







一、编写MapReduce程序,读取hdfs上的结构化文件,将其写入到HBase表中
package hbase.operate.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* Created by Administrator on 2017/3/7.
*/
public class LoadData {
public static class LoadDataMapper extends Mapper<LongWritable,Text,LongWritable,Text>{
private Text out = new Text();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMDDHHmms");
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String [] splited = line.split("\t");
String formatedDate = simpleDateFormat.format(new Date(Long.parseLong(splited[0].trim())));
String rowKeyString = splited[1]+":"+formatedDate;
out.set(rowKeyString+"\t"+line);
context.write(key,out);
}
}
public static class LoadDataReducer extends TableReducer<LongWritable,Text,NullWritable>{
public static final String COLUMN_FAMILY = "cf";
@Override
protected void reduce(LongWritable key, Iterable<Text> values, Reducer<LongWritable, Text, NullWritable, Mutation>.Context context) throws IOException, InterruptedException {
for (Text tx : values) {
String[] splited = tx.toString().split("\t");
String rowkey = splited[0];
Put put = new Put(rowkey.getBytes());
put.add(COLUMN_FAMILY.getBytes(), "raw".getBytes(), tx
.toString().getBytes());
put.add(COLUMN_FAMILY.getBytes(), "reportTime".getBytes(),
splited[1].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "msisdn".getBytes(),
splited[2].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "apmac".getBytes(),
splited[3].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "acmac".getBytes(),
splited[4].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "host".getBytes(),
splited[5].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "siteType".getBytes(),
splited[6].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "upPackNum".getBytes(),
splited[7].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "downPackNum".getBytes(),
splited[8].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "upPayLoad".getBytes(),
splited[9].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "downPayLoad".getBytes(),
splited[10].getBytes());
put.add(COLUMN_FAMILY.getBytes(), "httpStatus".getBytes(),
splited[11].getBytes());
context.write(NullWritable.get(), put);
}
}
}
public static void createHBaseTable(String tableName) throws IOException {
HTableDescriptor htd = new HTableDescriptor(
TableName.valueOf(tableName));
HColumnDescriptor col = new HColumnDescriptor("cf");
htd.addFamily(col);
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "bigdata.apache.com");
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
System.out.println("table exists, trying to recreate table......");
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
System.out.println("create new table:" + tableName);
admin.createTable(htd);
}
public static void main(String[] args) throws Exception {
// args = new String[] { "hdfs://bigdata.apache.com:8020/input/hbase" }; --打jar包提交集群运行,自由指定输入文件
Configuration conf = HBaseConfiguration.create();
// conf.set("hbaser.rootdir","hdfs://bigdata:8020/hbase");
conf.set("hbase.zookeeper.quorum", "bigdata.apache.com");
conf.set(TableOutputFormat.OUTPUT_TABLE, "phone_log");
createHBaseTable("phone_log");
Job job = Job.getInstance(conf, "LoadData");
job.setJarByClass(LoadData.class);
job.setNumReduceTasks(1);
// 3.2 map class
job.setMapperClass(LoadDataMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
// 3.3 reduce class
job.setReducerClass(LoadDataReducer.class);
// job.setOutputKeyClass(NullWritable.class); --不需要设置
// job.setOutputValueClass(Mutation.class); --不需要设置
Path inPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inPath);
job.setOutputFormatClass(TableOutputFormat.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}二、打成jar包(仅包含当前的.classpath,不包含依赖的所有jar文件),并指定主类
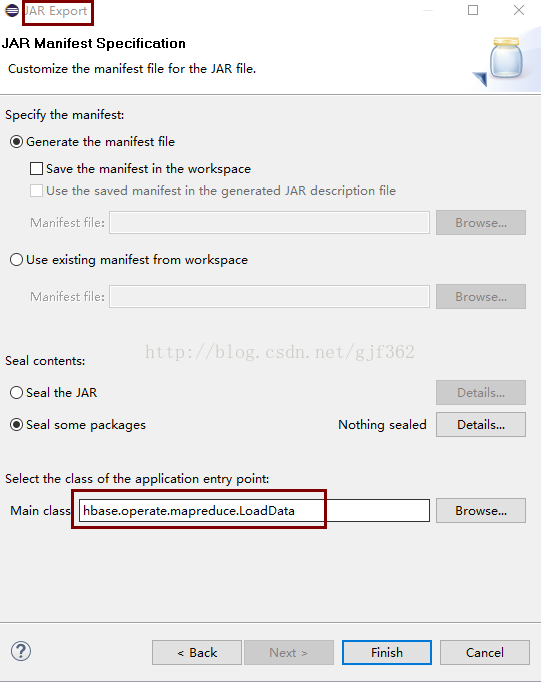
三、在${HADOOP_HOME}/etc/hadoop/hadoop-env.sh中增加HADOOP_CALSSPATH的指向--运行mapduce集成HBase需要HBase的jar包,这里指向了全部jar包
## mapreduce integrate hbase
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/*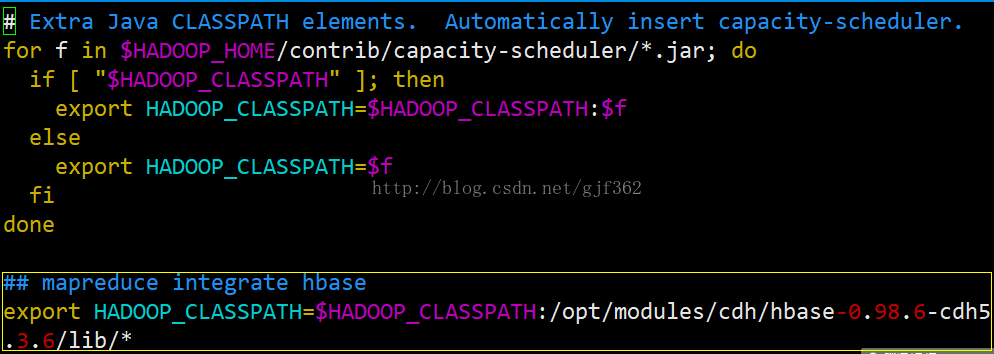
四、运行jar包,并指定输入文件
$ bin/yarn jar ~/hbasemp.jar /input/hbase
报错
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:538)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:197)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:299)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:81)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 1参考网上的处理信息
hadoop执行hbase插入表操作,出错:Stack trace: ExitCodeException exitCode=1:(xjl456852原创) - 三杯两盏淡酒 - 博客园
http://www.cnblogs.com/xjl456852/p/5763765.html
在${HADOOP_HOME}/etc/hadoop/yarn-site.xml文件,添加以下配置信息
<property>
<name>yarn.application.classpath</name>
<value>
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6etc/hadoop/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/lib/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/lib/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/hdfs/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/hdfs/lib/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/yarn/*,
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/yarn/lib/*,
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/*
</value>
</property>














 9346
9346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









