







前言
一、K-近邻算法是什么?
简而言之,k-近邻算法就是采用测量不同特征值之间的距离方法进行分类。
k-近邻算法的工作原理:
存在一个样本数据集合(训练样本集),在样本集当中的每个数据都存在标签,即我们知道样本集中每一个数据与其所属分类的对应关系。在输入无标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后通过算法提取出样本集中特征最为相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法当中k的由来,通常k为不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
举例说明:
当k=3时,距离最近的3个样本为2个红色三角形与1个蓝色正方形,因此将它归类为红色三角形
当k=5时,距离最近的5个样本为2个红色三角形与3个蓝色正方形,因此将它归类为蓝色正方形
k-近邻算法的优缺点:
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度高,空间复杂度高
适用数据范围:数值型和标称型
k-近邻算法的一般流程:
(1)收集数据:可以使用任何方法
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式
(3)分析数据:可以使用任何方法
(4)训练算法:此步骤不适用于k-近邻算法
(5)测试算法:计算错误率
(6)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理
一、实验介绍
该实验通过k-近邻算法改进约会网站的配对效果,通过该算法帮助海伦寻找适合自己的约会对象。该实验的主要过程如下所示:
(1)收集数据:提供文本文件
(2)准备数据:使用python解析文本文件
(3)分析数据:使用matplotlib画二维扩散图
(4)训练算法:此步骤不适用于k-近邻算法
(5)测试算法:使用海伦提供的部分数据作为测试样本。测试样本和非测试样本的区别在于:测试样本是已完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
(6)使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
二:实验过程:
1.数据准备
在该实验当中,我们所用到的为书本提供的海伦数据集,该数据集存放在文本文件datingTestSet2.txt中,每个样本数据占据一行,共有1000行,同时样本包含了以下三种特征:
1.每年获得的飞行常客里程数
2.玩视频游戏所耗时间百分比
3.每周消费的冰淇淋公升数
若要将这些特征数据输入到分类器当中,则需先将处理数据的格式改变为分类器可接受的格式。因此,我们先要创建file2matrix函数以处理输入格式问题。通过该函数将文件名字符串输出为训练样本矩阵和类标签向量。
def file2matrix(filename): #将文本记录转换为NumPy的解析程序
fr = open(filename)
arrayOLines = fr.readlines() #获得文件行数
numberOfLines = len(arrayOLines)
returnMat = zeros((numberOfLines,3)) #创建返回的NumPy矩阵
classLabelVector = []
index = 0
for line in arrayOLines: #解析文件数据到列表
line = line.strip() #strip: 用来去除头尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
listFromLine = line.split('\t') #使用tab字符将整行数据分割成一个元素列表
returnMat[index,:] = listFromLine[0:3] #选取前3个元素存入矩阵当中
classLabelVector.append(int(listFromLine[-1])) #将列表的最后一列存储到向量classLabelVector中
index+=1
return returnMat,classLabelVector
通过上述代码可以看出,我们首先要得出文件的行数,再创建矩阵numpy,然后循环处理文件中的每行数据,用strip函数截取掉所有的回车字符,然后使用tab字符将整行数据分割成一个元素列表,再选取前3个元素并存储到特征矩阵当中,然后通过负索引将列表的最后一列存储到向量classLabelVector中,但同时要注意列表中存储的元素为整型,防止python语言将这些元素当作字符串处理。
2.分析数据
该部分我们使用matplotlib创建散点图,代码如下所示:
import matplotlib
import matplotlib.pyplot as plt
from pylab import mpl
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2])
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.xlabel('玩视频游戏所含时间百分比',fontsize=10)
plt.ylabel('每周消费的冰淇淋公升数',fontsize=10)
plt.show()
在创建散点图时,我们需要导入相应的包,同时在设置xy坐标轴名称时,我们还需设置字体,否则坐标轴上的文字无法显示,只会以方格形式显示。
所得散点图:
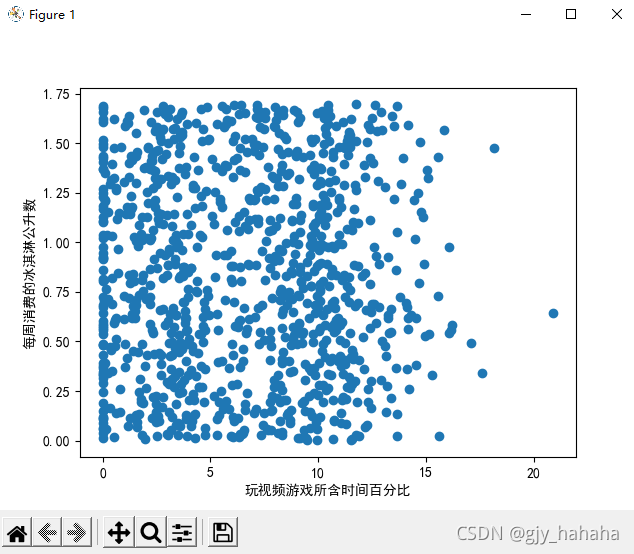
通过上图所示,我们可以看出散点图使用的数据分别表示’玩视频游戏所耗时间百分比‘以及’每周所消费的冰淇淋公升数‘,但由于没有使用样本分类的特征值,因此很难看到任何有用的数据模式信息,这时我们可以采用记号来标记不同样本分类。可以通过scatter函数来个性化标记散点图上的点。ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2],15.0*array(datingLabels),15.0*array(datingLabels))
标记后的散点图如下所示:
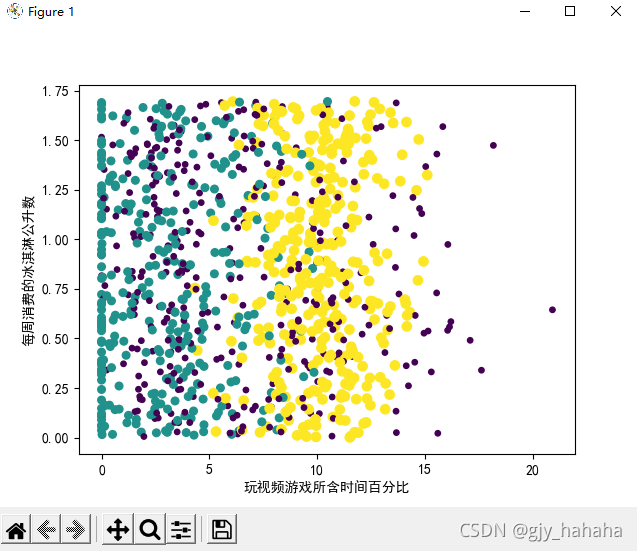
虽然该图已能够较容易的区分数据点从属类别,但采用矩阵的第一和第二列属性可以得到更好的展示效果,即’每年获取的飞行常客里程数‘与’玩视频游戏所耗时间百分比‘这两个特征,所得散点图如下所示:
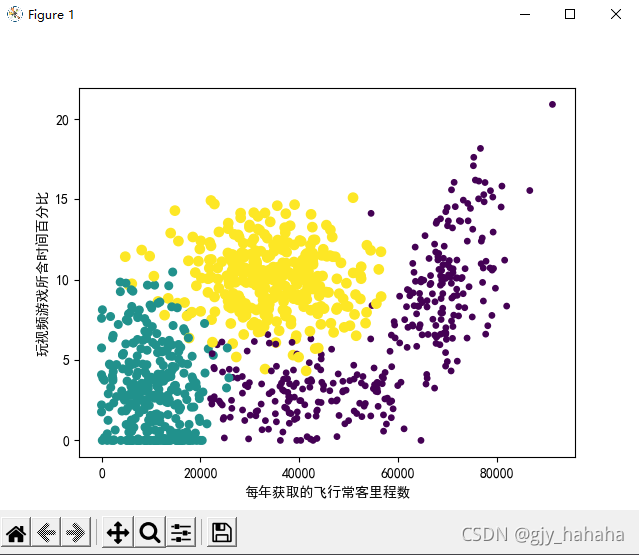
3.归一化数值
在计算样本之间的距离时&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









