入cookie:')
with open(r'cookie.init', 'w+', encoding='utf8') as f:
f.writelines(cookie)
f.close()
else:
with open(r'cookie.init', 'r', encoding='utf8') as f:
cookie = f.readline()
f.close()
header = {
'accept': '*/*',
'Cookie': cookie,
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'origin': 'https://www.bilibili.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
bvid=input('输入Bvid:')
cid = get_cid(bvid)
dates=get_dates()
fname = bvid + '_弹幕.csv'
with open(fname, 'w+', newline='', encoding='utf_8_sig') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["时间","弹幕", "发送时间"])
for ditem in tqdm(dates):
url=orgin_url.format(cid,ditem)
try:
html = requests.request(url=url, method='get', headers=header)
except:
print(ditem,':爬取获取数据失败')
continue
DM = DmSegMobileReply()
DM.ParseFromString(html.content)
data_json = json.loads(MessageToJson(DM))
for i in data_json['elems']:
try:
ctime = get_time(i['ctime'])
message = i['content']
ptime = get_time2(i['progress'])
except:
continue
csv_writer.writerow([ptime, message, ctime])
time.sleep(5)
f.close()
运行效果如下:

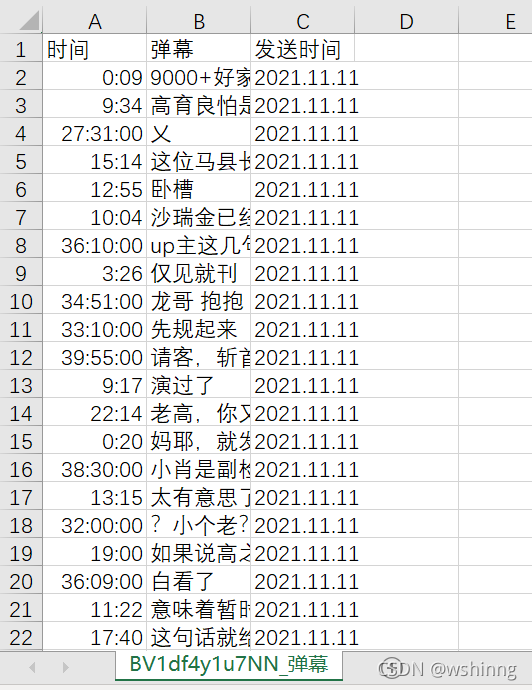
完整的代码下载如下:
链接: https://pan.baidu.com/s/1AHOxKA8ymddwXuBE3b0m5A
提取码: x774
完毕~
















 6061
6061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











